Clear Sky Science · de
Verbesserung der Erkennung von Vertragsbetrug durch Ensemble-Lernen: der Fall Ethio Telecom
Warum Telefonbetrug uns alle betrifft
Jedes Mal, wenn wir telefonieren, eine SMS schicken oder mobile Daten nutzen, gehen wir davon aus, dass die Rechnung dem tatsächlichen Verbrauch entspricht. Kriminelle können jedoch Netze ausnutzen, indem sie Leitungen mit falschen Identitäten eröffnen, enorme unbezahlte Kosten anhäufen und diese Leitungen sogar für andere Straftaten nutzen. Diese Studie konzentriert sich auf Ethio Telecom, den staatlichen Anbieter in Äthiopien, und zeigt, wie fortgeschrittene datengetriebene Methoden verdächtige Anschlüsse deutlich genauer identifizieren können als herkömmliche Werkzeuge. Das hilft, Mobilfunkdienste für Millionen von Nutzern erschwinglich und sicher zu halten.
Die versteckten Kosten falscher Telefonkonten
Vertragsbetrug tritt auf, wenn jemand einen Telefonanschluss mit falschen oder gestohlenen Daten anmeldet und nie beabsichtigt zu bezahlen. Weltweit ist dies eine der schädlichsten Formen des Telekommunikationsbetrugs und kostet die Branche jährlich mehrere zehn Milliarden Dollar. Bei Ethio Telecom allein wird der Betrug auf etwa eine Milliarde Dollar pro Jahr geschätzt, wobei gefälschte Verträge für rund 40 % dieses Verlusts verantwortlich sind. Neben entgangenen Einnahmen können solche Leitungen für Betrügereien, internationales Weiterverkaufen von Gesprächen oder andere illegale Aktivitäten genutzt werden und stellen damit ein Risiko für Kunden und die nationale Sicherheit dar.
Von handgemachten Regeln zum Lernen aus Daten
Wie viele Anbieter vertraute Ethio Telecom traditionell auf von Experten formulierte fixe Regeln, um verdächtiges Verhalten zu markieren — etwa das Sperren einer Leitung nach zu vielen internationalen Anrufen in kurzer Zeit. Diese regelbasierten Systeme sind leicht verständlich, haben aber Probleme, wenn Betrüger ihre Taktiken ändern oder die Nutzungsmuster komplex sind. Die Autoren argumentieren, dass maschinelles Lernen, das Muster direkt aus historischen Daten lernt, schneller und sensibler reagieren kann. Anstatt sich auf ein einzelnes Modell zu verlassen, untersuchen sie „Ensemble“-Methoden, die mehrere Modelle kombinieren, sowie „adaptive“ Methoden, die sich laufend an neue Daten anpassen.
Was die Forscher aus realen Verbindungsdaten aufgebaut haben
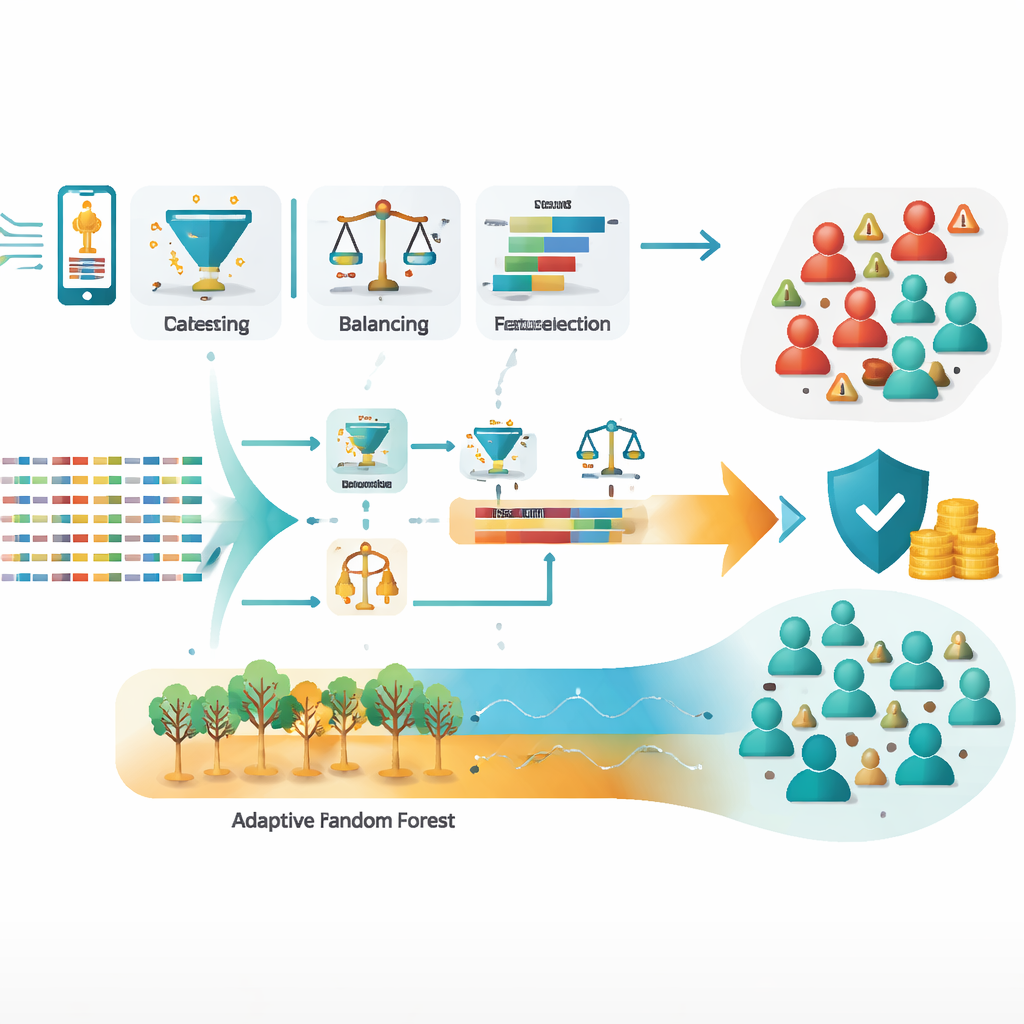
Das Team arbeitete mit einem umfangreichen Satz von Call-Detail-Records — Protokollen darüber, wer wen anrief, wie lange und unter welchen Bedingungen — aus einem zweimonatigen Zeitraum mit intensiver Betrugsaktivität. Aus etwa einer Million Rohdatensätze bereinigten sie die Daten, entfernten Fehler und Duplikate, balancierten die stark verzerrten Klassen aus (wesentlich mehr ehrliche Nutzer als Betrüger) und entwickelten neue Merkmale, die verdächtiges Verhalten besser erfassen. Besonders wichtig waren Kennzahlen wie die Anzahl gewählter internationaler Nummern pro Teilnehmer, der Anteil aller Anrufe, der international war, und das Verhältnis eindeutiger gewählter Nummern zu Gesamtanrufen. Diese verdichteten Signale unterscheiden oft normalen Gebrauch von organisierter Missbrauchspraxis deutlich besser als einfache Zählwerte oder demografische Angaben.
