Clear Sky Science · de
Schätzung von Artenverbreitung und -häufigkeit durch unüberwachte Methoden
Warum das Zählen häufiger und seltener Arten wichtig ist
Wenn wir uns bedrohte Natur vorstellen, denken wir oft an seltene Tiere am Rande des Aussterbens. Doch der Großteil des lebenden Gewebes um uns herum besteht aus sehr gewöhnlichen Lebewesen, die entweder weit verbreitet sind oder stillschweigend verschwinden, ohne dass es jemand bemerkt. Zu wissen, wie verbreitet eine Art an einem bestimmten Ort tatsächlich ist, ist entscheidend, um vorherzusagen, wie Ökosysteme auf Verschmutzung, Landnutzungsänderungen oder Klimawandel reagieren werden. Diese Studie stellt eine Methode vor, mit der sich die Häufigkeit oder Seltenheit vieler Arten gleichzeitig schätzen lässt, allein auf Basis vorhandener Beobachtungsdaten und moderner Datenanalyse. Ziel ist es, objektivere Eingaben für Computermodelle zu liefern, die vorhersagen, wo Arten jetzt und in Zukunft leben können.
Von einfachen Beobachtungen zu großen ökologischen Fragen
Ökologen verwenden routinemäßig Computermodelle, sogenannte ökologische Nischenmodelle, um herauszufinden, welche Lebensräume für eine Art geeignet sind. Diese Modelle helfen vorherzusagen, wo eine Art unter verändertem Klima oder in neuen Regionen auftreten könnte. Eine entscheidende Größe ist die „Prävalenz“ – grob gesagt der Anteil der untersuchten Standorte, an denen eine Art nachgewiesen wurde. Sie kodiert, ob eine Art voraussichtlich häufig oder selten ist, bevor neue Erhebungen erfolgen. Diese vorherige Erwartung beeinflusst stark, wie Modelle rohe Eignungswerte in Anwesenheitswahrscheinlichkeiten umrechnen und wie sie auf einer Karte zwischen „anwesend“ und „abwesend“ trennen. Wird die Prävalenz falsch geschätzt, besonders bei seltenen Arten, können Vorhersagen irreführend sein und Schutzmaßnahmen sich auf die falschen Orte konzentrieren.
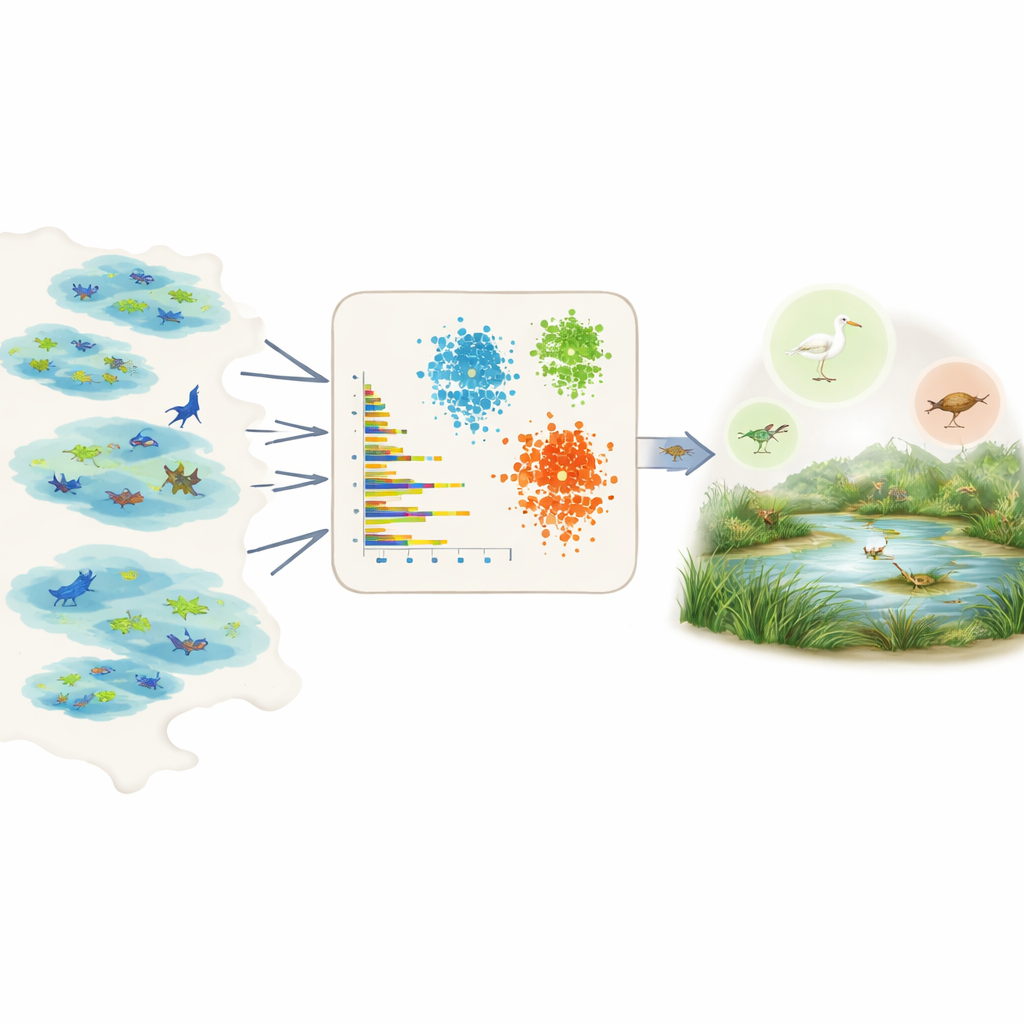
Die Daten für Hunderte von Arten sprechen lassen
Die direkte Messung der Prävalenz ist schwierig, weil Felddaten lückenhaft und verzerrt sind. Manche Gebiete werden stark untersucht, manche Arten sind leichter zu sehen, und viele Datensätze stammen aus Citizen-Science-Projekten mit ungleichmäßigem Aufwand. Statt sich auf Expertenmeinung oder detailliertes Wissen für jede einzelne Art zu stützen, nutzen die Autoren das Global Biodiversity Information Facility, eine riesige