Clear Sky Science · de
Seriell kaskadierte hybride adaptive Deep-Networks-basierte Klassifikation von Songtexten mithilfe eines Optimierungsansatzes
Warum schlauere Song-Filter wichtig sind
Musik fließt nahezu ununterbrochen in unser Leben, und vieles von dem, was wir hören, wird von Algorithmen ausgewählt. Dennoch haben viele dieser Systeme weiterhin Probleme mit einer einfachen Frage: Was sagen die Worte in einem Lied eigentlich, und für wen sind sie geeignet? Diese Arbeit geht dieses Problem an, indem sie ein fortgeschrittenes künstliches Intelligenz-(KI-)Modell entwickelt, das Songtexte automatisch liest und nach Stimmung, Genre, Sentiment und sogar der Art der Darbietung sortiert. Ziel ist es, sicherere Playlists für Kinder zu ermöglichen, stimmungsbasierte Empfehlungen zu verbessern und bessere Werkzeuge für Musikwissenschaftler bereitzustellen.
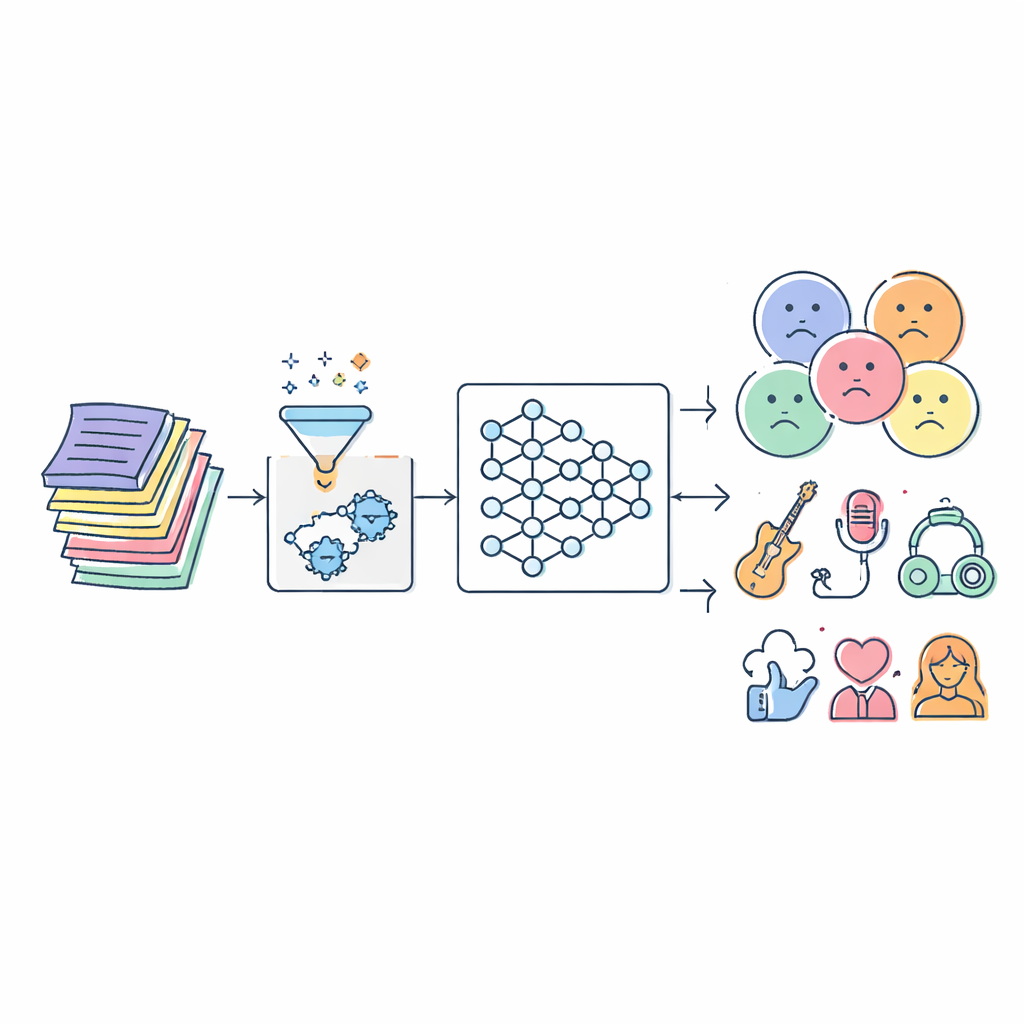
Die Herausforderung, die in Songtexten steckt
Lyrics sind deutlich komplizierter als eine Liste von guten oder schlechten Wörtern. Dieselbe Formulierung kann in einem Song zärtlich wirken und in einem anderen bedrohlich, und Hörer bringen ihre eigenen Erfahrungen in das, was sie wahrnehmen, ein. Traditionelle Filter stützen sich meist auf statische Listen mit beleidigenden Begriffen oder einfache statistische Techniken. Diese Ansätze übersehen den Kontext, kommen mit sich wandelnder Umgangssprache nicht mit und klassifizieren Songs oft falsch. Gleichzeitig führt die Explosion digitaler Musik zu Millionen von Titeln in vielen Sprachen und Stilen, was manuelle Annotationen und ältere Algorithmen überfordert.
