Clear Sky Science · de
Ein erklärbares hybrides CNN–Transformer‑Modell zur Zeichensprachenerkennung auf Edge‑Geräten mit adaptiver Fusion und Wissensdistillation
Warum kleine Gebärdensprach‑Tools wichtig sind
Milliarden täglicher Gespräche stützen sich eher auf Handbewegungen, Gesichtsausdrücke und Körpersprache als auf gesprochene Wörter. Dennoch können die meisten Telefone, Tablets und öffentlichen Geräte Gebärdensprachen noch nicht verstehen, besonders außerhalb englischsprachiger Länder. Dieses Papier stellt TinyMSLR vor, ein kompaktes und erklärbares System zur Gebärdensprachenerkennung, das in Echtzeit auf kleinen, energiearmen Geräten laufen soll. Ziel ist es, gewöhnliche Hardware in erschwingliche, vertrauenswürdige Kommunikationshilfen für Gehörlose und schwerhörige Menschen weltweit zu verwandeln.
Mehr Sprachen ins Gespräch bringen
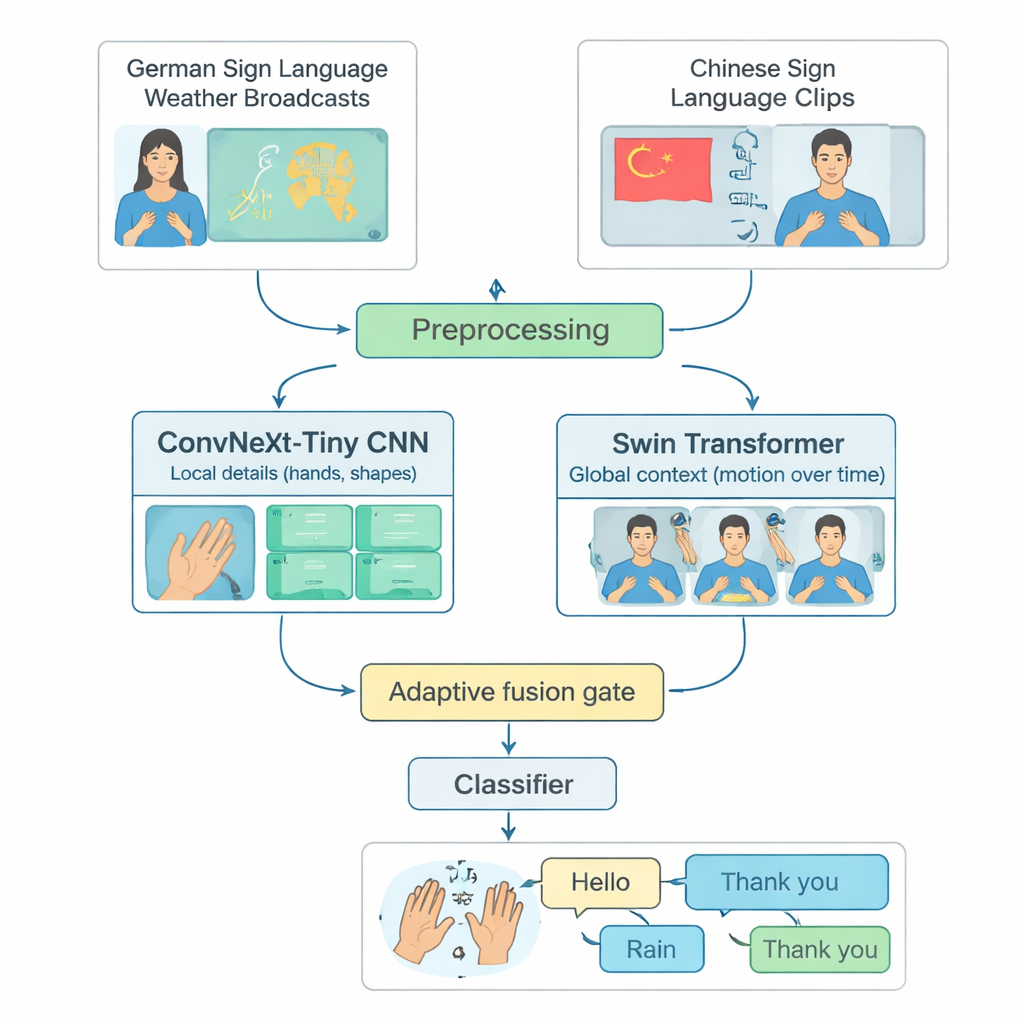
Viele fortgeschrittene Systeme zur Gebärdensprachenerkennung konzentrieren sich auf eine einzelne Sprache, meist American Sign Language, und laufen nur auf leistungsfähigen Computern. Damit bleiben Menschen außen vor, die andere Gebärdensprachen verwenden oder in Regionen mit begrenzten Rechenressourcen leben. Die Autorinnen und Autoren schließen diese Lücke, indem sie ein gemeinsames Testbett aus zwei unterschiedlichen Sprachen aufbauen: Wetterübertragungen in Deutscher Gebärdensprache und eine große Sammlung der Chinesischen Gebärdensprache. Sie wählen sorgfältig 20 gebräuchliche Alltagszeichen aus — etwa Hallo, Wetter, Regen, Glücklich, Ja und Danke —, die in beiden Sprachen existieren. Durch das Beschneiden langer Videos in kurze Clips mit genau einem Zeichen und das Ausbalancieren der Anzahl von Beispielen pro Klasse und pro Zeichner schaffen sie eine faire, reproduzierbare Methode, um zu beurteilen, wie gut ein Modell isolierte Zeichen über Sprachen hinweg erkennen kann.
