Clear Sky Science · de
ImageNet-Vortraining und zweistufiges Transferlernen bei der Klassifizierung von Chromosomenbildern
Scharfere Ansichten unserer Chromosomen
Unsere Chromosomen tragen die Bau- und Betriebsanleitungen für unseren Körper, und Ärztinnen und Ärzte untersuchen ihre Formen, um genetische Störungen und bestimmte Krebsarten zu erkennen. Heute können Computer beim Lesen von Chromosomenbildern helfen, doch sie gut darin zu trainieren ist schwierig, weil medizinische Bilder knapp sind und sich stark von Alltagsfotos unterscheiden. Diese Studie stellt eine einfache Frage mit großer praktischer Relevanz: Können Computer besser aus verwandten medizinischen Bildern lernen und nicht nur aus riesigen Sammlungen von Katzen-, Hunde- und Autofotos?
Warum Chromosomenbilder wichtig sind
In Krankenhäusern ordnen Spezialisten die 46 Chromosomen einer Person zu einer Tabelle, dem Karyotyp, gruppiert in 24 Typen (22 nummerierte Paare plus X und Y). Feine Hell-Dunkel-Streifen entlang jedes Chromosoms helfen, fehlende oder zusätzliche Abschnitte zu erkennen, die mit Erkrankungen wie dem Down-Syndrom oder bestimmten Leukämien verbunden sind. Traditionell klassifizieren Expertinnen und Experten diese Banden visuell, was langsam und subjektiv ist. Deep Learning bietet einen Weg zur Automatisierung, doch diese Systeme starten meist mit Modellen, die auf ImageNet trainiert wurden, einem riesigen Datensatz von Alltagsaufnahmen. Dieser Sprung – von Urlaubsfotos zu mikroskopischen Chromosomenansichten – ist groß, und es ist unklar, wie gut diese Erfahrung tatsächlich übertragbar ist.
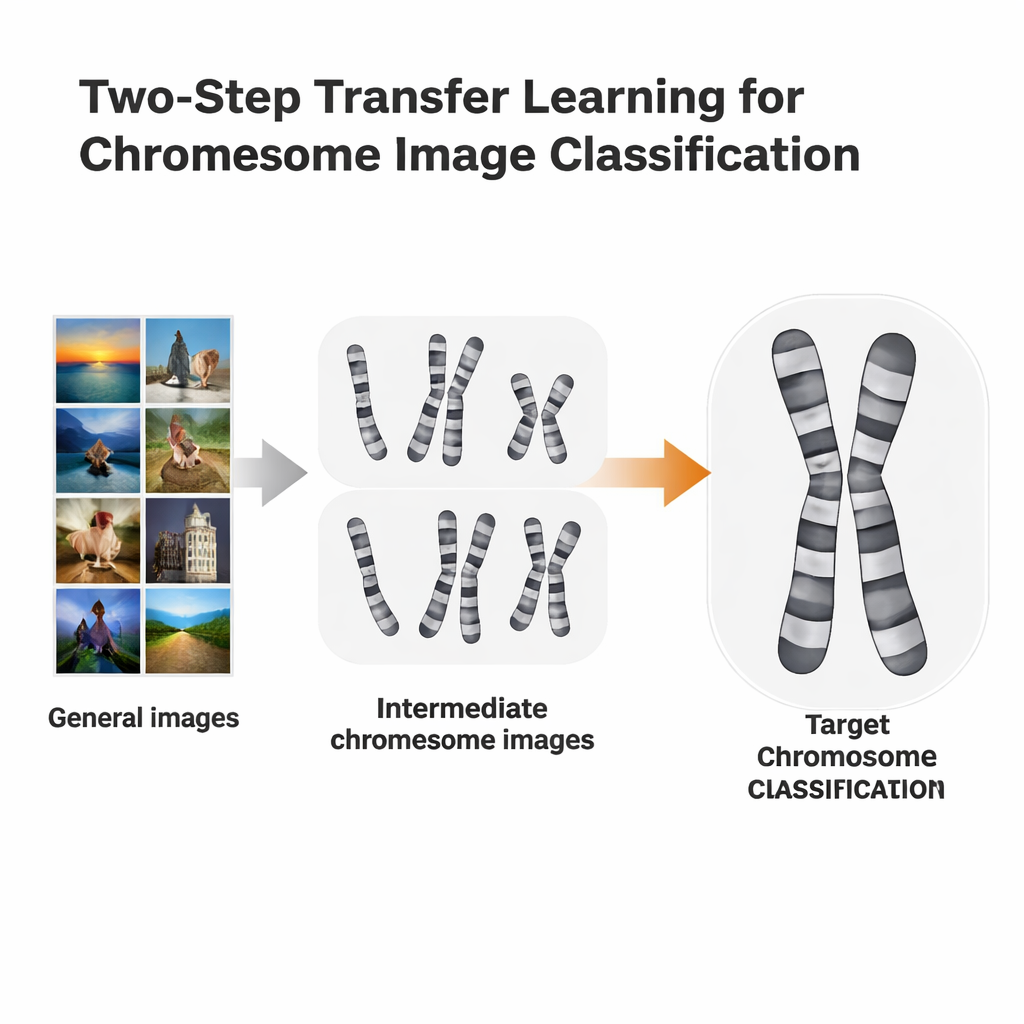
Eine zweistufige Lernabkürzung
Die Forschenden prüften einen gezielteren Trainingsweg, das sogenannte zweistufige Transferlernen. Anstatt direkt von ImageNet zu einer konkreten Chromosomenaufgabe zu wechseln, feinabstimmten sie ImageNet-vortrainierte Modelle zunächst auf Chromosomenbilder einer Färbemethode und passten sie danach erneut an eine zweite, leicht unterschiedliche Methode an. Sie verwendeten zwei offene Datensätze: Q-Band-Bilder, die von geringerer Qualität und schwerer zu lesen sind, und G-Band-Bilder, die sauberer und detailreicher sind. Jeder Datensatz diente abwechselnd als „Zwischenstufe“ für den anderen. Die Idee ähnelt dem Sprachenlernen: Wenn man bereits Spanisch kann, ist es oft leichter, Italienisch zu lernen, als direkt von Englisch zu starten.
Viele Computer-„Augen“ getestet
Um zu erkennen, wann dieser zusätzliche Schritt hilft, trainierte das Team 66 verschiedene Klassifizierer, indem es 11 populäre Neuronetz-Architekturen mit drei Strategien kombinierte: von Grund auf neu, Feinabstimmung nur von ImageNet und zweistufiges Transferlernen. Die Leistung wurde mit dem Macro-F1-Wert gemessen, einer Metrik, die alle Chromosomentypen fair berücksichtigt, einschließlich seltener Klassen. Zuerst bestätigten sie, dass sich Q- und G-Band-Bilder statistisch näher sind als jeweils zu ImageNet-Fotos, was sie zu vielversprechenden Zwischenstufen macht. Anschließend verglichen sie, wie gut die verschiedenen Modelle unter jeder Strategie sowohl auf dem einfachen (G-Band) als auch auf dem schwierigen (Q-Band) Datensatz lernten.
Wann sich der zusätzliche Schritt auszahlt
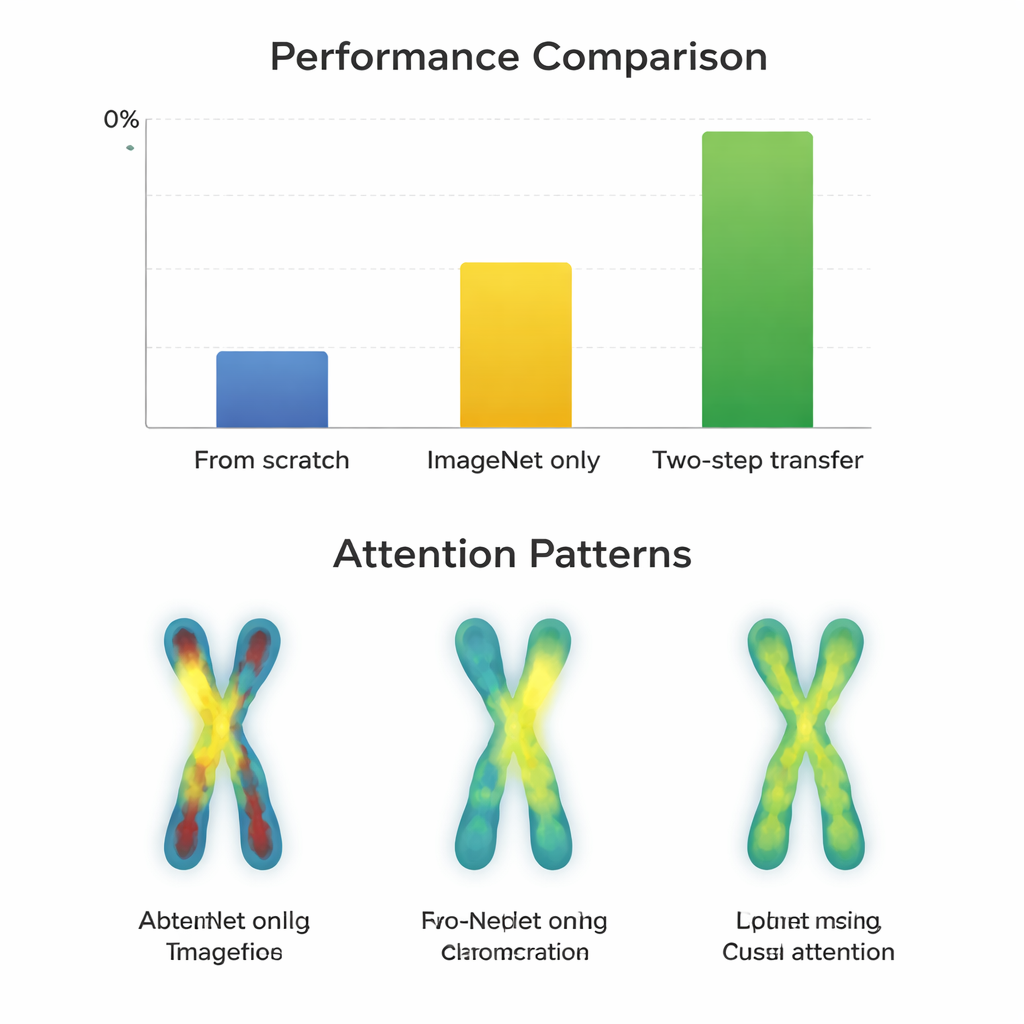
Bei den höherwertigen G-Band-Bildern erreichten fast alle Modelle nach einfacher ImageNet-Feinabstimmung bereits sehr gute Ergebnisse, mit Werten um 97–98 Prozent. Hier brachte das zweistufige Training nur geringe Verbesserungen – oft weniger als ein Prozentpunkt – und schadete manchmal sogar älteren Netzwerkdesigns. Anders sah es bei den anspruchsvolleren Q-Band-Bildern aus. Moderne, kompakte Architekturen wie ConvNeXt, Swin Transformer, Vision Transformer und MobileNetV3 profitierten deutlich vom zweistufigen Ansatz und verbesserten sich gegenüber nur ImageNet um etwa 0,8 bis 3,3 Prozentpunkte. Visuelle Karten der Aufmerksamkeitsbereiche erklärten warum: Mit zweistufigem Transfer fokussierten die Netze gleichmäßiger entlang der Banden beider Chromosomenarme, statt nur auf Umrisse oder eine einzelne Region. Sehr große, ältere Netzwerke wie VGG gewannen dagegen nicht und wurden teils schlechter, was darauf hindeutet, dass durchdachtes Design reiner Größe überlegen sein kann.