Wie die Kombination von Modellen die Erkennung verbessert
Die Forscher testeten drei Standardmodelle — Entscheidungsbäume, logistische Regression und künstliche neuronale Netze — neben mehreren Ensemble-Strategien wie Bagging (Random Forest), Boosting (XGBoost), Voting und Stacking sowie adaptiven Modellen für kontinuierliche Datenströme (Hoeffding Tree und Adaptive Random Forest). Nach sorgfältiger Abstimmung der Modelleinstellungen erreichte der Stacking-Ansatz, der lernt, die Stärken mehrerer Basismodelle zu kombinieren, etwa 99,3 % Genauigkeit auf nicht gesehenen Daten. Der Adaptive Random Forest war nahezu ebenso stark mit etwa 99,2 % Genauigkeit und konnte sich zusätzlich an veränderte Betrugsmuster anpassen. Beide Ansätze verringerten den gefährlichsten Fehler — tatsächlichen Betrug zu übersehen — deutlich im Vergleich zu einzelnen Modellen.
Mit sich ändernden Tricks in Echtzeit Schritt halten
Da Betrüger ihre Methoden ständig ändern, kann ein statisches Modell schnell veralten. Um dem zu begegnen, verwendeten die Autoren eine Online-Feature-Selection-Technik, die fortlaufend neu bewertet, welche Signale am wichtigsten sind, ohne das System von Grund auf neu aufbauen zu müssen. Sie betonen außerdem die Bedeutung des Datenschutzes: Alle persönlichen Identifikatoren in den Daten wurden vor der Analyse anonymisiert, und sie empfehlen strikte Zugriffskontrollen sowie Prüfspuren. Für den praktischen Einsatz skizziert die Studie eine Echtzeit-Architektur, in der neue Verbindungsdatensätze über Werkzeuge wie Apache Kafka in adaptive Modelle gestreamt werden, die sich on-the-fly aktualisieren und gleichzeitig auf plötzliche Verhaltensänderungen überwachen.
Was das für Nutzer und Anbieter bedeutet
Einfach ausgedrückt zeigt die Studie, dass mehrere intelligente Modelle, die „miteinander abstimmen“, und die Fähigkeit zum kontinuierlichen Lernen gefälschte Verträge mit bemerkenswerter Genauigkeit aufdecken können, während Fehlalarme auf einem handhabbaren Niveau bleiben. Für Ethio Telecom könnte das erhebliche Einsparungen, stabilere Preise und stärkeren Schutz vor krimineller Netznutzung bedeuten. Für Kunden heißt das, dass ungewöhnliches, aber legitimes Verhalten seltener fälschlich als Betrug interpretiert wird, während tatsächlich riskante Leitungen schneller erkannt und geschlossen werden. Die Autoren schließen, dass Ensemble- und Adaptive-Learning-Ansätze, gestützt auf sorgfältig gewählte, kontextbezogene Indikatoren, eine leistungsstarke und skalierbare Blaupause für moderne Telekom-Betrugserkennung liefern.
Zitation: Desta, E.A., Azale, K.W., Hailu, A.A. et al. Enhancing subscription fraud detection through ensemble learning the case of Ethio telecom. Sci Rep 16, 7867 (2026). https://doi.org/10.1038/s41598-026-38790-3
Schlüsselwörter: Telekommunikationsbetrug, Vertragsbetrug, Ensemble-Lernen, Adaptive Random Forest, Call-Detail-Records