Clear Sky Science · de
Intelligente inkrementelle Klassifikation mittels eines dynamischen, von Heuschrecken verbesserten neuronalen Netzes für Datenströme
Warum ständig wechselnde Daten wichtig sind
Von Stromnetzen und Fabriken bis zu Online-Zahlungen erzeugen moderne Systeme jede Sekunde Daten. In diesen kontinuierlichen Datenströmen verbergen sich Frühwarnungen für Geräteausfälle, Cyberangriffe oder bevorstehende Preissprünge. Die Herausforderung ist, dass dieser Datenstrom nie endet und sein Verhalten sich im Laufe der Zeit verändert. Die hier zusammengefasste Arbeit stellt eine neue Methode vor, neuronale Netze so zu trainieren, dass sie kontinuierlich aus Live-Daten lernen können, ohne langsamer zu werden oder an Genauigkeit zu verlieren — was sie für Überwachung und Entscheidungsfindung in der Praxis nützlicher macht.
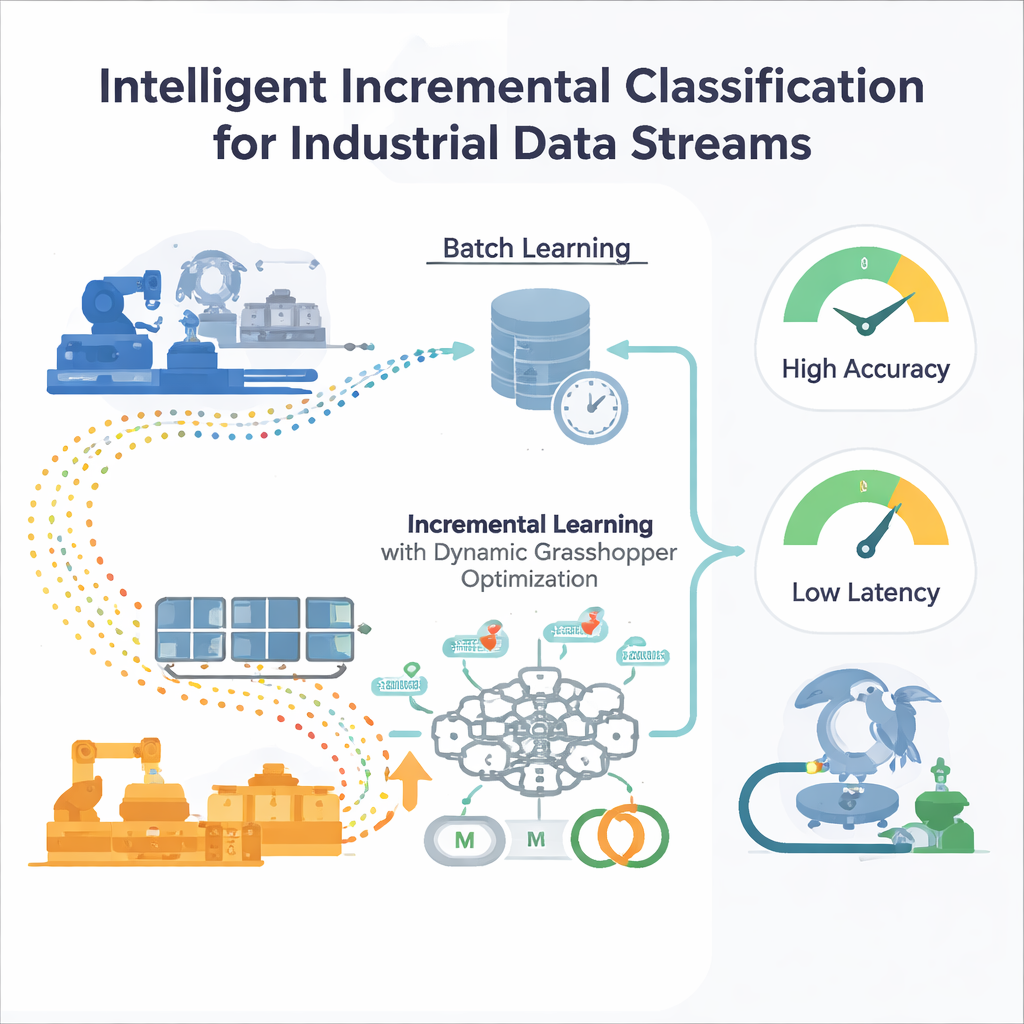
Die Grenzen einmaligen Trainings
Die meisten traditionellen Machine-Learning-Modelle werden in "Batches" trainiert: Ingenieure sammeln einen großen historischen Datensatz, optimieren das Modell und setzen es dann ein. Das funktioniert, solange sich die Welt ungefähr gleich bleibt. In industriellen Umgebungen driftet jedoch das Umfeld — Nachfrageprofile ändern sich, Sensoren altern, Märkte schwanken. Ein Modell, das eingefroren ist, wird nach und nach blind für neue Muster, und das erneute Training von Grund auf auf immer größeren Datensätzen ist teuer und langsam. Standardmethoden zur automatischen Parametereinstellung wie Grid Search oder evolutionäre Algorithmen gehen ebenfalls von festen Daten aus, was bedeutet, dass sie bei Verschiebungen in der Datenverteilung neu gestartet werden müssen — praktisch unmöglich für ständig laufende Systeme.
