Clear Sky Science · de
Eine Methode zum Schutz von Datenprivatsphäre für Vorhersagemodelle infektiöser Krankheiten mit ausgewogener Trainingsgeschwindigkeit und Genauigkeit
Warum der Schutz von Gesundheitsdaten weiterhin wichtig ist
Kliniken und Gesundheitsbehörden verlassen sich inzwischen auf Künstliche Intelligenz, um Ausbrüche von Grippe, COVID-19 und anderen Infektionen Tage oder Wochen im Voraus vorherzusagen. Diese Prognosen können Impfkampagnen, Personalplanung und Notfallmaßnahmen steuern. Dieselben detaillierten Patientenakten, die Vorhersagen genau machen, sind jedoch auch extrem sensibel. Gesetze und öffentliche Bedenken verhindern häufig, dass Daten über Einrichtungen hinweg zusammengeführt werden, was die Leistungsfähigkeit dieser Modelle schwächt. Dieser Beitrag stellt eine Methode vor, mit der hochwertige Vorhersagesysteme für Infektionskrankheiten trainiert werden können, während die Daten jeder Klinik sicher vor Ort verbleiben.
Von vielen Krankenhäusern lernen, ohne Patientenakten zu teilen
Die Autorinnen und Autoren bauen auf einer Technik namens Federated Learning auf, bei der mehrere Krankenhäuser gemeinsam ein geteiltes Vorhersagemodell trainieren. Anstatt rohe Patientenakten auf einen zentralen Server zu kopieren, trainiert jede Einrichtung das Modell lokal und sendet nur numerische Aktualisierungen an die internen Einstellungen des Modells zurück. Ein zentraler Server kombiniert diese Updates und verteilt das verbesserte Modell erneut. Diese Schleife wiederholt sich viele Male. Theoretisch schützt Federated Learning die Privatsphäre, weil persönliche Informationen das Gebäude nie verlassen. In der Praxis können jedoch geschickte Angreifer mitunter aus den geteilten Updates Details über die zugrunde liegenden Daten erschließen, sodass zusätzliche Schutzmaßnahmen nötig sind. 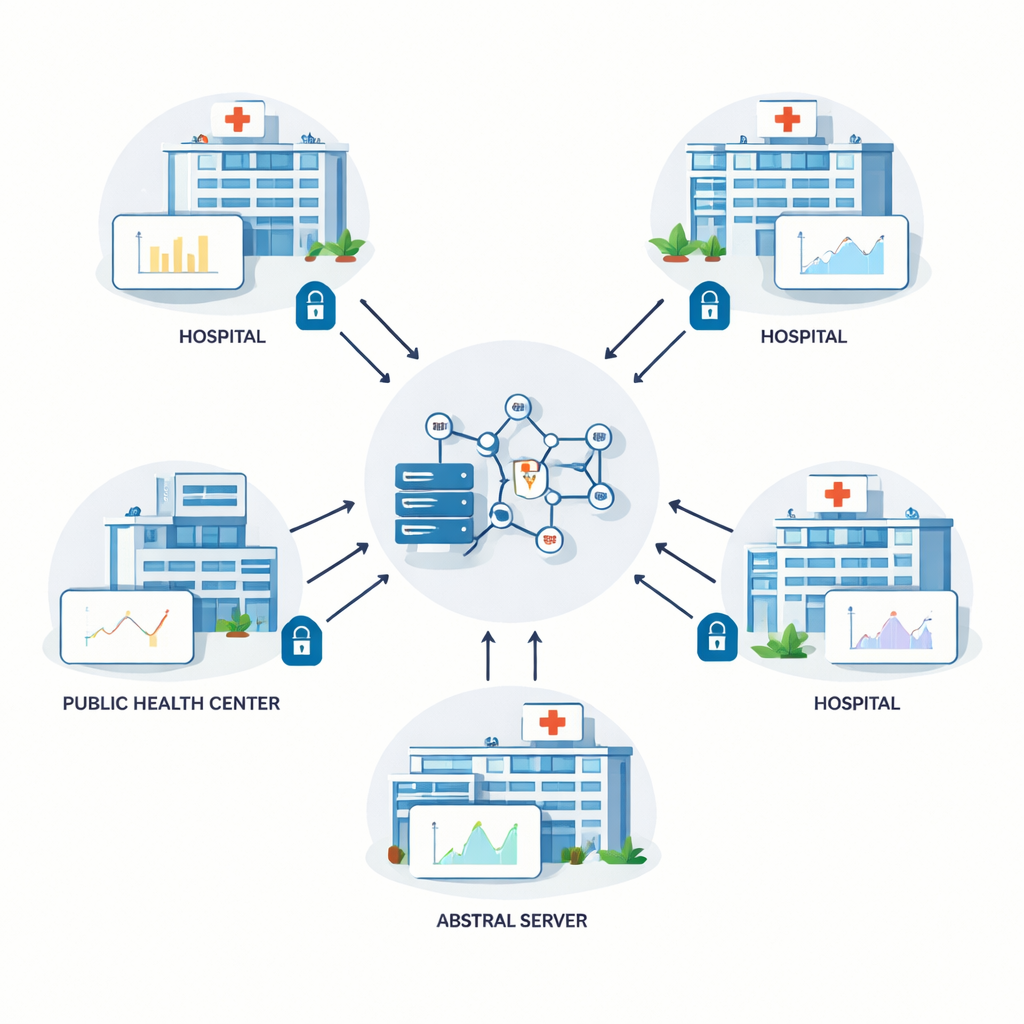
Die Zahlen mit intelligenter Verschlüsselung abschließen