offene Datenbank von Artenbeobachtungen. Für jede Art in einer gewählten Region fassen sie die Rohdaten zu einigen einfachen, vergleichbaren Kennzahlen zusammen: wie viele Individuen üblicherweise pro Sichtung gemeldet werden, wie viele unterschiedliche Datensätze oder Feuchtgebiete die Art enthalten, wie weit verbreitet sie innerhalb dieser Feuchtgebiete ist und wie häufig sie über die Zeit beobachtet wird, einschließlich wie oft es zu Ausbrüchen vieler Beobachtungen kommt.
Maschinen beibringen, häufige und seltene Arten zu unterscheiden
Mit diesen zusammengefassten Merkmalen wendet das Team drei unüberwachte Lernverfahren an – zwei Clustering-Methoden und ein Deep-Learning-Modell, bekannt als Variational Autoencoder – die nach Mustern suchen, ohne zuvor zu wissen, welche Arten häufig oder selten sind. Die Clustering-Methoden gruppieren Arten mit ähnlicher Häufigkeit, Verbreitung und Beobachtungsfrequenz. Der Autoencoder lernt, wie ein „typischer“ Beobachtungsdatensatz aussieht, und markiert ungewöhnliche Muster als Anomalien, die oft mit seltenen oder schlecht beobachteten Arten übereinstimmen. Die Modelle ordnen dann jede Art drei anschaulichen Klassen zu – sehr häufig, ziemlich häufig oder selten – und wandeln diese Klassen in numerische Prävalenzwerte um, die direkt als vorherige Wahrscheinlichkeiten in ökologische Nischenmodelle eingespeist werden können.
Test des Ansatzes in einem gefährdeten Feuchtgebiet
Um zu prüfen, wie gut dieses Framework in der Praxis funktioniert, konzentrieren sich die Autoren auf das Einzugsgebiet des Lago di Massaciuccoli in der Toskana, Italien, ein niedrig gelegenes Feuchtgebiet, das reich an Vögeln, Fischen, Insekten und anderen Tieren ist. Diese Landschaft ist sowohl ein Hotspot der Biodiversität als auch ein touristischer Magnet, zugleich aber anfällig für Klimawandel, Wasserknappheit und Verschmutzung. Für 161 mit dem See verbundene Tierarten wurden die Modelle mit Daten aus anderen italienischen Feuchtgebieten trainiert und sollten dann ableiten, wie häufig jede Art in Massaciuccoli sein dürfte. Zwei lokale Experten mit umfassender Feldkenntnis bewerteten dieselben Arten unabhängig voneinander. Im Vergleich dazu stimmte das Deep-Learning-Modell in etwa 81–90 Prozent der Fälle mit der kombinierten Expertenmeinung überein, während die Clustering-Methoden und ein Ensemble aus allen drei ebenfalls gute Leistungen zeigten.
