Clear Sky Science · de
Erkennung von Gesichtsausdrücken mittels Variationsinferenz
Gefühle im Gesicht lesen
Unsere Gesichter senden ständig Signale darüber, wie wir uns fühlen, doch diese Signale sind selten simpel. Ein Lächeln kann Nervosität verbergen, und ein „neutraler“ Blick kann Langeweile mit Gereiztheit vermischen. Diese Studie stellt POSTER-Var vor, ein neues System der künstlichen Intelligenz (KI), das darauf abzielt, solche feinen, gemischten Emotionen genauer zu erkennen als heutige Werkzeuge zur Gesichtsausdruckserkennung — mit möglichen Verbesserungen für alles von Mensch‑Computer‑Interaktion bis hin zur Überwachung psychischer Gesundheit.
Warum Emotionen nicht einfach an oder aus sind
Die meisten bestehenden Systeme zur Erkennung von Gesichtsausdrücken behandeln Emotionen als saubere, getrennte Kategorien: glücklich, traurig, wütend und so weiter. In der Realität zeigt die Psychologie, dass Ausdrücke Mischungen grundlegender Emotionen sind, wobei verschiedene Intensitäten gleichzeitig im selben Gesicht auftreten können. Traditionelle KI‑Modelle zwingen ein Bild meist in ein einziges hartes Label, ignorieren Unsicherheit und die kontinuierliche, abgestufte Natur von Gefühlen. Das macht sie anfällig in unordentlichen realen Umgebungen, in denen Beleuchtung, Pose und selbst inkonsistente menschliche Labels Rauschen hinzufügen. Die Autoren argumentieren, dass zukünftige Systeme anerkennen müssen, dass ein Gesicht auf mehrere Emotionen mit unterschiedlichen Intensitäten hinweisen kann, und dass Computer in Wahrscheinlichkeiten statt in Ja‑oder‑Nein‑Entscheidungen denken sollten.
Dem Modell erlauben, Unsicherheit zu akzeptieren
Um dieser unordentlichen Realität besser gerecht zu werden, baut das Team auf einer Technik der modernen probabilistischen Modellierung namens Variationsinferenz auf. Anstatt für jede Emotion eine einzelne feste Punktzahl auszugeben, bildet ihr POSTER‑Var‑System Gesichtsmerkmale in einen „latenten Raum“ ab, in dem jede Emotion durch eine Wahrscheinlichkeitsverteilung repräsentiert wird, typischerweise in Form einer Glockenkurve. Während des Trainings zieht das System Stichproben aus diesen gelernten Verteilungen, was es ermutigt, ein Spektrum möglicher Interpretationen für jedes Gesicht zu erkunden. Im Testbetrieb verwendet es jedoch die Zentren dieser Verteilungen, um stabile Vorhersagen zu treffen. Entscheidend ist, dass POSTER‑Var zusätzliche Decodier‑ und voll verbundene Schichten, wie sie in früheren Variational‑Designs verwendet wurden, entfernt und die probabilistische Repräsentation selbst als finales Entscheidungssignal behandelt. Dieser gestraffte „Variational Inference-based Classification Head“ oder VICH erlaubt dem Modell, Unsicherheit zu quantifizieren und zugleich effizient und genau zu bleiben.
Das Gesicht auf mehreren Skalen sehen
Die Erkennung von Ausdrücken erfordert außerdem, verschiedene Gesichtsbereiche und unterschiedliche Detailebenen zu betrachten: die Krümmung des Mundes, die Form der Augen und die Gesamtanordnung sind alle relevant. POSTER‑Var erweitert ein leistungsfähiges Vorgängersystem (POSTER++) durch Verbesserungen bei der Kombination dieser Mehrskalenmerkmale. Es verwendet mehrere Aufmerksamkeitsmechanismen, um Informationen aus einem Standardbild‑Backbone und einem Gesichtspunkterkennungs‑Detektor zu fusionieren, der Eckpunkte der Augen und Mundkanten nachverfolgt. Eine „Layer‑Embedding“ markiert jede Merkmalstabelle mit ihrer Position und semantischen Ebene in der Verarbeitungspyramide und hilft dem Netzwerk zu verstehen, aus welcher Ebene welche Details stammen. Nichtlineare Transformationen und ein verbesserter Channel‑Attention‑Block gleichen diese Merkmale anschließend neu aus, verstärken diejenigen, die für Ausdrücke besonders informativ sind, und unterdrücken Ablenkungen wie Hintergrund‑Unordnung oder identitätsspezifische Eigenheiten.