Um die Sicherheit zu erhöhen, nutzt das Team homomorphe Verschlüsselung – eine Form digitaler Sperre, die Berechnungen direkt auf verschlüsselten Zahlen erlaubt, ohne sie jemals im Klartext zu sehen. Traditionelle Verfahren dieser Art sind sehr sicher, aber notorisch langsam und ressourcenintensiv, wodurch sie schwer mit großen, komplexen Modellen wie solchen auf Basis von Long Short-Term Memory (LSTM)-Netzwerken einsetzbar sind. Die Forschenden entwerfen ein hybrides Schema, das unterschiedliche Teile des Modells unterschiedlich behandelt. Die am meisten aufschlussreichen Komponenten werden mit einer starken, aber schweren Verschlüsselung geschützt, während weniger sensitive Teile eine leichtere, schnellere Sperre nutzen. Darüber hinaus entscheidet ein vorgeplanter Zufallszeitplan, in welchen Trainingsrunden Einrichtungen tatsächlich verschlüsselte Updates senden, sodass redundante Kommunikation übersprungen werden kann. Tests zeigen, dass diese Kombination das Training gegenüber dem überall eingesetzten schweren Verschlüsselungsmodus um etwa 25 Prozent beschleunigt, während die Daten unter starken kryptografischen Annahmen geschützt bleiben.
Nur die wirklich relevanten Updates senden
Selbst mit intelligenterer Sperre ist es Zeit- und bandbreitenaufwändig, jede noch so kleine Modelländerung zwischen den Einrichtungen hin- und herzuschicken. Die Autorinnen und Autoren schlagen daher eine neue Trainingsregel namens Data Selection–Distributed Selection Stochastic Gradient Descent (DS-DSSGD) vor. Während des Trainings misst der Algorithmus, wie stark sich jeder Teil des Modells von einem Schritt zum nächsten ändert. Nur Updates, die einen voreingestellten Schwellenwert überschreiten, werden übertragen; kleine, wenig wirkungsvolle Änderungen werden einfach ignoriert. Gleichzeitig verfolgt der Algorithmus, welche Datenpunkte für die größten, informationsreichsten Änderungen verantwortlich sind. Diese einflussreichen Datensätze werden zu einem verfeinerten Datensatz zusammengestellt, der für eine abschließende Trainingsrunde verwendet wird. Experimente mit realen Infektionsmeldungen über drei Jahre aus der Stadt Yichang, kombiniert mit lokalen Websuchtrends, zeigen, dass DS-DSSGD die Trainingszeit im Vergleich zu mehreren Standardverfahren um etwa 10 Prozent verkürzt, ohne nennenswerten Verlust an Vorhersagegenauigkeit.
