Clear Sky Science · de
Ein dualer Deep-Learning-Ansatz zur kontinuierlichen Erkennung von Gebärdensprache zur Verbesserung der Kommunikationszugänglichkeit in der Region Ha’il
Die Kommunikationslücke überbrücken
Für viele gehörlose Menschen ist die Gebärdensprache das wichtigste Kommunikationsmittel, doch die meisten Computer, Telefone und öffentlichen Dienste können sie noch nicht verstehen. Dieser Beitrag stellt ein neues KI-System vor, das kontinuierliches Gebärden in Videoaufnahmen beobachtet und genauer in geschriebene Worte überführt. Indem es nicht nur Handbewegungen, sondern auch Kopfposition und Mimik berücksichtigt, zielt das System darauf ab, technologiegestützte Kommunikation natürlicher und zugänglicher zu machen – insbesondere für gehörlose Gemeinschaften in der Region Ha’il in Saudi-Arabien, wo digitale Unterstützung noch begrenzt ist. 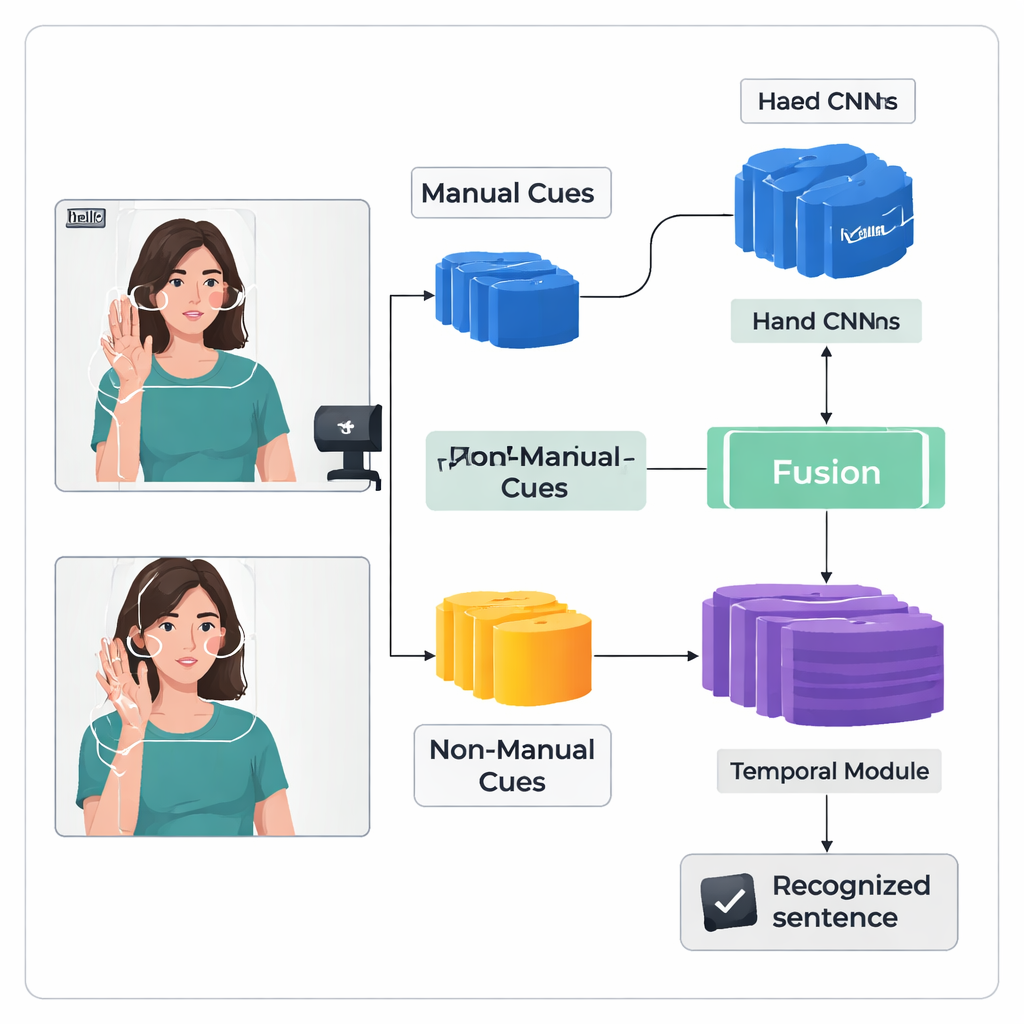
Warum Hände allein nicht ausreichen
Gebärdensprachen sind reiche, komplexe Systeme, die den gesamten Oberkörper nutzen. Bedeutung entsteht nicht nur durch die Handbewegungen, sondern auch durch Gesichtsausdrücke, Blickrichtung sowie Neigen oder Nicken des Kopfes. Diese Signale außerhalb der Hände können Fragen, Verneinungen, Betonung oder Emotionen kennzeichnen. Menschen erfassen all dies mühelos, doch die meisten computergestützten Systeme zur Gebärdenspracherkennung konzentrieren sich nahezu ausschließlich auf die Hände. Diese Vereinfachung macht das Training leichter, führt aber dazu, dass wichtige Hinweise verloren gehen, besonders wenn Gebärden in schnellen, kontinuierlichen Sätzen ineinander übergehen statt als isolierte Wörter vorzuliegen.
