Clear Sky Science · de
FedSCOPE: Föderierte domänenübergreifende sequentielle Empfehlung mit entkoppeltem kontrastivem Lernen und datenschutzwahrender semantischer Verstärkung
Warum klügere, sicherere Empfehlungen wichtig sind
Jedes Mal, wenn Sie Filme durchsuchen, online einkaufen oder Rezensionen lesen, entscheiden Empfehlungssysteme unauffällig, was Ihnen als Nächstes angezeigt wird. Da unser digitales Leben sich über viele Apps und Webseiten erstreckt, könnten diese Systeme deutlich bessere Ergebnisse liefern, wenn sie aus all Ihren Aktivitäten gleichzeitig lernen könnten—ohne jemals Ihre privaten Daten offenzulegen. Dieses Papier stellt FedSCOPE vor, einen neuen Ansatz, mit dem verschiedene Plattformen bei Empfehlungen zusammenarbeiten können, der sowohl genauer ist als auch den Datenschutz der Nutzer stärker respektiert.
Das Problem heutiger Empfehlungssysteme
Die meisten aktuellen Empfehlungssysteme arbeiten innerhalb einer einzigen App oder Website und sehen nur einen engen Ausschnitt Ihres Verhaltens. Das führt zu Schwierigkeiten bei „Cold-Start“-Nutzern mit wenig Historie oder bei Nischenprodukten, mit denen nur wenige Nutzer interagieren. Wenn Unternehmen versuchen, Daten domänenübergreifend zu kombinieren—etwa Bücher und Filme oder Lebensmittel und Küchenutensilien—stoßen sie auf drei große Probleme: Daten sind oft sehr spärlich, verschiedene Plattformen haben sehr unterschiedliche Nutzerprofile und Aktivitäten, und