Clear Sky Science · de
Entropiegeführtes mehrstufiges Merkmalsfusion-Netzwerk für hochpräzise inhaltsbasierte Bildsuche
Das richtige Bild schnell finden
Jeden Tag erzeugen und speichern wir eine beeindruckende Menge an Fotos – von medizinischen Aufnahmen und Satellitenbildern bis hin zu Überwachungsaufnahmen und persönlichen Schnappschüssen. Manuelles Verschlagworten und Suchen ist langsam und unzuverlässig. Dieses Paper stellt eine intelligentere Methode vor, mit der Computer Bilder direkt „betrachten“ und mit hoher Präzision die gesuchten Exemplare finden können – selbst in sehr großen und heterogenen Sammlungen.
Warum Pixelbetrachtung nicht ausreicht
Traditionelle Bildsuche verlässt sich oft auf Dateinamen oder einfache Schlagworte wie „Katze“ oder „Gebäude“. Menschen etikettieren Bilder aber nicht immer sorgfältig, und Computer sehen nur rohe Pixel, nicht die reichhaltige Bedeutung, die Menschen daraus erschließen. Frühere inhaltsbasierte Systeme versuchten, diese Lücke mit einfachen visuellen Merkmalen wie Farbe, Textur und Form zu überbrücken. Diese Hinweise halfen zwar, wurden aber meist mit festen Wichtigkeitsstufen kombiniert. Das bedeutet, das System behandelte bestimmte Merkmale stets als wichtiger als andere, selbst wenn eine bestimmte Suche von einer anderen Gewichtung profitiert hätte. In der Folge litt die Genauigkeit, wenn sich Bildtypen, Beleuchtung oder Szenen änderten.
Verschiedene Sichtweisen zusammenführen
Die Autoren schlagen ein neues Retrieval-Framework vor, das zwei Hauptarten visueller Hinweise fusioniert. Erstens nutzen sie Deep-Learning-Modelle – bekannte Netze wie ResNet50 und VGG16 –, die komplexe Muster in Bildern gelernt haben. Zweitens ergänzen sie klassische, manuell entwickelte Deskriptoren, die