Clear Sky Science · de
Bewertung der Leistungsfähigkeit großer Sprachmodelle bei persischen Rheumatologie-Board-Prüfungen: Genauigkeit und klinisches Denken von GPT-4o vs. GPT-5.1
Warum das für Ärztinnen, Ärzte und Patientinnen und Patienten wichtig ist
Künstliche Intelligenz hält schnell Einzug in medizinische Hörsäle und Kliniken, doch die meisten Tests dieser Werkzeuge konzentrieren sich auf Englisch. Diese Studie stellt eine Frage, die für Millionen persischsprachiger Menschen relevant ist: Wie gut bewältigen fortgeschrittene KI-Chatbots, konkret GPT‑4o und GPT‑5.1, komplexe rheumatologische Prüfungsfragen in persischer Sprache? Die Antwort hilft Ausbildern, Weiterzubildenden und Patientinnen und Patienten zu verstehen, wo diese Werkzeuge beim Lernen sinnvoll unterstützen können und wo menschliche Expertise unabdingbar bleibt.
KI auf dem Prüfstand
Die Forschenden sammelten 204 Multiple‑Choice-Fragen aus den offiziellen iranischen Rheumatologie-Board-Prüfungen der Jahre 2023 und 2024 — denselben Prüfungen, die Spezialistinnen und Spezialisten zur Zertifizierung bestehen müssen. Nach dem Ausschluss von sieben fehlerhaften Fragen blieben 197 Items übrig. Jede Frage, einschließlich begleitender Bilder oder Grafiken, wurde auf Persisch in jeweils einen frischen Chat mit GPT‑4o und GPT‑5.1 eingegeben. Die Modelle sollten die beste Antwort auswählen und ihre Argumentation erklären, ganz so, wie eine oder ein Lernender eine KI beim Studium befragen würde.
Sowohl Antworten als auch Begründungen überprüfen
Die Leistung wurde auf zweierlei Weise bewertet. Zunächst wurden die gewählten Optionen der Modelle mit dem offiziellen Antwortschlüssel verglichen, was eine einfache richtige‑oder‑falsche Genauigkeitsmessung ergab. Zweitens bewerteten sechs von Boards zertifizierte Rheumatologinnen und Rheumatologen unabhängig die Qualität jeder Erklärung auf einer fünfstufigen Skala, von klarer Fehlbegründung bis zu vollständiger und klinisch fundierter Argumentation. Die Antworten jedes Modells wurden von jeweils zwei verschiedenen Rheumatologen bewertet, die voneinander und vom offiziellen Antwortschlüssel verblindet waren. So konnten die Forschenden nicht nur sehen, ob die KI „richtig geraten“ hatte, sondern ob ihre Logik der Denkweise von Spezialistinnen und Spezialisten ähnelte.
Wie sich das neuere Modell schlug
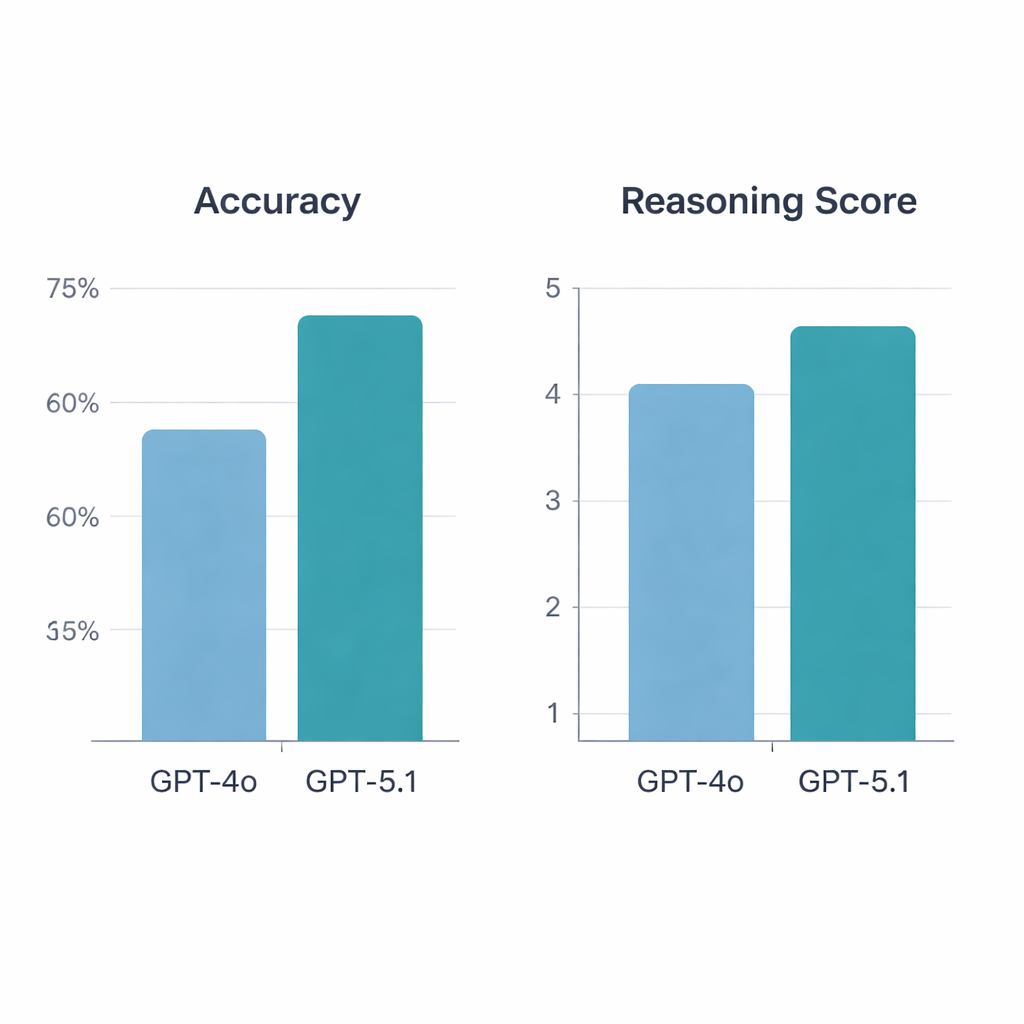
