Clear Sky Science · de
Genaue und interpretierbare Vorhersage der chemischen Sauerstoffnachfrage mithilfe erklärbarer Boosting-Algorithmen mit SHAP-Analyse
Warum es wichtig ist, den Sauerstoffgehalt eines Flusses zu beobachten
Flüsse sind die Lebensadern von Städten und landwirtschaftlichen Gebieten. Wenn sie jedoch mit organischen Abfällen aus Fabriken, Kanälen oder Feldern belastet werden, kann das Wasser an Sauerstoff verlieren und für Menschen und Ökosysteme gefährlich werden. Ein gängiger Gesundheitsindikator für Flüsse ist die „chemische Sauerstoffnachfrage“ (COD), ein Maß dafür, wie viel Sauerstoff benötigt wird, um Verschmutzungen zu zersetzen. Die COD-Bestimmung im Labor ist langsam und teuer, daher untersucht diese Studie, ob fortgeschrittene, aber erklärbare Werkzeuge des maschinellen Lernens COD zuverlässig aus routinemäßigen Sensordaten vorhersagen können — und dabei klar aufzeigen, was die Verschmutzung antreibt. 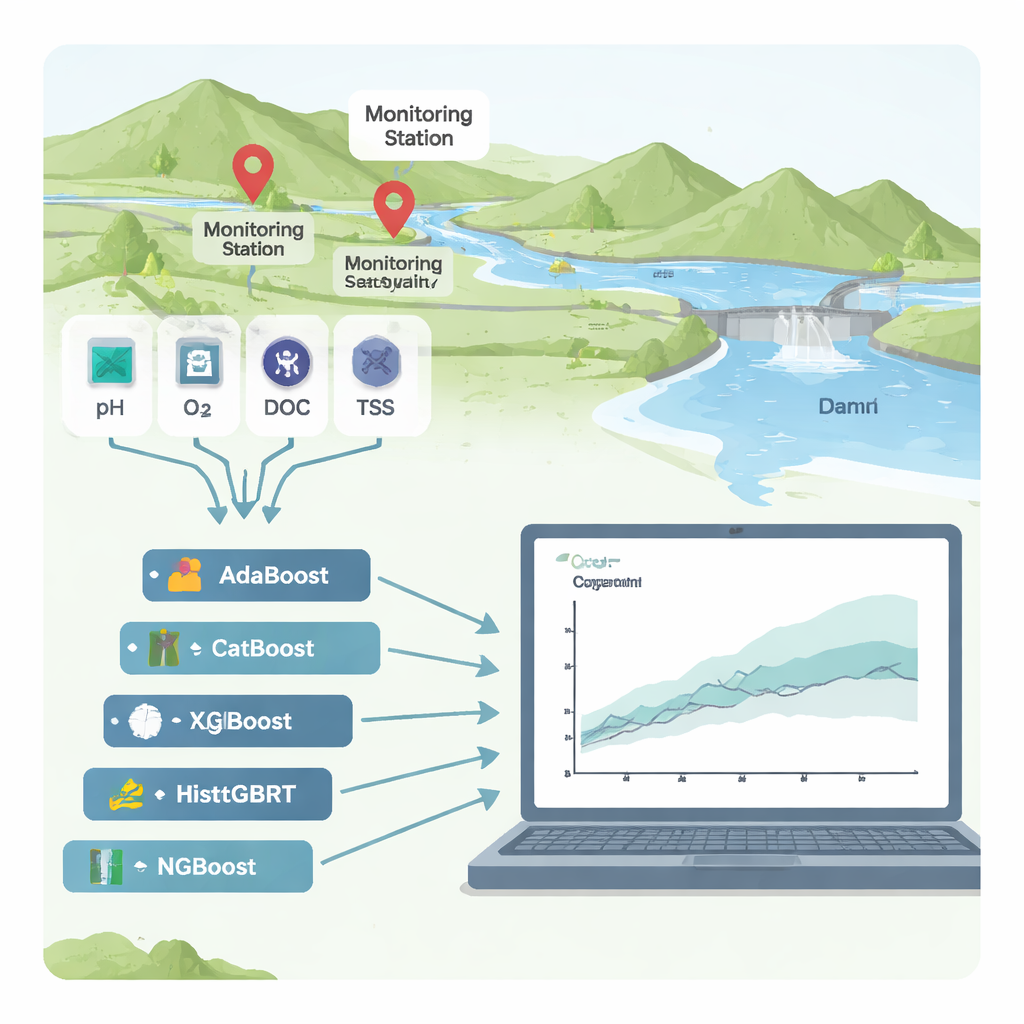
Intelligente Modelle für eine verschmutzte Welt
Die Forschenden konzentrierten sich auf zwei Flussmessstationen in Südkorea, Hwangji und Toilchun, knapp oberhalb des multifunktionalen Yeongju-Staudamms. Für diese Stationen liegen jahrzehntelange Messreihen gängiger Wasserqualitätsindikatoren vor: Säuregrad (pH), gelöster Sauerstoff, Schwebstoffe (feine Partikel im Wasser), Nährstoffe wie Stickstoff und Phosphor, gesamter organischer Kohlenstoff (TOC), biochemischer Sauerstoffbedarf (BOD₅), Wassertemperatur, elektrische Leitfähigkeit und Flussabfluss. Anstatt ein traditionelles physikbasiertes Modell zu entwickeln — das sich oft schwer von einem Fluss auf einen anderen übertragen lässt — testeten sie sechs „Boosting“-Algorithmen, eine leistungsfähige Familie von Methoden des maschinellen Lernens, die viele einfache Entscheidungsbäume zu einem starken Prädiktor kombinieren.
