Clear Sky Science · de
Ein erklärbares Machine‑Learning‑Modell auf Basis routinemäßiger klinischer Daten zur Vorhersage früher Rückfälle beim hepatozellulären Karzinom
Warum das für Patienten und Familien wichtig ist
Für Menschen, die sich einer Operation zur Entfernung von Leberkrebs unterziehen, ist eine der dringendsten Fragen: „Kommt der Krebs bald zurück?“ Heute können Ärztinnen und Ärzte meist nur grobe Abschätzungen anbieten, oft basierend auf weiten Stadieneinteilungen, die viele unterschiedliche Patientinnen und Patienten gleich behandeln. Diese Studie stellt eine neue Methode vor, um bereits im Krankenhaus verfügbare Informationen – routinemäßige Blutwerte und Befunde aus Bildgebung – gemeinsam mit erklärbarer künstlicher Intelligenz zu nutzen, um jeder Person ein klareres, individuelleres Bild ihres kurzfristigen Rückfallrisikos zu geben.
Ein häufiger Krebs mit hartnäckiger Rückfallrate
Das hepatozelluläre Karzinom ist die häufigste Form des primären Leberkrebses und eine bedeutsame Ursache für Krebstodesfälle weltweit. Selbst wenn Chirurgen sichtbare Tumoren vollständig entfernen, tritt die Erkrankung bei mehr als 70 % der Patienten innerhalb von fünf Jahren wieder auf. Frühe Rezidive – etwa innerhalb von zwei Jahren nach der Operation – sind besonders besorgniserregend, weil sie meist aggressive Krebszellen widerspiegeln, die bereits innerhalb der Leber gestreut haben, und die Überlebensprognose deutlich verschlechtern. Bestehende klinische Stadieneinteilungen, wie TNM oder das Barcelona Clinic Liver Cancer (BCLC)‑System, können Patientinnen und Patienten grob kategorisieren, bleiben aber oft ungenau darin, wer tatsächlich ein hohes Risiko für ein frühes Wiederauftreten trägt.
Alltägliche Testergebnisse in einen Risikoscore verwandeln
Die Forscherinnen und Forscher nutzten Daten von 1.120 Patientinnen und Patienten, die zwischen 2014 und 2024 an zwei großen Krankenhäusern in China offenbar kurativ operiert wurden. Sie beschränkten sich auf Informationen, die vor der Operation verfügbar waren: Alter und Geschlecht, Bildgebungsmerkmale wie der Durchmesser des größten Tumors und das Vorliegen multipler Tumoren sowie ein breites Panel standardmäßiger Laborwerte, die in den Tagen vor der Operation erhoben wurden. Aus diesen Variablen suchten sie neun Schlüsselfaktoren, die mit der Rückfallwahrscheinlichkeit verknüpft waren. Statt sich auf eine einzige mathematische Formel zu stützen, kombinierten sie drei verschiedene Machine‑Learning‑Ansätze und bildeten aus deren Ergebnissen einen gemittelten Risikoscore zwischen 0 und 1. Auf Basis dieses Scores wurden Patientinnen und Patienten in Niedrig‑, Mittel‑ und Hochrisikogruppen eingeteilt. 
Besser als standardmäßige Stadieneinteilungen
Um die Leistungsfähigkeit des Modells zu prüfen, bewertete das Team es zuerst an einem „Hold‑out“‑Datensatz aus dem ursprünglichen Krankenhaus und anschließend an einer unabhängigen Gruppe aus dem zweiten Krankenhaus. In beiden Situationen war das neue Modell deutlich besser als traditionelle Stadieneinteilungen darin, zu unterscheiden, wer innerhalb von 24 Monaten krebsfrei bleiben und wer einen Rückfall erleiden würde. In der internen Testgruppe lag die zeitabhängige Genauigkeit des Modells, gemessen mit einer gebräuchlichen Kennzahl (Area under the Curve), bei etwa 0,76, verglichen mit circa 0,55 bis 0,64 für gängige Stadienmethoden. Personen in der Hochrisikogruppe hatten das schlechteste rezidivfreie Überleben; die Hazard für ein Wiederauftreten war in der Mittelrisikogruppe um etwa 60 % reduziert und in der Niedrigrisikogruppe im Vergleich zur Hochrisikogruppe um etwa 90 % niedriger. Diese deutlichen Unterschiede zeigten sich auch im externen Krankenhaus und blieben in den meisten Subgruppen konsistent, etwa bei jüngeren und älteren Patientinnen und Patienten, bei Männern und Frauen sowie bei großen oder kleinen Tumoren.