Wie das hybride Modell Hände und Bewegung sieht
TinyMSLR kombiniert zwei ergänzende Betrachtungsweisen von Video. Ein Zweig nutzt ein modernes Faltungsnetzwerk (ConvNeXt‑Tiny), das besonders gut feine Details erkennt, etwa Fingerformen und subtile Texturen. Der zweite Zweig verwendet einen Swin Transformer, eine neuere Modellfamilie, die Muster über Raum und Zeit gut verfolgt — wie sich Hände, Gesicht und Oberkörper über mehrere Frames bewegen. Jeder kurze Videoclip wird auf 32 Frames mit 224×224 Pixeln standardisiert, sanft augmentiert (zum Beispiel kleine Drehungen oder Helligkeitsänderungen) und dann parallel beiden Zweigen zugeführt. Jeder Zweig erzeugt eine 768‑wertige Zusammenfassung dessen, was er sieht; zusammen fangen diese beiden Zusammenfassungen sowohl klare lokale Details als auch umfassendere Bewegungs‑ und Kontextinformationen ein.
Das Modell entscheiden lassen, was am wichtigsten ist
Da sich manche Zeichen hauptsächlich durch die Handform unterscheiden, andere durch größere Armbewegungen oder Gesichtssignale, legt TinyMSLR keine feste Regel zur Kombination seiner beiden Sichtweisen fest. Stattdessen verwendet es ein kleines „Fusionsgatter“, das für jeden Eingabeclip lernt, wie viel Vertrauen dem detailfokussierten gegenüber dem kontextfokussierten Zweig zu schenken ist. Das Gatter betrachtet beide Merkmalszusammenfassungen und gibt zwei Gewichte aus, die stets eins ergeben; die finale Repräsentation ist eine gewichtete Mischung der beiden. Während des Trainings erhält jeder Zweig außerdem einen eigenen kleinen Klassifikator, sodass er lernt, eigenständig nützlich zu sein, und ein Paar größerer „Teacher“‑Netzwerke (jeweils ein CNN und ein Transformer) leiten das kleine Modell sanft an, indem sie nicht nur das richtige Label, sondern auch ähnliche Alternativlabels anzeigen. Diese Technik, Wissensdistillation genannt, hilft dem kompakten System, die Genauigkeit schwererer Modelle zu erreichen, während Größe und Geschwindigkeit für Edge‑Geräte erhalten bleiben.
Nachvollziehbar machen, warum das System eine Entscheidung trifft
Über die reine Genauigkeit hinaus betonen die Autorinnen und Autoren, dass Nutzer und Entwickler einsehen können sollten, worauf das Modell seine Aufmerksamkeit richtet. Sie verwenden SHAP, eine Werkzeugfamilie, die jedem Teil der Eingabe einen Wichtigkeitswert zuordnet. In der Praxis berechnen sie diese Erklärungen auf Zwischen‑Features und projizieren sie als Heatmaps und zeitliche Darstellungen zurück auf die Frames. Das zeigt zum Beispiel, welche Frames und Bildregionen die Entscheidung zwischen visuell ähnlichen Zeichen wie Regen und Schnee oder Kalt und Schlecht vorantreiben. Die Aggregation vieler Erklärungen offenbart breitere Muster: non‑manuelle Hinweise wie Mimik und Kopfbewegung sowie Handgelenksorientierung und Handform erweisen sich als besonders einflussreich. Diese Einsichten helfen zu verifizieren, dass das System sich auf sinnvolle Aspekte des Gebärdens stützt und nicht auf Hintergrundartefakte.

Geschwindigkeit, Sparsamkeit und Entwicklungsspielraum
Auf dem bilingualen 20‑Zeichen‑Benchmark erreicht TinyMSLR rund 99 % Trainings‑ und Validierungsgenauigkeit sowie einen F1‑Score nahe 99 %, während es weniger als 2,7 Millionen Parameter und etwa 1,9 Milliarden Operationen pro Clip verwendet. Auf einer modernen GPU verarbeitet es ein Zeichen in etwa 13,5 Millisekunden und verbraucht dabei unter 30 Millijoule Energie; das gespeicherte Modell ist nur ungefähr 7,2 Megabyte groß. Diese Zahlen deuten darauf hin, dass Echtzeit‑On‑Device‑Zeichenerkennung auf kostengünstigen Boards und Embedded‑Systemen möglich ist. Die Autorinnen und Autoren weisen darauf hin, dass ihre Arbeit nur kurze, isolierte Zeichen und zwei Sprachen abdeckt und mimische Ausdrücke implizit statt als separates Signal behandelt. Die Erweiterung auf reichere Vokabulare, kontinuierliche Sätze, mehr Sprachen und explizite Modellierung von Mimik und Kopfbewegungen ist künftige Arbeit. Dennoch bietet TinyMSLR einen überzeugenden Proof of Concept: genaue, effiziente und interpretierbare Werkzeuge zum Verstehen von Gebärdensprachen müssen nicht in der Cloud verbleiben — sie können direkt auf Alltagsgeräten laufen.
Zitation: Lamaakal, I., Yahyati, C., Maleh, Y. et al. An explainable hybrid CNN–transformer model for sign language recognition on edge devices using adaptive fusion and knowledge distillation. Sci Rep 16, 7143 (2026). https://doi.org/10.1038/s41598-026-38478-8
Schlüsselwörter: Erkennung von Gebärdensprachen, Tiny Machine Learning, Edge‑KI, erklärbare KI, mehrsprachige Modelle