Clear Sky Science · de
Untersuchung der Lehrer‑Schüler‑Interaktion mit multimodalen großen Sprachmodellen: eine empirische Studie
Warum es wichtig ist, Klassenzimmer mit KI zu beobachten
Wer schon einmal in einem Klassenzimmer gesessen hat, weiß, dass die Art und Weise, wie Lehrkräfte und Lernende miteinander interagieren, darüber entscheiden kann, ob Langeweile oder echtes Lernen entsteht. Dennoch ist es überraschend schwierig, diese Moment‑zu‑Moment‑Austausche zu erfassen: Beobachter ermüden, menschliche Bewertungen variieren, und Videodaten werden schnell unüberschaubar. Dieser Artikel untersucht, wie eine neue Art künstlicher Intelligenz—multimodale große Sprachmodelle, die Bilder „sehen“ und Text „lesen“ können—Forscherinnen, Forschern und Schulen helfen kann, das komplexe Klassenzimmerleben schneller und objektiver zu verstehen.
Alltägliche Unterrichtsstunden in Forschungsdaten verwandeln
Die Forschenden begannen mit gewöhnlichen Unterrichtsvideos aus chinesischen Grund‑ und Sekundarschulen, die auf einer nationalen Bildungsplattform öffentlich verfügbar waren. Aus 30 Unterrichtsstunden extrahierten sie knapp 2.400 Standbilder, die Schlüsselmomente von Lehren und Lernen einfingen. Jedes Bild wurde nach fünf eingängigen Interaktionsmustern beschriftet: gelenkt (Lehrkraft erklärt), kollaborativ (Schüler arbeiten zusammen), fragend (Fragen und Antworten), unabhängig (Schüler arbeiten allein) und präsentierend (Schüler präsentieren vor der Klasse). Expertinnen und Experten für Bildungstechnologie verfeinerten diese Kategorien, sodass sie dem entsprachen, worauf erfahrene Beobachter in realen Klassenzimmern achten.
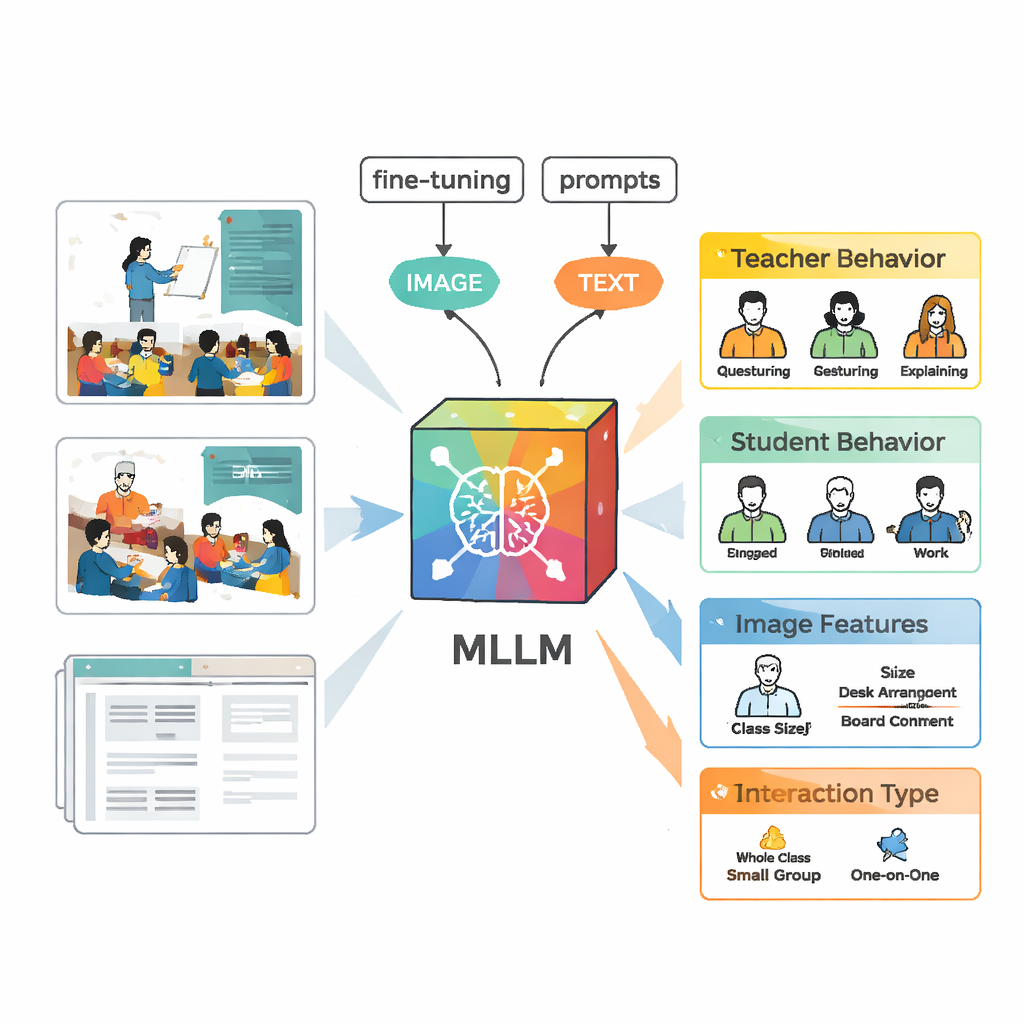
Der KI das Sehen von Klassenzimmerdynamiken beibringen