Farbverteilungen, Kanten und Texturen kontrollierter erfassen. Anstatt im Voraus zu raten, wie stark jede Merkmalart gewichtet werden sollte, lässt das System die Daten entscheiden. Es misst, wie informativ jedes Merkmal für eine gegebene Suche ist, und passt deren Einfluss dynamisch an. Diese mehrstufige Verbindung von High-Level- und Low-Level-Hinweisen hilft dem Computer, ein reichhaltigeres und flexibleres Verständnis davon zu entwickeln, was in einem Bild enthalten ist.
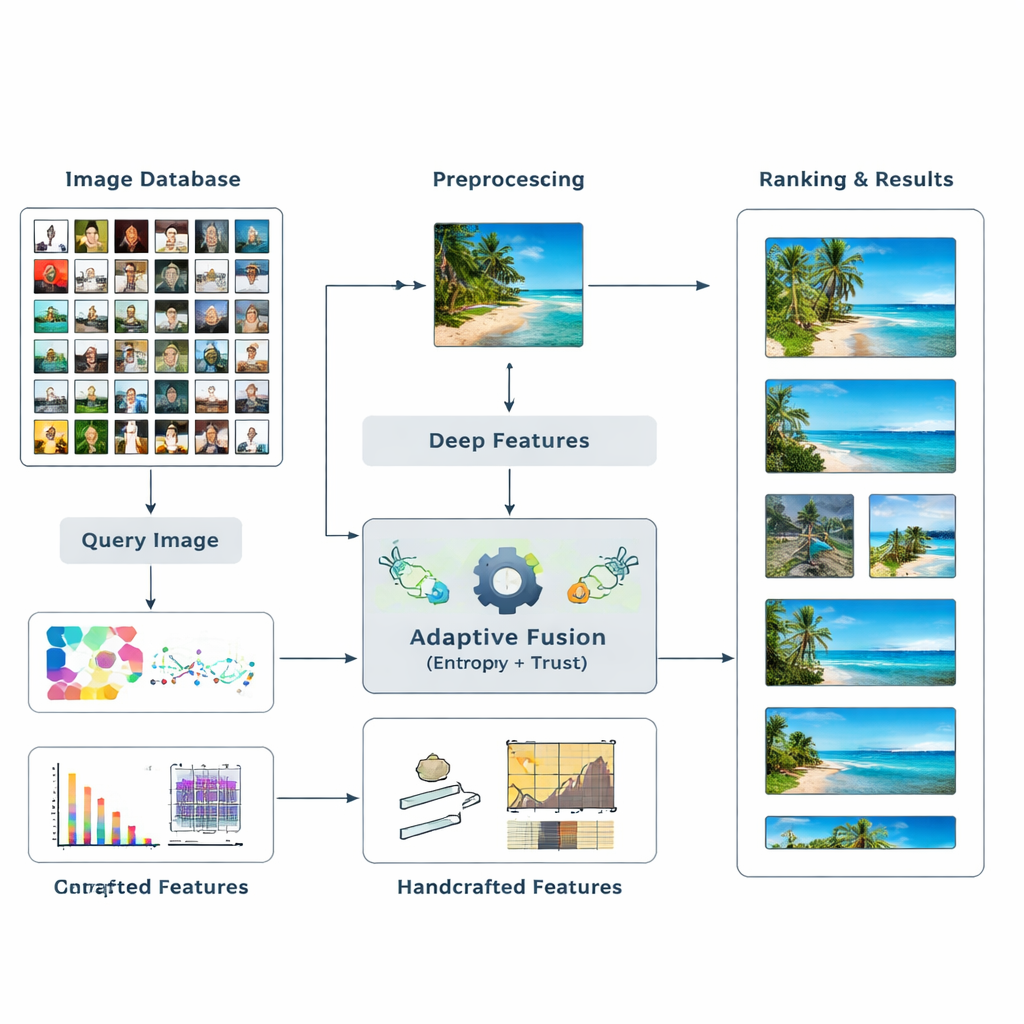
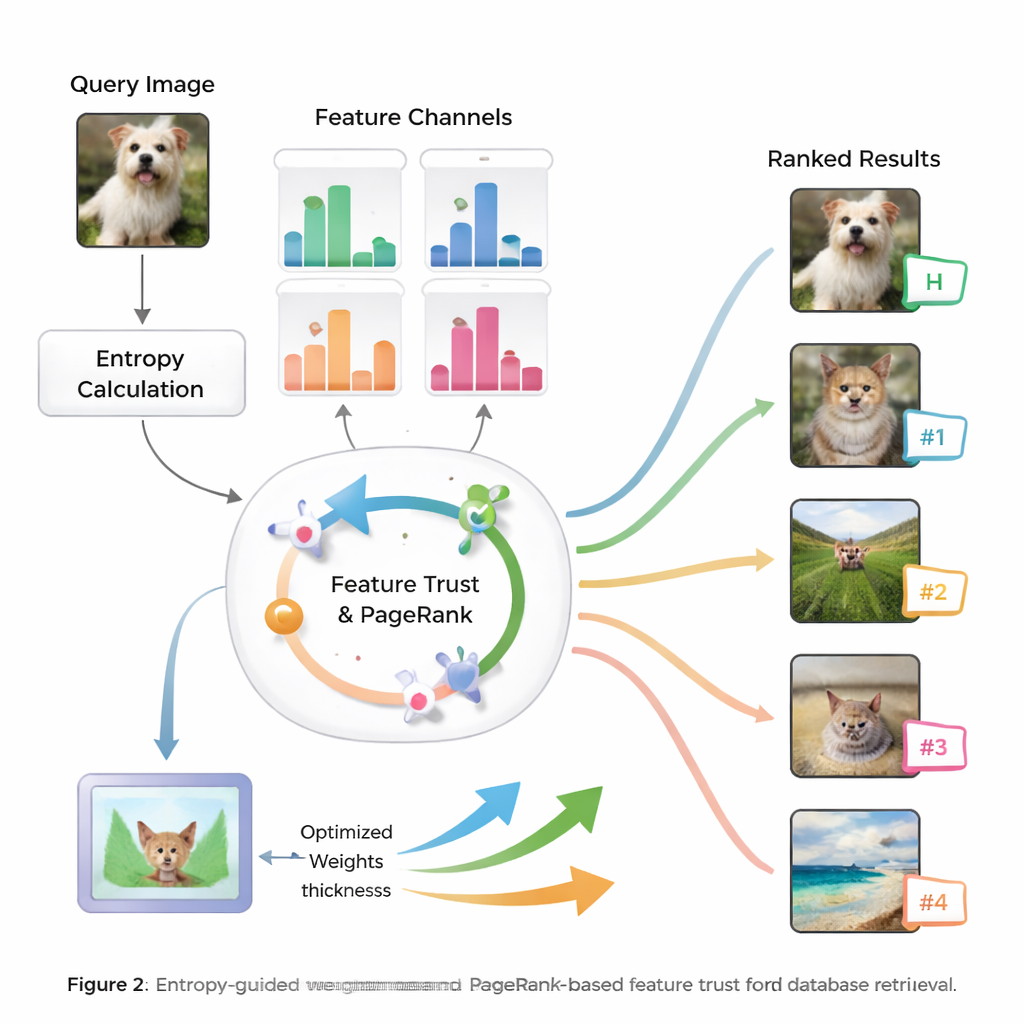
Information und Vertrauen bestimmen die Gewichte
Kern der Methode ist die Idee der Entropie, ein Maß dafür, wie unsicher oder verstreut Informationen sind. Merkmale, die zuverlässig relevante von irrelevanten Bildern trennen, haben eine geringere Entropie und gelten als stärker „diskriminativ“. Für eine neue Anfrage bewertet das System, wie sich jedes Merkmal über die Datenbank verhält, und weist ihm einen initialen Bedeutungswert zu. Anschließend untersucht es, wie verlässlich die Suchergebnisse jedes Merkmals sind – ob die besten Treffer tatsächlich dem Suchbegriff ähneln – und bildet so ein Vertrauen für jede Art von Hinweis. Diese Vertrauenswerte fließen in einen PageRank-ähnlichen Prozess ein, ähnlich dem Verfahren, mit dem frühe Web-Suchmaschinen Seiten nach Wichtigkeit ordneten, um die Merkmalsgewichte mittels eines Wahrscheinlichkeits-Transfernetzwerks zu verfeinern.
Von intelligenten Gewichten zu besseren Ranglisten