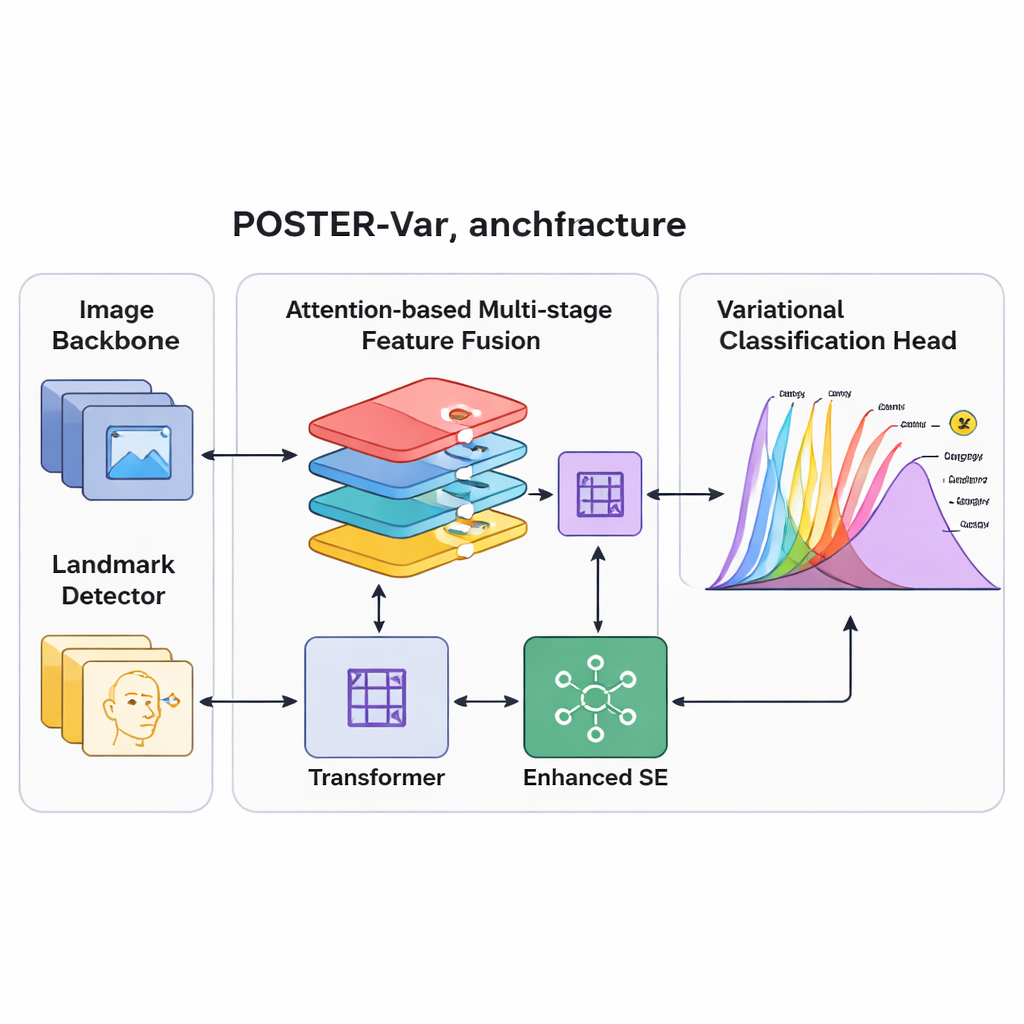
Das System auf die Probe stellen
Die Forschenden bewerteten POSTER‑Var auf drei weit verbreiteten, realen Datensätzen: RAF‑DB, AffectNet und FER+. Diese Sammlungen enthalten hunderttausende Gesichter, die unter unkontrollierten Bedingungen aufgenommen wurden, jeweils mit einer von mehreren Grundemotionen etikettiert. Über alle Benchmarks hinweg erreichte POSTER‑Var entweder den Stand der Technik oder übertraf ihn. Beispielsweise erzielte es etwa 93 % Genauigkeit auf RAF‑DB und rund 92 % auf FER+, sowie leichte Verbesserungen bei den 7‑Klassen‑ und 8‑Klassen‑Versionen von AffectNet. Ablationsstudien, bei denen einzelne Komponenten entfernt wurden, zeigten, dass sowohl das Layer‑Embedding als auch der variationale Head spürbar zur Leistung beitrugen, wobei die variationale Komponente insbesondere bei schwierigeren, unausgewogeneren Datensätzen hilfreich war. Visualisierungen der Aufmerksamkeitskarten zeigten, dass POSTER‑Var auf breitere, sinnvollere Gesichtsregionen fokussiert als die Referenzmethode, und Darstellungen der gelernten Emotionsverteilungen veranschaulichten, wie es z. B. „traurig“ besser von „neutral“ in mehrdeutigen Fällen trennt.
Was das für Anwendungen in der realen Welt bedeutet
Einfach gesagt lehrt POSTER‑Var Maschinen, Gesichtsausdrücke weniger wie Ampeln und mehr wie Wettervorhersagen zu behandeln: Es kann eine dominante „sonnige“ Stimmung mit verstreuten „wolkenhaften“ Hinweisen geben, und die Prognose sollte Unsicherheit anerkennen. Indem das System ganze Verteilungen über Emotionen modelliert statt einer einzelnen Vermutung, wird es robuster gegenüber verrauschten Labels und subtilen, gemischten Ausdrücken. Die Studie legt nahe, dass solche probabilistischen Ansätze der Kern der nächsten Generation affektbewusster Technologien sein könnten und virtuelle Assistenten, soziale Roboter und Instrumente der Verhaltensforschung sensibler für das komplexe emotionale Leben werden könnten, das unsere Gesichter nur unvollkommen offenbaren.
Zitation: Lv, G., Zhang, J. & Tsoi, C. Facial expression recognition via variational inference. Sci Rep 16, 7323 (2026). https://doi.org/10.1038/s41598-026-38734-x
Schlüsselwörter: Erkennung von Gesichtsausdrücken, Emotionen KI, probabilistische Modellierung, Variationsinferenz, Computer Vision