Die Black Box der künstlichen Intelligenz öffnen
Ein häufiger Kritikpunkt an Machine Learning in der Medizin ist, dass es wie eine Black Box wirkt: Die Vorhersagen können gut sein, aber selbst Fachleute sehen oft nicht, warum. Um dem zu begegnen, wandten die Autorinnen und Autoren eine Methode namens SHapley Additive exPlanations (SHAP) an, die jede Vorhersage in Beiträge der einzelnen Eingangsgrößen zerlegt. Die Analyse zeigte, dass die Tumorgröße der stärkste Einzeltreiber für ein erhöhtes Risiko in allen drei Algorithmen war, gefolgt von Merkmalen wie der Anzahl der Tumoren sowie blutbasierten Indikatoren für Leberfunktion und Entzündung. Interessanterweise wirkte sich der Natrium‑Chlorid‑Spiegel im Blut in dieser Datengrundlage tendenziell in die entgegengesetzte Richtung aus und schien einen schützenden Effekt zu haben. Für einzelne Patientinnen und Patienten kann das Modell einfache balkenartige Grafiken erzeugen, die beispielhaft zeigen, wie ein großer Tumurdurchmesser und ungünstige Blutwerte den Risikoscore nach oben treiben, während bessere Leberwerte ihn senken. 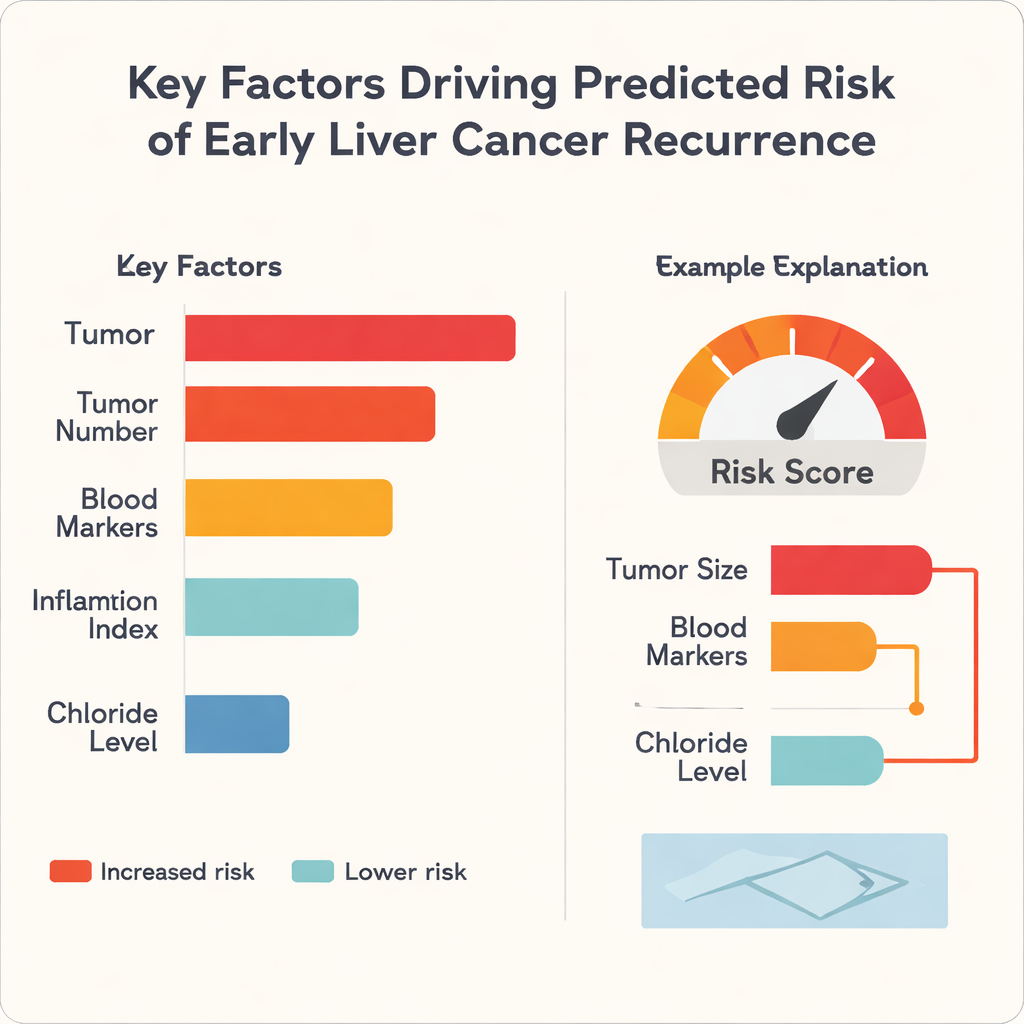
Was das in der Klinik bedeuten könnte
Weil das Modell mit Daten arbeitet, die Krankenhäuser ohnehin erheben, und keine speziellen Bildgebungsmethoden oder teure Gentests erfordert, könnte es in vielen Versorgungsumgebungen eingesetzt werden – auch dort mit begrenzten Ressourcen. Vor der Operation könnten Ärztinnen und Ärzte damit Personen identifizieren, die intensivere Nachsorgetermine benötigen oder nach der Operation von zusätzlichen Behandlungen profitieren könnten, während wirklich niedrig‑riskante Patientinnen und Patienten vor unnötigen Untersuchungen und vermehrter Sorge bewahrt würden. Die Autorinnen und Autoren weisen darauf hin, dass ihre Studie retrospektiv ist und aus einer spezifischen Patientengruppe stammt, sodass prospektive Studien in vielfältigeren Populationen noch erforderlich sind. Nichtsdestoweniger zeigt ihre Arbeit, wie transparente, erklärbare KI vertraute Laborzahlen und Befunde aus der Bildgebung in aussagekräftige, individualisierte Prognosen verwandeln kann, die die gemeinsame Entscheidungsfindung zwischen Patientinnen und Patienten und ihren Behandlungsteams unterstützen.
Zitation: Guo, DF., Wen, Q., Zhang, X. et al. An interpretable machine learning model using routine clinical data for early recurrence prediction in hepatocellular carcinoma. Sci Rep 16, 7520 (2026). https://doi.org/10.1038/s41598-026-38484-w
Schlüsselwörter: Rückfall von Leberkrebs, Machine‑Learning‑Modell, klinische Risikovorhersage, erklärbare KI, hepatozelluläres Karzinom