Den besten Fluss-„Wetterdienst“ finden
Um die sechs Boosting-Methoden (AdaBoost, CatBoost, XGBoost, LightGBM, HistGBRT und NGBoost) zu vergleichen, trainierte das Team die Modelle mit etwa 70 % der historischen Daten und prüfte die Leistung an den verbleibenden 30 %. Die Genauigkeit bewerteten sie mit mehreren Kennzahlen, die erfassen, wie nah die Vorhersagen an den tatsächlichen COD-Messungen liegen und wie gut die Modelle auf ungesehene Bedingungen generalisieren. An der Station Toilchun war das NGBoost-Modell — das nicht nur einen einzelnen Wert, sondern eine gesamte Wahrscheinlichkeitsverteilung für COD vorhersagt — der klare Gewinner und erfasste nahezu die gesamte Variation des COD bei sehr kleinen Fehlern. In Hwangji, einem komplexeren Standort, bot CatBoost die beste Kombination aus Genauigkeit und Stabilität. Einige Modelle, insbesondere XGBoost, wirkten auf den Trainingsdaten nahezu perfekt, stolperten jedoch bei den Testdaten — ein klassisches Zeichen von Überanpassung, bei dem ein Modell Rauschen auswendig lernt statt echte Muster.
Die Black Box der KI öffnen
Ein zentrales Ziel der Studie war es nicht nur, COD vorherzusagen, sondern auch zu erklären, warum die Modelle diese Vorhersagen trafen. Dafür verwendeten die Autoren SHAP (Shapley Additive Explanations), eine Technik, die jeder Eingangsvariablen zu jeder einzelnen Vorhersage einen positiven oder negativen Beitrag zuweist. In beiden Flüssen und über die meisten Algorithmen hinweg traten drei Variablen immer wieder als die Haupttreiber des COD hervor: gesamter organischer Kohlenstoff (TOC), biochemischer Sauerstoffbedarf (BOD₅) und Schwebstoffe (SS). Einfach ausgedrückt: Je mehr organisches Material und feine Partikel im Wasser sind, desto höher ist die Sauerstoffnachfrage. Die Modelle zeigten auch