Sobald das System gelernt hat, wie sehr jedem Merkmal für die aktuelle Anfrage zu vertrauen ist, kombiniert es deren Similaritätswerte zu einer Gesamtbewertung für jedes Bild in der Datenbank. Bilder werden dann nach diesem umfassenden Score gereiht, sodass diejenigen, die der Anfrage auf die bedeutsamste Weise entsprechen, an die Spitze gelangen. Die Autoren testen ihren Ansatz auf weit verbreiteten Bildbenchmarks und vergleichen ihn mit mehreren bestehenden Methoden. Sie berichten von Verbesserungen von bis zu 8,6 % beim Mean Average Precision und merklichen Fortschritten bei der Qualität der Top-10-Ergebnisse, sowohl in Genauigkeit als auch in der Relevanz der Reihenfolge. Statistische Tests zeigen, dass diese Verbesserungen wahrscheinlich nicht zufällig sind, was darauf hindeutet, dass das System in vielen Bildkategorien sowohl präzise als auch stabil ist.
Was das für die tägliche Bildsuche bedeutet
Einfach gesagt zeigt diese Forschung, wie Bildsuchmaschinen entstehen können, die sich an jede Anfrage anpassen, statt sich auf starre Regeln zu stützen. Indem Informationsgehalt und gewonnenes Vertrauen entscheiden, welche visuellen Hinweise am wichtigsten sind, findet das System häufiger die richtigen Bilder – sei es beim Aufspüren eines Fingerabdrucks in einer großen Kriminaldatenbank, beim Lokalisieren eines bestimmten Gebäudes in Satellitenaufnahmen oder beim Abrufen der passenden medizinischen Aufnahme. Die Autoren räumen ein, dass die Methode rechenintensiver ist als einfachere Systeme, argumentieren jedoch, dass ihre höhere Zuverlässigkeit und Genauigkeit sie besonders geeignet für große, kritische Bildbestände macht, in denen das richtige Bild wirklich zählt.
Zitation: Lavanya, M., Vennira Selvi, G., Gopi, R. et al. Entropy guided multi level feature fusion network for high precision content based image retrieval. Sci Rep 16, 7449 (2026). https://doi.org/10.1038/s41598-026-38699-x
Schlüsselwörter: inhaltsbasierte Bildsuche, Deep Learning, Merkmalsfusion, Bildsuche, Entropiegewichtung