Bereinigung der Rohlyrics
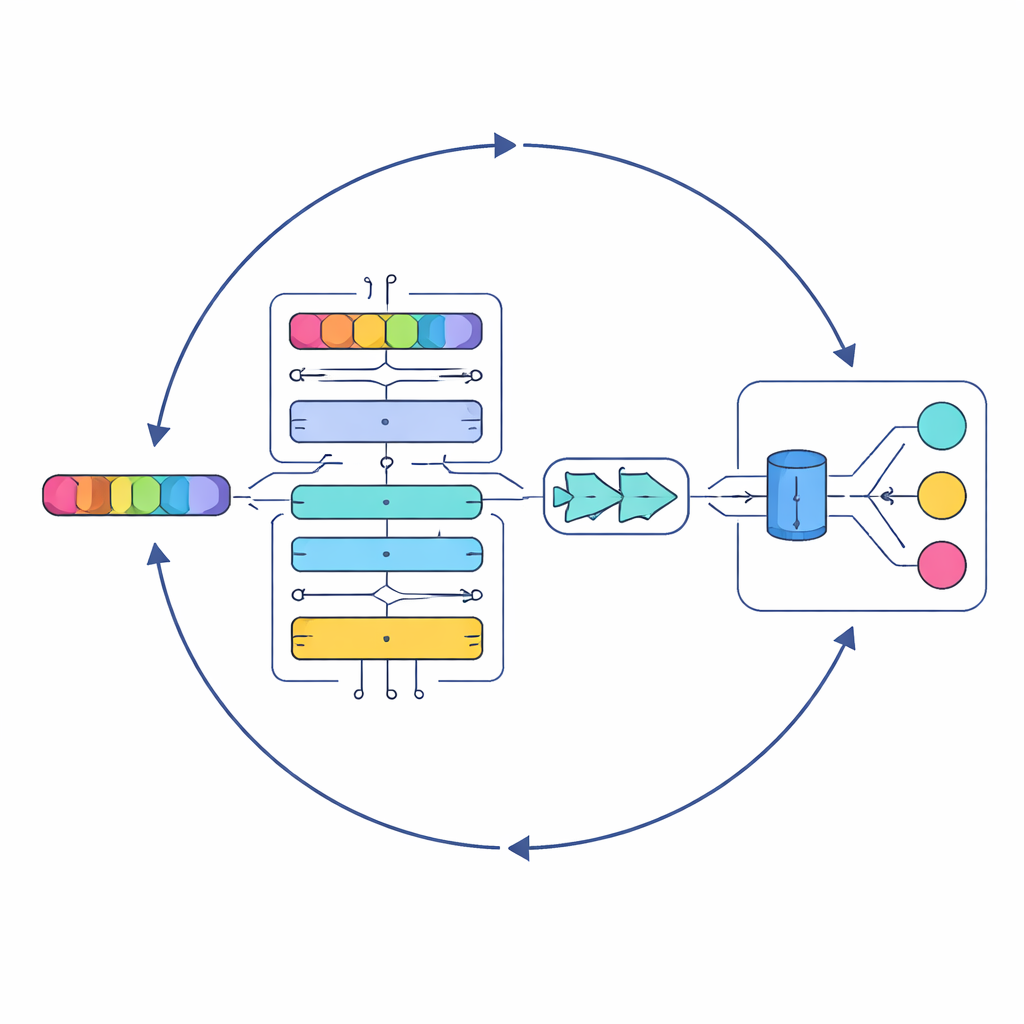
Die Autoren beginnen damit, umfangreiche Textsammlungen aus drei öffentlichen Datensätzen zusammenzustellen, die zusammen Hunderttausende von Songs über mehrere Genres und Sprachen abdecken. Bevor eine KI aus dem Text lernen kann, müssen die Lyrics bereinigt werden. Das System entfernt Interpunktion, Sonderzeichen sowie wiederholte oder irrelevante Fragmente und reduziert verwandte Wortformen auf eine gemeinsame Wurzel (zum Beispiel werden „singing“, „sings“ und „sang“ alle zu „sing“). Dieser Vorverarbeitungsschritt entfernt Rauschen und bewahrt zugleich die Bedeutung, sodass spätere Stufen sich auf Tonalität und Themen anstatt auf Formatierungsbesonderheiten oder Rechtschreibvarianten konzentrieren können.