GPT‑5.1 übertraf GPT‑4o deutlich. Bei den 197 gültigen Fragen beantwortete GPT‑4o 64,5 % korrekt, während GPT‑5.1 eine Genauigkeit von 76 % erreichte — ein statistisch signifikanter Zuwachs. Beide Modelle beantworteten 113 Fragen richtig und 34 falsch, doch GPT‑5.1 löste zusätzlich 36 Fragen, die GPT‑4o verfehlte; GPT‑4o war nur bei 13 Fragen allein richtig. Als die Rheumatologen die Erklärungen benoteten, lag GPT‑5.1 erneut vorn, mit einem durchschnittlichen Begründungswert von 4,47 von 5 gegenüber 4,13 für GPT‑4o, und es erhielt mehr Spitzenbewertungen. Anders als GPT‑4o, dessen Begründungsqualität je nach Fragetyp (Grundlagenwissenschaft, Fallvignetten, Diagnose oder Therapie) schwankte, zeigte GPT‑5.1 eine gleichmäßigere Leistung über alle Kategorien hinweg.
Stärken, Lücken und menschliche Uneinigkeit
Die Studie offenbarte wichtige Nuancen. Selbst wenn die endgültige Antwort eines Modells falsch war, bewerteten Fachärztinnen und -ärzte die Begründung mitunter als recht kohärent, was eine Kluft zwischen Prüfungsbewertung und klinischem Denken in der Praxis aufzeigt. Gleichzeitig war die Übereinstimmung zwischen den rheumatologischen Bewerterinnen und Bewertern nur mäßig, was unterstreicht, dass auch Klinikerinnen und Kliniker unterschiedlich beurteilen, was als „gute Begründung“ gilt. Sprache scheint ebenfalls eine Rolle zu spielen: Frühere Arbeiten in Englisch und Spanisch berichteten über höhere Bewertungen für ähnliche Modelle, was darauf hindeutet, dass KI noch besser mit großen Weltsprachen zurechtkommt als mit Persisch. Die Autorinnen und Autoren betonen, dass diese Chatbots überzeugende Erklärungen erzeugen können, die faktische Fehler verbergen, und dass ihre Leistungsfähigkeit sich mit Systemupdates ändern kann.
Was das für die Zukunft bedeutet
Für interessierte Laien lautet die Botschaft: Die neueste Generation von KI-Chatbots wird besser darin, fachärztliche Prüfungen in Persisch zu bearbeiten, ist aber nicht bereit, strenge Ausbildung oder fachliche Urteile zu ersetzen. GPT‑5.1 kann ein hilfreicher Lernpartner für Rheumatologie-Weiterzubildende sein — Zusammenfassungen erstellen, Fälle durchgehen und strukturierte Erklärungen anbieten —, sollte aber nicht als endgültige Autorität für Entscheidungen mit hohem Risiko in Diagnose oder Therapie gelten. Die Autorinnen und Autoren fordern größere, mehrsprachige Studien, wiederholte Tests über die Zeit und realistische klinische Simulationen, um zu bestimmen, wie diese Werkzeuge sicher in die medizinische Ausbildung und schließlich in die tägliche Patientenversorgung eingebunden werden können.
Zitation: Rafiei, F., Sadeghipour, S., Sheikhalishahi, S. et al. Evaluation of large Language model performance on Persian rheumatology board exams: accuracy and clinical reasoning of GPT-4o vs. GPT-5.1. Sci Rep 16, 7274 (2026). https://doi.org/10.1038/s41598-026-38716-z
Schlüsselwörter: Rheumatologie, persische medizinische Ausbildung, große Sprachmodelle, klinisches Denken, Board-Prüfungen