standortspezifische Unterschiede: In Toilchun spielten Abfluss (Flow) und Gesamtphosphor eine stärkere Rolle, was auf einen größeren Einfluss diffuser Quellen wie landwirtschaftlichen Abflusses hindeutet; in Hwangji deuteten Muster in der Leitfähigkeit und den Schwebstoffen eher auf lokalere oder industrielle Quellen hin. 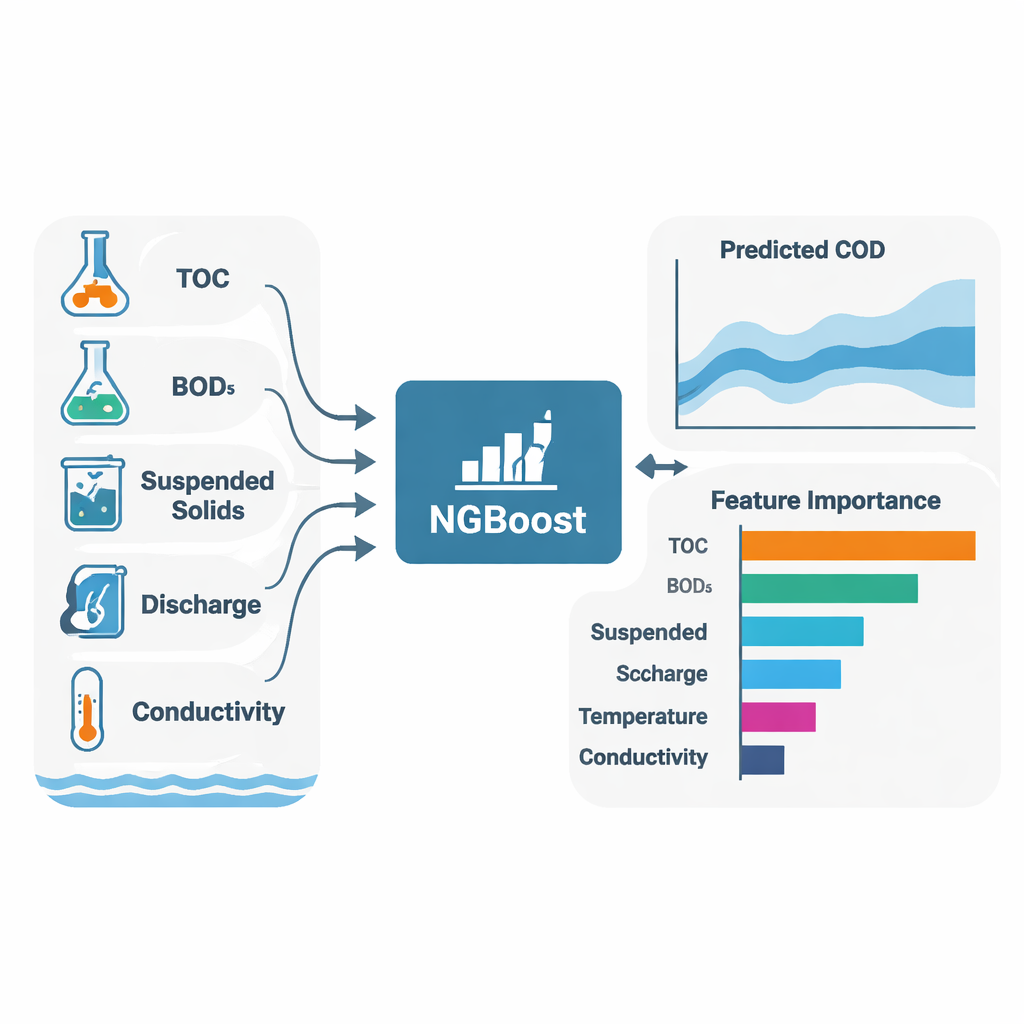
Was die Ergebnisse für reale Flüsse bedeuten
Diese Erkenntnisse zeigen, dass Boosting-Modelle, gepaart mit SHAP, über undurchsichtige „Black Boxes“ hinausgehen können. Sie liefern sowohl präzise Vorhersagen der Sauerstoffnachfrage von Flüssen als auch eine physikalisch sinnvolle Erklärung dafür, was die Verschmutzung an jedem Standort antreibt. Das ist wichtig für Betreiber von Staudämmen und Flusseinzugsgebieten, die priorisieren müssen, was überwacht und wo eingegriffen werden soll: Wenn TOC und BOD₅ die stärksten Stellgrößen sind, kann die Kontrolle organischer Einträge die größte Verbesserung der Wasserqualität bewirken. Die probabilistischen Vorhersagen von NGBoost liefern außerdem ein Maß für die Unsicherheit, was für Frühwarnsysteme und risikobasierte Entscheidungen entscheidend ist. Kurz gesagt zeigt die Studie, dass sorgfältig gestaltete, erklärbare KI helfen kann, Trinkwasserreservoire und aquatische Lebensräume zu schützen, indem sie routinemäßige Sensormessungen in verlässliche, transparente Vorhersagen zur Gesundheit von Flüssen verwandelt.
Zitation: Merabet, K., Kim, S., Heddam, S. et al. Accurate and interpretable prediction of chemical oxygen demand using explainable boosting algorithms with SHAP analysis. Sci Rep 16, 6359 (2026). https://doi.org/10.1038/s41598-026-38757-4
Schlüsselwörter: Wasserqualität, chemische Sauerstoffnachfrage, Maschinelles Lernen, Flussverschmutzung, erklärbare KI