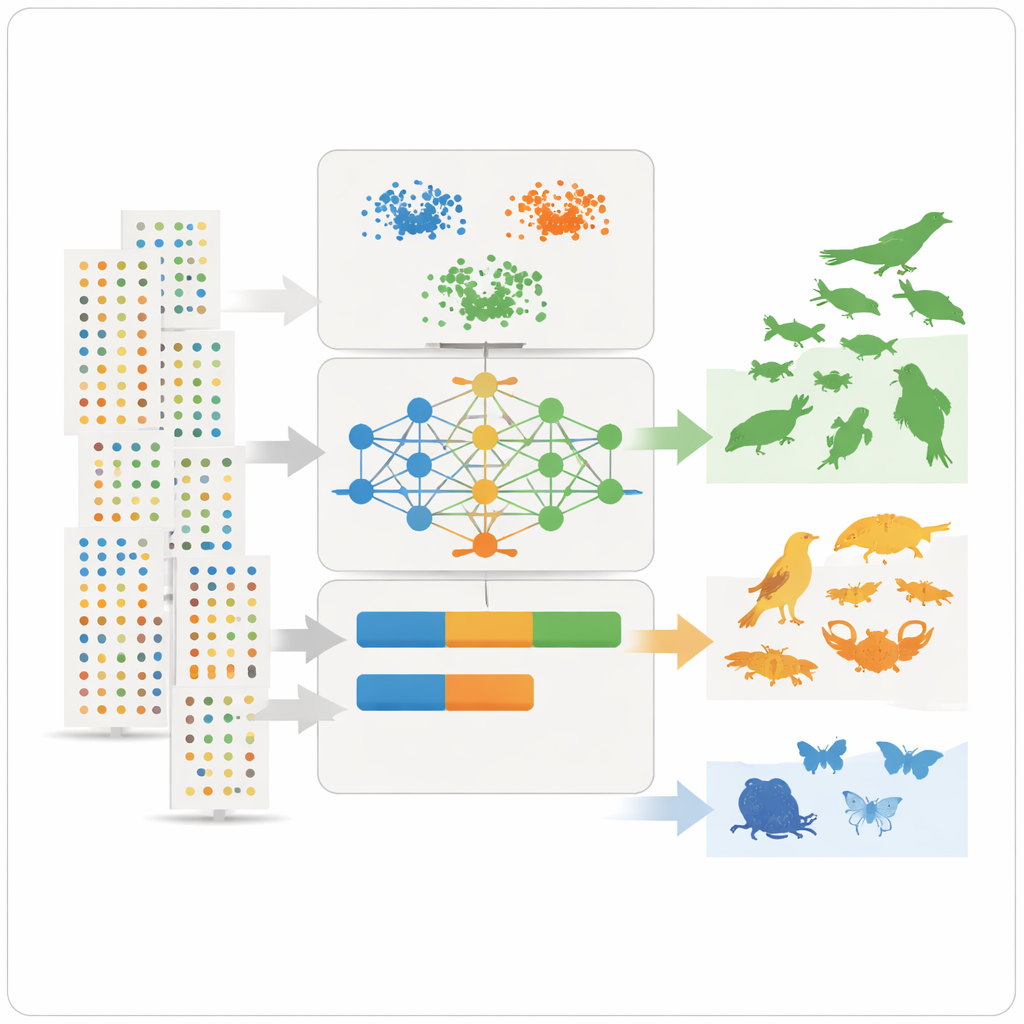
Aus Meinungsverschiedenheiten und verborgenen Verzerrungen lernen
Nicht jeder Fall stimmte perfekt überein. Einige Arten, die Experten als in der Umgebung des Sees reichlich vorkommend kennen, erschienen in den Daten als selten, oft weil sie scheu sind, untererfasst werden oder in manchen Feuchtgebieten stärker beobachtet werden als in anderen. Das zeigte eine wichtige Einschränkung: Große Datenbanken spiegeln wider, wo und wie Menschen nach Natur suchen, nicht nur, wo Arten tatsächlich vorkommen. Eine Sensitivitätsanalyse zeigte, welche Merkmale für die Klassifizierungen am wichtigsten waren: die durchschnittliche Anzahl der Datensätze pro Quelle, die Häufigkeit pro Sichtung und die Konsistenz der Beobachtungen über Jahre hinweg erwiesen sich als besonders aussagekräftig. Trotz verbleibender Verzerrungen lieferte die Methode klare, reproduzierbare Prävalenzschätzungen und lässt sich je nach Modellierungsbedarf auf feinere oder gröbere Klassen einstellen.
Was das für künftige Naturprognosen bedeutet
Für Nicht-Spezialisten lautet die Kernbotschaft, dass wir vorhandene Biodiversitätsdaten nun intelligenter nutzen können, um abzuschätzen, welche Arten in einem bestimmten Umfeld wahrscheinlich häufig, mittelmäßig oder selten sind, ohne jede einzelne Situation manuell anzupassen. Indem laute Beobachtungsdaten in transparente, datengetriebene Prävalenzschätzungen verwandelt werden, hilft das Framework ökologischen Modellen, realistischere Vorhersagen zur Habitatgeeignetheit und zu künftigen Biodiversitätstrends zu liefern. Das kann wiederum bessere Planungen für Feuchtgebiete wie Massaciuccoli und viele andere Ökosysteme weltweit unterstützen, selbst wenn Felddaten unvollständig sind und Expertenzeit knapp ist.
Zitation: Bove, P., Bertini, A. & Coro, G. Estimating species commonness and prevalence through unsupervised methods. Sci Rep 16, 8331 (2026). https://doi.org/10.1038/s41598-026-38900-1
Schlüsselwörter: Artenverbreitung, Modellierung der Biodiversität, Feuchtgebiet-Ökosysteme, Maschinelles Lernen in der Ökologie, Artenhäufigkeit