strikte Datenschutzvorschriften machen es riskant, Rohdaten an einem Ort zu bündeln. Einfache Lösungen, wie das Hinzufügen derselben Menge datenschutzwahrender Störung für alle, führen meist entweder zu schwächerem Schutz oder beeinträchtigen die Genauigkeit stark.
Sprachmodelle die Lücken füllen lassen
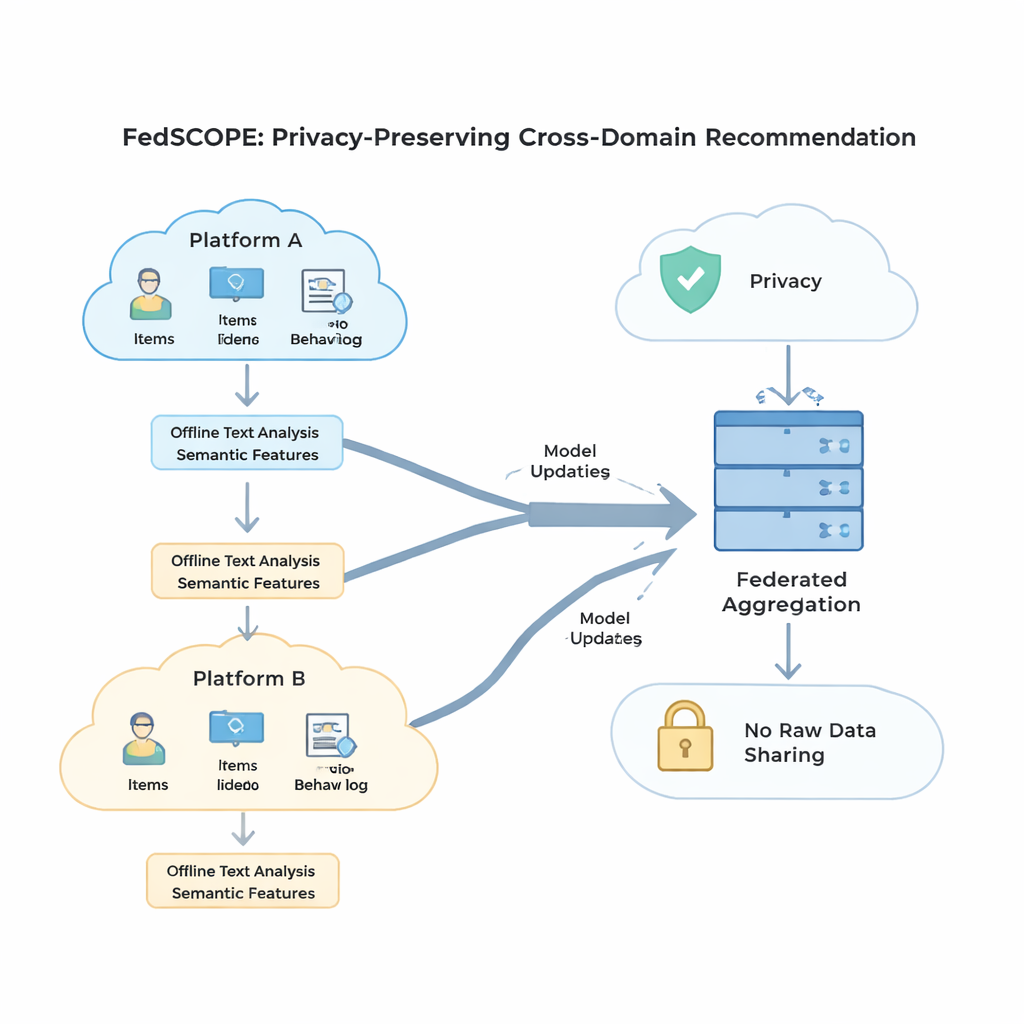
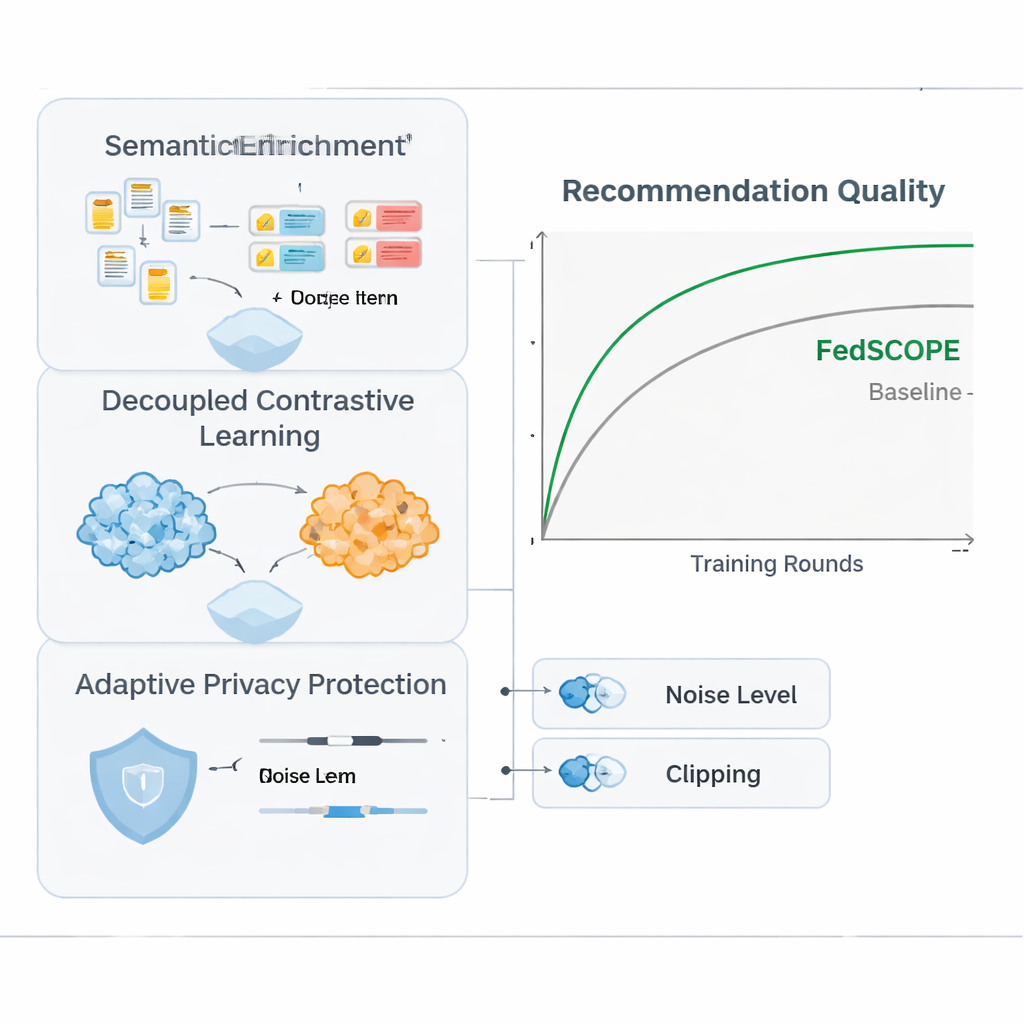
FedSCOPE geht das Sparsitätsproblem an, indem jede Plattform ihre Daten mithilfe eines großen Sprachmodells (LLM) anreichert—aber auf eine ungewöhnliche, datenschutzbewusste Weise. Anstatt Nutzerverläufe bei jeder Empfehlung an einen entfernten KI-Dienst zu senden, führt jeder Client einen einmaligen Offline-Prozess aus: Er übergibt Titel und grundlegende Artikeldaten (zum Beispiel den Namen und das Genre eines Films) an ein LLM und bittet um strukturierte Beschreibungen, wie wahrscheinliche Themen, Sehgewohnheiten oder verwandte Interessen. Diese generierten Attribute bleiben auf dem lokalen Gerät oder Server und werden mit den üblichen Klick- und Betrachtungshistorien über ein leichtgewichtiges neuronales Netzwerk verschmolzen. Das verschafft dem System ein reichhaltigeres Bild von Nutzern und Artikeln, was besonders hilfreich ist, wenn nur wenige Interaktionen vorliegen. Da der Prozess offline und lokal erfolgt, verlassen Rohverhaltensdaten nie die Plattform, und es besteht keine fortwährende Abhängigkeit von externen KI-Diensten.