Ein gestuftes KI-Modell, das wie ein aufmerksamer Zuhörer liest
Kern der Studie ist ein neues Modell namens Serial Cascaded Hybrid Adaptive Deep Network, abgekürzt SCHADNet. Es vereint drei leistungsfähige Ideen moderner Sprach-KI. Erstens erfasst ein transformer-basierter Encoder, wie Wörter sich über ein gesamtes Lied hinweg zueinander verhalten, nicht nur in unmittelbarer Nachbarschaft. Zweitens liest eine bidirektionale Long Short-Term Memory-Schicht den Text vorwärts und rückwärts, was dem System hilft zu verstehen, wie frühere Zeilen die Bedeutung späterer Zeilen färben. Drittens verdichtet eine Gated Recurrent Unit-Schicht diese Informationen zu einer kompakten Zusammenfassung, die sich gut für abschließende Entscheidungen eignet. Zusammengenommen wirken diese Komponenten wie ein Chor spezialisierter Leser, die sich jeweils auf unterschiedliche Aspekte des Songtexts konzentrieren.
Eine Strategie aus dem Meer übernehmen
Einfach tiefenlernende Schichten übereinanderzustapeln reicht nicht aus; ihre internen Einstellungen — etwa wie viele Neuronen sie enthalten und wie lange sie trainieren — beeinflussen die Leistung stark. Statt diese Entscheidungen manuell zu treffen, greifen die Autoren auf einen Optimierungsansatz zurück, der von den Jagdmustern mariner Räuber inspiriert ist. Ihr verbessertes Marine Predators Algorithm (IMPA) erkundet viele mögliche Parameterkombinationen und arbeitet sich systematisch zu denen vor, die die besten Ergebnisse liefern. Indem sie Teile des ursprünglichen Algorithmus entfernen, die in diesem Kontext nicht hilfreich waren, verbessern sie die Konvergenz, das heißt das System findet schneller und verlässlicher gute Lösungen.
Wie gut das System abschneidet
Die Forschenden testen SCHADNet mit IMPA auf drei verschiedenen Lyric-Datensätzen und vergleichen es mit einer Reihe etablierter Methoden, darunter klassische Machine-Learning-Klassifikatoren und mehrere populäre Deep-Learning-Modelle wie einfache LSTM-, reine Transformer-Systeme und hybride Netze. In Bezug auf Genauigkeit, Recall (wie viele wirklich relevante Songs gefunden werden) und andere Qualitätsmaße schneidet der neue Ansatz durchgängig am besten ab. In einem großen mehrsprachigen Datensatz klassifiziert er etwa 93 % der Songs korrekt und erzielt einen besonders hohen negativen Prädiktionswert, was bedeutet, dass er sehr gut darin ist, Lyrics zu erkennen, die nicht in eine markierte Kategorie gehören — entscheidend, um übermäßiges Blockieren oder Fehletikettieren zu vermeiden.
Was das für Hörer und Kreative bedeutet
Für Laien ist die Botschaft klar: Die Autoren haben einen nuancierteren, verlässlicheren Leser für Songtexte entwickelt. Anstatt sich auf grobe Wortlisten zu stützen, betrachtet ihr System ganze Phrasen, Kontext und Muster über große Musiksammlungen hinweg und weist automatisch Labels wie Stimmung, Stil oder Eignung für jüngeres Publikum zu. Obwohl das Modell komplex und rechenintensiv ist, eröffnet es Möglichkeiten für intelligentere Kinderschutzfunktionen, reichere, stimmungsbasierte Playlists und neue Wege, Trends in der populären Musik zu untersuchen. Zukünftige Arbeiten zielen darauf ab, den Datenbedarf zu reduzieren und das Training zu beschleunigen, doch schon in seiner derzeitigen Form weist SCHADNet in eine Zukunft, in der Musikplattformen Lyrics fast so aufmerksam verstehen wie ein aufmerksamer menschlicher Zuhörer.
Zitation: Jasmine, R.L., Mukherjee, S., Robin, C.R.R. et al. Serial cascaded hybrid adaptive deep networks-based lyrics text classification using optimization approach. Sci Rep 16, 8527 (2026). https://doi.org/10.1038/s41598-026-38813-z
Schlüsselwörter: Musikempfehlung, Lyrics-Analyse, Textklassifikation, Deep Learning, Inhaltsmoderation