Zwei parallele Ströme
Die Autoren stellen ein „Dual-Stream“-Deep-Learning-Framework namens TS-CNN vor, das Hände und Kopf getrennt verarbeitet und anschließend zusammenführt. Ein Strom fokussiert auf zugeschnittene Bilder der Hände des Gebärdenden und lernt Muster von Form, Bewegung und Position. Der andere Strom erhält eine kompakte Darstellung von Gesicht und Kopf, abgeleitet aus Landmark-Punkten und Kopfhaltungsschätzungen. Beide Ströme nutzen einen standardisierten Typ von Vision-Netzwerk, um jeden Videoframe in numerische Merkmale zu überführen. Das System fusioniert diese Merkmale frameweise und berücksichtigt dabei, dass Hand- und Kopfhinweise zur gleichen Zeit im realen Gebärden auftreten. Ein späteres temporales Modul betrachtet viele Frames, um zu verstehen, wie Gebärden sich über die Zeit entfalten, und eine rekurrente Schicht erzeugt eine Sequenz vorhergesagter Gebärdeneinheiten, sogenannte Glosses.
Das Gedächtnis für Gebärden schärfen
Die Erkennung kontinuierlicher Gebärden ist schwierig, weil Trainingsdaten begrenzt sind und Gebärden ohne klare Frame-für-Frame-Labels verschwimmen. Um dem zu begegnen, fügen die Autoren ein Feature-Enhancement-Modul hinzu, das dem Netzwerk während des Trainings zusätzliche Anleitung gibt. Eine weit verbreitete Technik richtet die vorhergesagte Gloss-Sequenz mit dem Video aus und liefert wahrscheinliche zeitliche Positionen für jedes Gloss. Das neue Modul nimmt diese Ausrichtungs-Vorschläge und nutzt sie als direkte Aufsicht, um die interne Darstellung der Gloss-Merkmale zu verfeinern. Einfach ausgedrückt lernt das System nicht nur, die richtige Sequenz auszugeben, sondern auch klarere, konsistentere interne „Erinnerungen“ daran aufzubauen, wie jede Gebärde in verschiedenen Videos aussieht.
Erprobung des Ansatzes