Um diese Szenen zu analysieren, nutzte das Team ein multimodales großes Sprachmodell namens VisualGLM‑6B, das sowohl Bilder als auch Text als Eingabe verarbeiten kann. Da das ursprüngliche Modell breit und nicht speziell auf Klassenzimmer trainiert war, „feinjustierten“ die Forschenden es mit ihren beschrifteten Bildern. Sie setzten eine Technik namens LoRA ein, die nur eine geringe Anzahl interner Modellparameter anpasst, wodurch das Training effizienter, aber weiterhin leistungsfähig bleibt. Außerdem entwarfen sie sorgfältige Prompts—strukturierte Anweisungen, die das Modell auffordern, Lehrer‑ und Schülerverhalten, visuelle Merkmale und die Art der Interaktion in einem konsistenten Format zu beschreiben, damit die Ausgaben leichter mit menschlichen Expertenurteilen verglichen werden können.
Bessere Labels durch Zusammenarbeit von Mensch und Maschine
Die Erstellung eines hochwertigen Trainingsdatensatzes erforderte mehr als nur das Zeigen von Videos an das Modell. Zuerst erzeugte VisualGLM grundlegende Beschreibungen jedes Bildes. Menschliche Annotatorinnen und Annotatoren korrigierten anschließend Fehler und ergänzten fehlenden Kontext, etwa wer spricht oder ob Schülerinnen und Schüler zuhören oder diskutieren. Danach fütterten sie diese überarbeiteten Beschreibungen in ChatGPT, das mit maßgeschneiderten Prompts strukturierte Analysen gemäß den fünf Interaktionskategorien erzeugte. Expertinnen und Experten überprüften und bearbeiteten diese KI‑generierten Analysen erneut. Das Endergebnis war ein reichhaltiger Datensatz, in dem jedes Bild eine detaillierte, verlässliche Darstellung dessen trägt, was Lehrkräfte und Lernende taten.
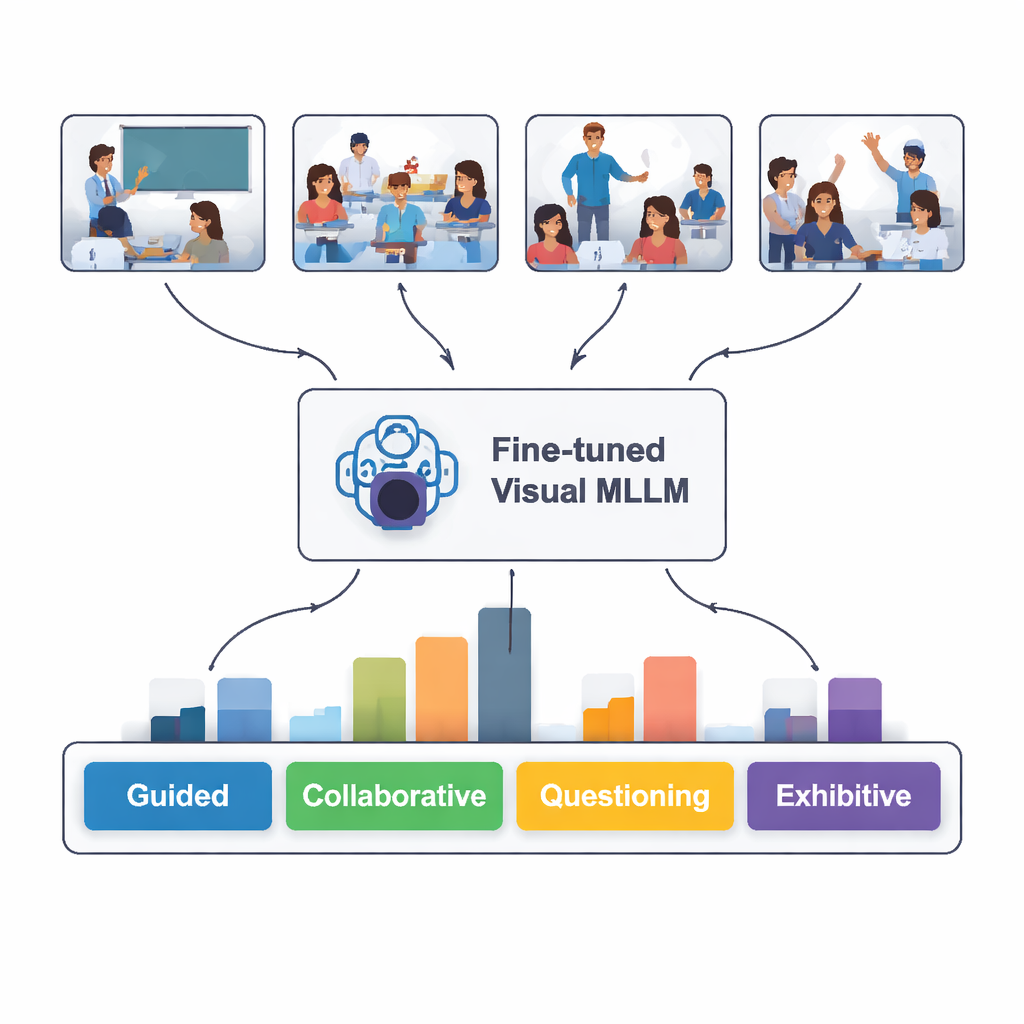
Wie gut „las“ die KI das Klassenzimmer?