Eine praktische Plattform für sichere Zusammenarbeit
Technische Fortschritte sind nur dann relevant, wenn Krankenhäuser und Labore sie tatsächlich nutzen können. Um diese Lücke zu schließen, integriert das Team seine Methoden in eine reale Rechenumgebung namens Yi Shu Fang XDP Privacy Security Computing Platform. XDP verwaltet den gesamten Weg der Gesundheitsdaten – von Erhebung und Bereinigung bis hin zu verschlüsselter Analyse und dem Teilen von Ergebnissen. Es unterstützt vertraute Werkzeuge, die von Statistikern, Bioinformatikern und Klinikern verwendet werden, und erlaubt Forschenden aus verschiedenen Institutionen, innerhalb eines kontrollierten Arbeitsbereichs zusammenzuarbeiten, ohne jemals Rohdaten herunterzuladen. Innerhalb dieser Plattform laufen das hybride Verschlüsselungsschema und der DS-DSSGD-Algorithmus als einsteckbare Komponenten und verwandeln das theoretische Rahmenwerk in ein funktionierendes System. 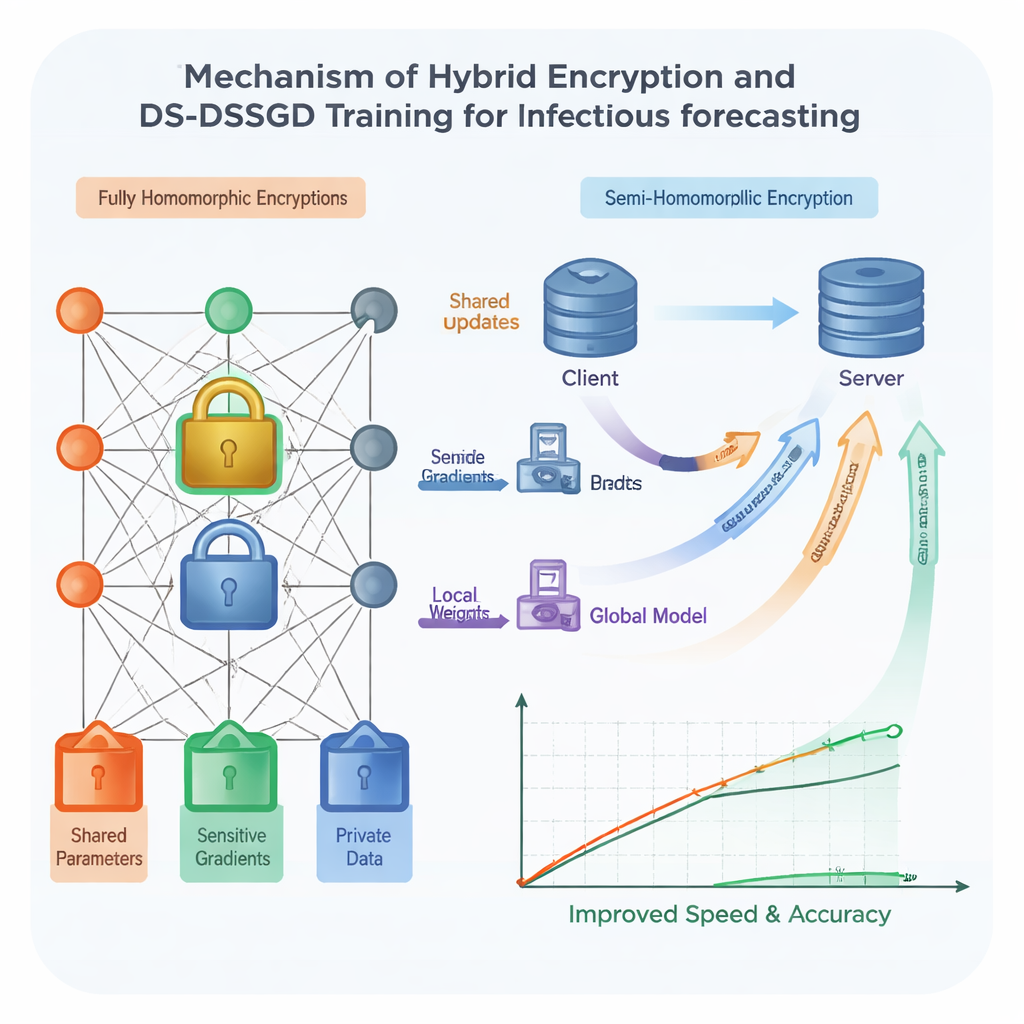
Was das für künftige Ausbruchsprognosen bedeutet
Ganz profan zeigt diese Studie, dass es möglich ist, beim Vorhersagen von Infektionskrankheiten „beides zu haben“: den Schutz der Patientenprivatsphäre und gleichzeitig schnelle, genaue Modelle, die auf Daten vieler Einrichtungen trainiert wurden. Indem unterschiedliche Modellteile mit genau dem richtigen Sicherheitsniveau verschlüsselt, Updates nur bei Bedarf gesendet und alles in eine sichere Kollaborationsplattform eingebettet wird, senken die Autorinnen und Autoren die Kosten der Privatsphäre von einer lähmenden Belastung auf einen handhabbaren Mehraufwand. Bei breiter Annahme könnten solche Ansätze es Krankenhäusern und Gesundheitsbehörden ermöglichen, ihr Wissen gegen die nächste Epidemie zu bündeln, ohne jemals individuelle medizinische Akten offenzulegen.
Zitation: Wang, X., Jiang, Y., Pan, G. et al. A data privacy protection method for infectious disease prediction models with balanced training speed and accuracy. Sci Rep 16, 7415 (2026). https://doi.org/10.1038/s41598-026-38906-9
Schlüsselwörter: Prognose infektiöser Krankheiten, Gesundheitsdatenprivatsphäre, federated learning, homomorphe Verschlüsselung, Deep Learning