Grenzen, die die Daten selbst setzen
Die Forschenden untersuchten auch Fehler bei G-Band-Bildern. Einige Ausfälle lagen nicht an der Lernstrategie, sondern an fehlerhaften Eingaben, etwa Chromosomen, die beim Trennen überlappender Formen schlecht zugeschnitten wurden. In solchen Fällen hatten alle Trainingsmethoden Schwierigkeiten, und die Aufmerksamkeitskarten waren zerstreut oder fokussierten irreführende Kanten. Das unterstreicht eine praktische Botschaft für Kliniken und Entwickler:innen: Selbst die beste Trainingspipeline kann schlechte Bildqualität oder Vorverarbeitungsfehler nicht vollständig ausgleichen, besonders bei moderat großen Datensätzen wie denen, die für Chromosomenbilder verfügbar sind.
Was das für die Praxis bedeutet
Für Nicht-Spezialistinnen und Nicht-Spezialisten ist die wichtigste Erkenntnis, dass intelligentes Wiederverwenden verwandter medizinischer Bilder automatisches Chromosomenlesen genauer machen kann – besonders wenn die Zielbilder verrauscht oder knapp sind und moderne, sorgfältig gestaltete neuronale Netze eingesetzt werden. Bei Bildern hoher Qualität kann ein Standard-ImageNet-Training bereits ausreichen. Arbeiten Pathologinnen und Pathologen jedoch mit schwierigeren Datensätzen, kann ein zusätzlicher Lernschritt mit einer eng verwandten Bildart dem Computer das „Sehen“ schärfen und die Leistung in den Bereich von 93–98 Prozent bringen. Dieser Ansatz lässt sich über Chromosomen hinaus auf viele Bereiche der medizinischen Bildgebung übertragen, in denen beschriftete Daten begrenzt sind, und könnte zuverlässige KI-Werkzeuge näher an die tägliche klinische Praxis bringen.
Zitation: Chen, T., Xie, C., Zhang, W. et al. ImageNet pre-training and two-step transfer learning in chromosome image classification. Sci Rep 16, 7572 (2026). https://doi.org/10.1038/s41598-026-38662-w
Schlüsselwörter: Chromosomenklassifizierung, medizinische Bildgebung KI, Transferlernen, Tiefenlernmodelle, Karyotypisierung