Als das feinjustierte Modell an 100 neuen Klassenzimmerbildern getestet wurde, die es zuvor nie gesehen hatte, identifizierte es den Interaktionstyp in 82 Prozent der Fälle korrekt. Am besten erkannte es gelenkte, unabhängige und präsentierende Situationen—wenn die Lehrkraft klar erklärt, Schülerinnen und Schüler ruhig allein arbeiten oder ein/e Schüler/in vorne präsentiert. Bei kollaborativer Arbeit und Fragestellungen tat es sich schwerer, weil Körpersprache und Sitzordnung selbst für Menschen oft mehrdeutig sind. Ein tiefergehender textbasierter Vergleich zeigte, dass die schriftlichen Beschreibungen des Modells häufig sehr gut mit Expertenanalysen übereinstimmten, obwohl es gelegentlich Details „halluzinierte“, die nicht im Bild vorhanden waren, oder eine subtile Geste falsch interpretierte.
Was das für zukünftige Klassenzimmer bedeutet
Für eine allgemeine Leserschaft lautet die Kernbotschaft: KI‑Systeme werden zunehmend fähig, Klassenzimmer zu beobachten und zusammenzufassen, wie Lehren und Lernen sich entfalten—mit einer Struktur und Konsistenz, die für Menschen über Tausende von Szenen schwer aufrechtzuerhalten wäre. Zwar sind sie nicht perfekt—insbesondere bei subtilen Diskussions‑ und Fragestellungen—zeigt der Ansatz doch, dass multimodale große Sprachmodelle bereits die Bildungsforschung unterstützen und langfristig Instrumente für Feedback im Unterricht ermöglichen können. Wenn diese Modelle künftig auch Ton, Gesten und größere, vielfältigere Datensätze einbeziehen, könnten sie Lehrkräften helfen, Muster in ihrer Praxis zu erkennen, die zuvor verborgen waren, und eine neue Perspektive darauf bieten, wie alltägliche Interaktionen das Lernen von Schülerinnen und Schülern gestalten.
Zitation: Chen, G., Han, G., Niu, J. et al. Exploring teacher-student interaction through multimodal large language models: an empirical investigation. Sci Rep 16, 7602 (2026). https://doi.org/10.1038/s41598-026-38626-0
Schlüsselwörter: Lehrer‑Schüler‑Interaktion, Klassenraum-Analytik, multimodale KI, Bildungstechnologie, große Sprachmodelle