Ein neuronales Netz, das unterwegs lernt
Die Autoren schlagen ein inkrementelles Lernframework vor, das auf einem Multilayer Perzeptron (MLP) basiert, einer gängigen Form neuronaler Netze. Anstatt dem Netz alle historischen Daten auf einmal zu geben, wird der einlaufende Datenstrom in handhabbare Fenster unterteilt. Jedes neue Fenster wird zu einem kleinen Trainingsschritt, der die internen Gewichte des Netzes aktualisiert und dann verworfen wird — eine "train-and-forget"-Strategie, die den Speicherbedarf niedrig hält. Entscheidend ist, dass das System nicht auf festen Trainingseinstellungen beruht. Zwei zentrale Stellschrauben, die das Lernverhalten steuern — die Lernrate (wie groß jeder Update-Schritt ist) und der Momentum-Beiwert (wie gleichmäßig die Updates verlaufen) — werden kontinuierlich angepasst, während sich der Strom entwickelt, sodass das Modell reaktionsfähig bleibt, ohne instabil zu werden.
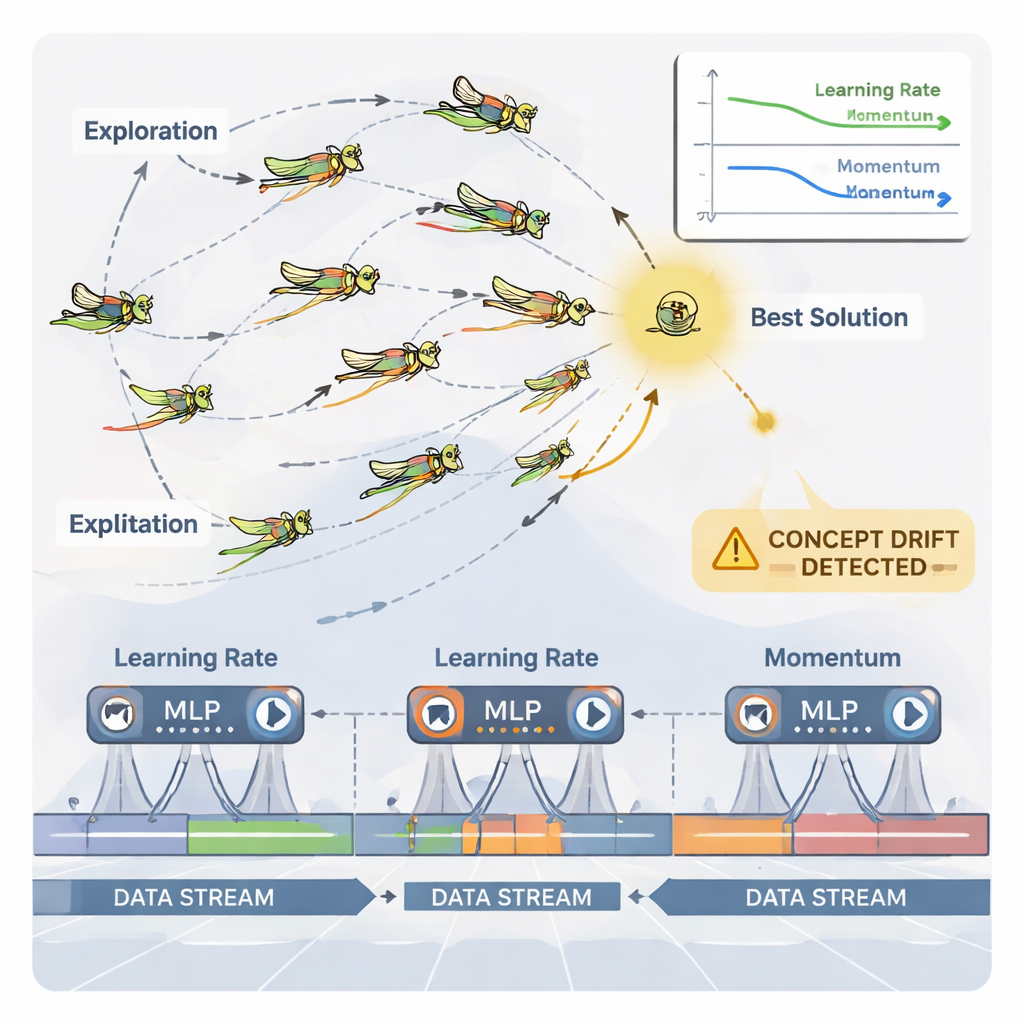
Heuschrecken als intelligente Parameter-Optimierer
Um diese kontinuierliche Anpassung zu bewältigen, verwendet die Arbeit einen naturinspirierten Optimierer namens Dynamic Grasshopper Optimization Algorithm (DGOA). Stellen Sie sich einen Schwarm virtueller Heuschrecken vor, der mögliche Kombinationen aus Lernrate und Momentum erkundet. Zu Beginn streifen sie weit, um vielversprechende Regionen zu finden; später verengen sie ihre Bewegungen, um die besten Optionen zu verfeinern. In dieser dynamischen Variante verändern sich ihre Schrittgrößen und ihre Anziehung zum bislang besten Lösungsbereich im Laufe der Zeit, abhängig davon, wie gut das neuronale Netz arbeitet. Das System überwacht außerdem "Concept Drift" — plötzliche Veränderungen in den Vorhersagefehlern oder in den Daten selbst. Wenn ein Drift erkannt wird, werden einige Heuschrecken zurückgesetzt und ihre Schritte vorübergehend vergrößert, sodass der Optimierer schnell neue Bereiche durchsuchen und veraltete Einstellungen verlassen kann.
Die Methode im Praxistest