Trennung von Persönlichem und Gemeinsamen
Um Verhaltensdaten aus mehreren Domänen zu nutzen, ohne Signale schädlich zu vermischen, führt FedSCOPE eine Trainingsstrategie namens entkoppeltes kontrastives Lernen ein. Einfach gesagt lernt das System zwei Dinge gleichzeitig. Erstens, innerhalb jeder Domäne—beispielsweise ausschließlich auf der Filmseite—zieht es Nutzer mit ähnlichem Verhalten zusammen und drückt jene auseinander, die sich unterscheiden, wodurch das Verständnis persönlicher Vorlieben innerhalb dieser Umgebung geschärft wird. Zweitens gleicht es domänenübergreifend Repräsentationen desselben Nutzers an, während verschiedene Nutzer weiterhin unterschieden bleiben, sodass das, was Sie schauen, dabei helfen kann vorherzusagen, was Sie lesen oder kaufen könnten, ohne Sie mit anderen zu verschmieren. Indem diese Ziele „innerhalb der Domäne‘‘ und „domänenübergreifend‘‘ getrennt behandelt werden, vermeidet die Methode eine häufige Falle, bei der das Erzwingen einer einzigen gemeinsamen Darstellung feingranulare Präferenzen zerstört.
Datenschutz schützen, ohne Nützlichkeit wegzuwerfen
Starker mathematischer Datenschutz, bekannt als differenzielle Privatsphäre, bedeutet typischerweise das Hinzufügen zufälligen Rauschens zu Modellupdates, bevor diese mit einem zentralen Server geteilt werden. Viele frühere Systeme nutzten dieselben Datenschutzeinstellungen für alle Teilnehmenden, was schlecht passt, wenn einige Clients Millionen von Nutzern und andere nur wenige Tausend haben. FedSCOPE vergibt stattdessen jedem Client ein personalisiertes Datenschutzbudget und passt das Clipping und die Störung seiner Updates basierend auf der Datengröße und dem bisherigen Verhalten an. Große, datenreiche Plattformen können präzisere Informationen beitragen, ohne übermäßig verrauscht zu werden, während kleinere stärker abgeschirmt werden. Alle Updates werden anschließend mittels sicherer Aggregation zusammengeführt, sodass der Server niemals einen einzelnen Beitrag im Klartext sieht.
Was die Experimente in der Praxis zeigen
Die Autoren testeten FedSCOPE mit realen Einkaufsdaten von Amazon und paarten Domänen wie Filme mit Büchern sowie Lebensmittel mit Küche. Sie verglichen das Verfahren mit einer Reihe moderner Empfehlungsansätze, einschließlich anderer datenschutzwahrender und domänenübergreifender Methoden. Über mehrere Genauigkeitsmaße hinweg rangierte FedSCOPE durchgängig an oder nahe der Spitze. Es konvergierte schneller während des Trainings, funktionierte besser für Nutzer mit sehr wenigen vergangenen Interaktionen und hielt sich robust, wenn sich die Zahl der teilnehmenden Clients oder der in jeder Runde beprobte Anteil änderte. Wichtig ist: Als das Team die Datenschutzanforderungen verschärfte, hielt FedSCOPEs adaptive Strategie die Leistung deutlich höher als Systeme mit einheitlicher differenzieller Privatsphäre.
Was das für Alltagnutzer bedeutet
Aus der Sicht einer Laienperson weist FedSCOPE in eine Zukunft, in der Ihre Lieblings-Apps zusammenarbeiten können, um Ihre Vorlieben tiefer zu verstehen—ohne jemals Ihre Rohdaten zu bündeln. Indem spärliche Verläufe mit Erkenntnissen aus Sprachmodellen angereichert, domänenspezifische von gemeinsamen Aspekten sorgfältig getrennt und Datenschutzkontrollen an jeden Teilnehmer angepasst werden, liefert das Framework Empfehlungen, die sowohl relevanter als auch respektvoller gegenüber persönlichen Informationen sind. Praktisch könnte das bessere Vorschläge dafür bedeuten, was Sie als Nächstes schauen, lesen oder kaufen sollten—ohne dass Sie Ihre digitale Privatsphäre opfern müssen.
Zitation: Zhao, L., Lin, Y., Qin, S. et al. FedSCOPE: Federated cross-domain sequential recommendation with decoupled contrastive learning and privacy-preserving semantic enhancement. Sci Rep 16, 7420 (2026). https://doi.org/10.1038/s41598-026-38628-y
Schlüsselwörter: föderierte Empfehlung, datenschutzfreundliche KI, domänenübergreifende Personalisierung, große Sprachmodelle, differenzielle Privatsphäre