Das Team bewertet TS-CNN an zwei bekannten Gebärdensprach-Datensätzen: RWTH-PHOENIX-Weather 2014 für Deutsche Gebärdensprache und CSL Split II für Chinesische Gebärdensprache. Die Leistung wird mit der Wortfehlerrate gemessen, einer üblichen Metrik ähnlich der in der Spracherkennung. Im Vergleich zu einer Basisversion, die nur Handbewegungen betrachtet, reduziert die Hinzunahme von Kopfhaltungsinformationen die Fehler um etwa 4 Prozentpunkte bei den deutschen Daten und 3–4 Punkte bei den chinesischen Daten. Die Ergänzung durch das Feature-Enhancement-Modul bringt noch größere Verbesserungen und senkt die Fehler insgesamt um etwa 10–14 Prozent in beiden Datensätzen. Das System läuft zudem effizient und erreicht Echtzeitgeschwindigkeiten auf einer modernen Grafikprozessor-Einheit, was entscheidend ist, falls es in Live-Dolmetschdiensten oder mobilen Anwendungen eingesetzt werden soll. 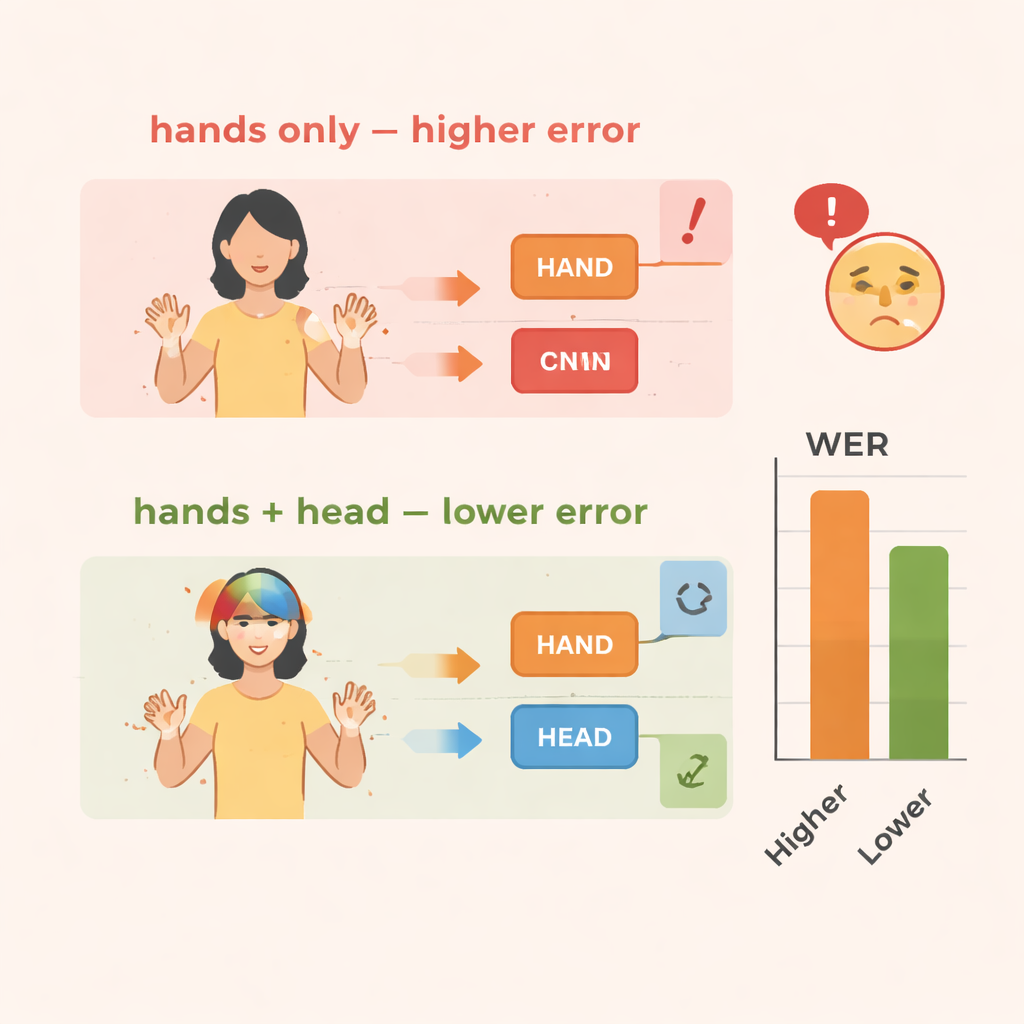
Was das für den Alltag bedeutet
Praktisch zeigt diese Forschung, dass Computer Gebärdensprache zuverlässiger verstehen können, wenn sie die gesamte gebärdende Person beobachten und nicht nur die Hände. Indem Kopfbewegungen und Mimik neben Handbewegungen modelliert und das Lernen aus begrenzten Trainingsdaten sorgfältig verfeinert wird, rückt das TS-CNN-Framework näher an praxistaugliche Systeme heran, die gehörlosen Menschen in Klassenzimmern, Krankenhäusern und öffentlichen Ämtern helfen könnten. In Regionen wie Ha’il, wo menschliche Dolmetscher rar sind und Technologieprojekte noch im Aufbau sind, könnte ein solches System langfristig inklusivere Kommunikation unterstützen – und so die Lücke zwischen Gebärdenden und der hörenden Welt verringern, ohne die reichhaltige, menschliche Erfahrung des Gebärdens selbst zu ersetzen.
Zitation: Harrouch, H., Guesmi, H., Alalfy, H. et al. A dual-stream deep learning framework for continuous sign language recognition to enhance communication accessibility in the Ha’il region. Sci Rep 16, 7070 (2026). https://doi.org/10.1038/s41598-026-38912-x
Schlüsselwörter: Gebärdenspracherkennung, Deep Learning, Barrierefreiheit, Computer Vision, Mensch–Computer-Interaktion