Die Forschenden bewerteten ihren Ansatz an einem realen Datensatz aus dem australischen Strommarkt, wobei das Ziel war, vorherzusagen, ob die Preise steigen oder fallen würden. Im Vergleich zu gängigen Optimierungsverfahren wie Grid Search, Random Search, Particle Swarm Optimization, genetischen Algorithmen, Ameisenalgorithmus und dem klassischen Grasshopper-Algorithmus erzielte die dynamische Variante in Kombination mit inkrementellem Lernen die höchste Genauigkeit (etwa 89,5 %) und benötigte dabei weniger Rechenzeit und weniger Iterationen. Weitere Experimente zeigten, dass die Methode sich besser an stabile wie wechselnde Datenströme anpasst, von tausenden bis zu Milliarden von Proben skaliert und dabei den Speicherbedarf im Griff behält, und dass sie bei Aufgaben wie prädiktiver Wartung, Anomalieerkennung und Betrugserkennung sowie bei standardisierten mathematischen Optimierungsbenchmarks konkurrenzfähig ist.
Was das in der Praxis bedeutet
Für Nicht-Expertinnen und Nicht-Experten lautet die Schlussfolgerung: Diese Arbeit bietet einen Weg, neuronale Netze "lebendig" und gut abgestimmt zu halten in Umgebungen, in denen Daten nie aufhören und sich die Bedingungen ständig ändern. Anstatt das System wiederholt anzuhalten, um Modelle von Grund auf neu zu bauen, erlaubt das vorgeschlagene Framework einem schlanken Netz, sich Fenster für Fenster selbst zu aktualisieren, während ein schwarmbasierter Optimierer kontinuierlich regelt, wie schnell und wie gleichmäßig es lernt. Das Ergebnis ist eine schnellere Anpassung an neue Muster, bessere Langzeitgenauigkeit und effizientere Nutzung von Rechenressourcen — zentrale Voraussetzungen für verlässliche Entscheidungen in Echtzeit in Sektoren wie Energie, Fertigung und Finanzen.
Zitation: Darwish, S.M., El-Shoafy, N.A. Intelligent incremental classification using a dynamic grasshopper-enhanced neural network for data streams. Sci Rep 16, 7730 (2026). https://doi.org/10.1038/s41598-026-38571-y
Schlüsselwörter: Datenströme, inkrementelles Lernen, neuronale Netze, Hyperparameter-Optimierung, Schwarmintelligenz