Clear Sky Science · de
SAT: Shift-Alignment-Transformer für Videorauschreduzierung ohne Fluss-Schätzung
Scharfere Videos aus verrauschten Szenen
Wer schon einmal nachts drinnen oder mit einem Smartphone bei wenig Licht gefilmt hat, kennt das Ergebnis: körnige, flackernde Aufnahmen, in denen Details zu zittern scheinen und Farben nicht stimmen. Dieses Papier stellt eine neue Methode vor, um solche Videos zu säubern und in klarere, stabilere Sequenzen zu verwandeln, ohne auf die aufwändige Bewegungsverfolgungssoftware zurückzugreifen, die das bisher oft erst ermöglicht. Die Methode, genannt Shift Alignment Transformer, ist darauf ausgelegt, feine Details zu erhalten und gleichzeitig effizient genug zu laufen, um praktisch einsetzbar zu sein.
Warum Videorestauration so schwierig ist
Rauschen aus einem einzelnen Foto zu entfernen ist bereits eine Herausforderung; für Video gilt das umso mehr. Einerseits ist jedes Frame durch zufällige Körnchen und Farbverschiebungen beeinträchtigt. Andererseits sind die Frames zeitlich verknüpft: Objekte bewegen sich, die Kamera wackelt, und Details tauchen auf oder verschwinden. Traditionelle Verfahren zur Videorauschreduzierung stützen sich oft auf die Schätzung von Bewegung zwischen Frames, häufig über ein Verfahren namens optischer Fluss, das versucht, die Verschiebung jedes Pixels von einem Frame zum nächsten zu verfolgen. Solche Bewegungsabschätzungen sind zwar mächtig, können aber schnell versagen, wenn das Video sehr verrauscht ist oder die Bewegung schnell und komplex verläuft, außerdem verursachen sie einen großen Rechenaufwand, der Systeme stark verlangsamen kann.
Eine neue Art der Ausrichtung ohne Tracking
Statt explizit jedem Pixel zu folgen, geht der Shift Alignment Transformer (SAT) einen anderen Weg: Er lässt das Netzwerk implizit entdecken, wie Frames zueinander stehen, indem es Merkmale gezielt verschiebt und vergleicht. Das Modell basiert auf einer modernen Architektur, dem Transformer, der besonders gut darin ist, langreichweitige Verknüpfungen in Daten zu finden. Innerhalb dieses Rahmens führen die Autoren ein räumlich-zeitliches Shift-Modul (Spatial-Temporal Shift Module) ein, das Informationen sanft über Zeit und Raum verteilt. In der Zeit verschiebt das Modell Frame-Features zyklisch, sodass Schicht für Schicht jedes Frame weiter in die Vergangenheit und Zukunft „sehen“ kann. Im Raum teilt es Features in viele kleine Gruppen und verschiebt jede Gruppe in verschiedene Richtungen. Diese Kombination ahmt effektiv nach, wie sich Objekte im Video bewegen könnten, und erlaubt dem Netzwerk, Informationen aus unterschiedlichen Frames auszurichten, ohne jemals ein explizites Bewegungsfeld zu berechnen.
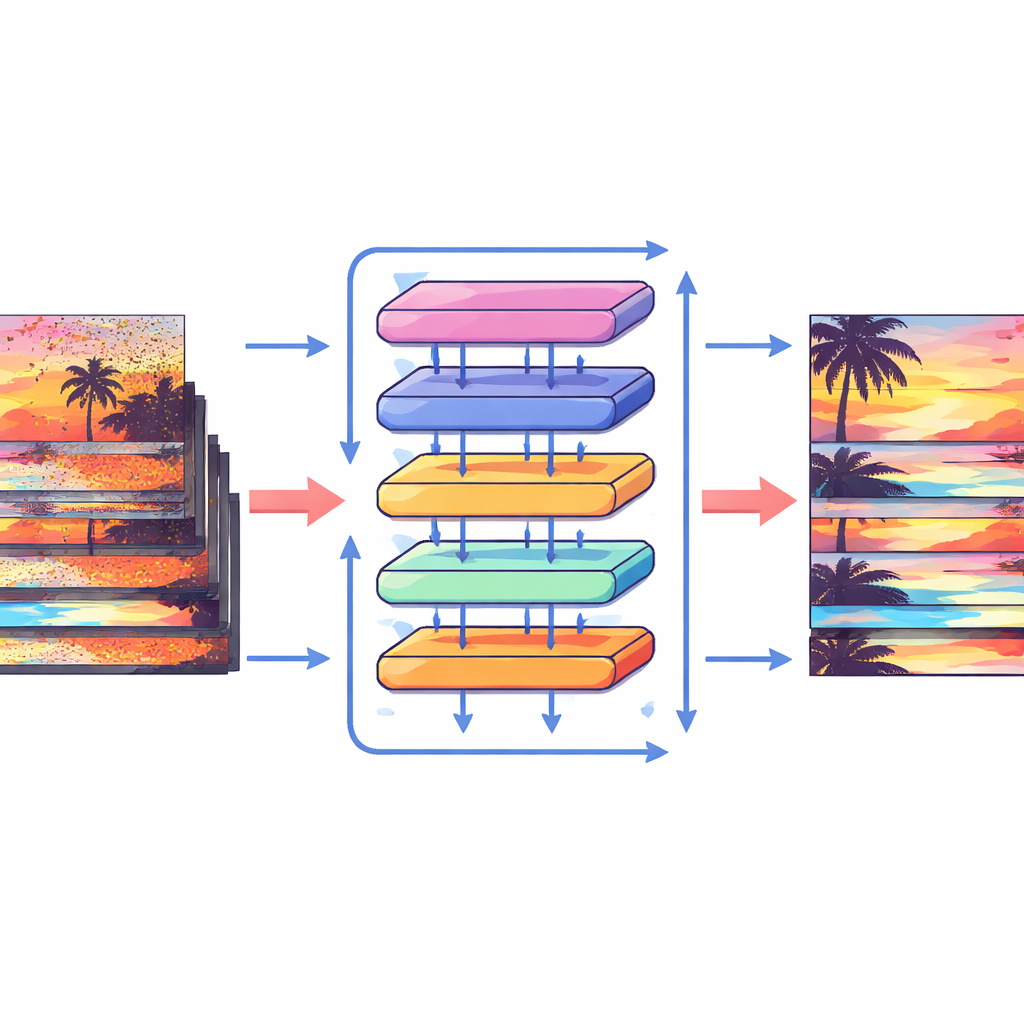
Wie die neuen Bausteine funktionieren
Um das Beste aus diesen Verschiebungen herauszuholen, entwerfen die Autoren einen speziellen Attention-Block, der Informationen innerhalb und über Frames hinweg mischt. Zuerst werden die verschobenen Features aus benachbarten Frames zusammengeführt und mittels Cross-Attention verglichen: Das Modell lernt, welche Bereiche in anderen Frames jede Position im aktuellen Frame am besten unterstützen. Gleichzeitig fokussiert eine separate Attention-Operation Beziehungen innerhalb eines einzelnen Frames und stärkt so lokale Struktur und Textur. Diese beiden Ströme werden anschließend zusammengeführt und durch einfache Verarbeitungsschichten in einem mehrskaligen U-förmigen Netzwerk geleitet, das von grober zu feiner Auflösung und zurück arbeitet. Dieses Layout erlaubt es dem System, sowohl große Kamerabewegungen als auch feine Details wie dünne Kanten oder kleine Muster zu verarbeiten und schrittweise eine saubere Version jedes Frames zu rekonstruieren.
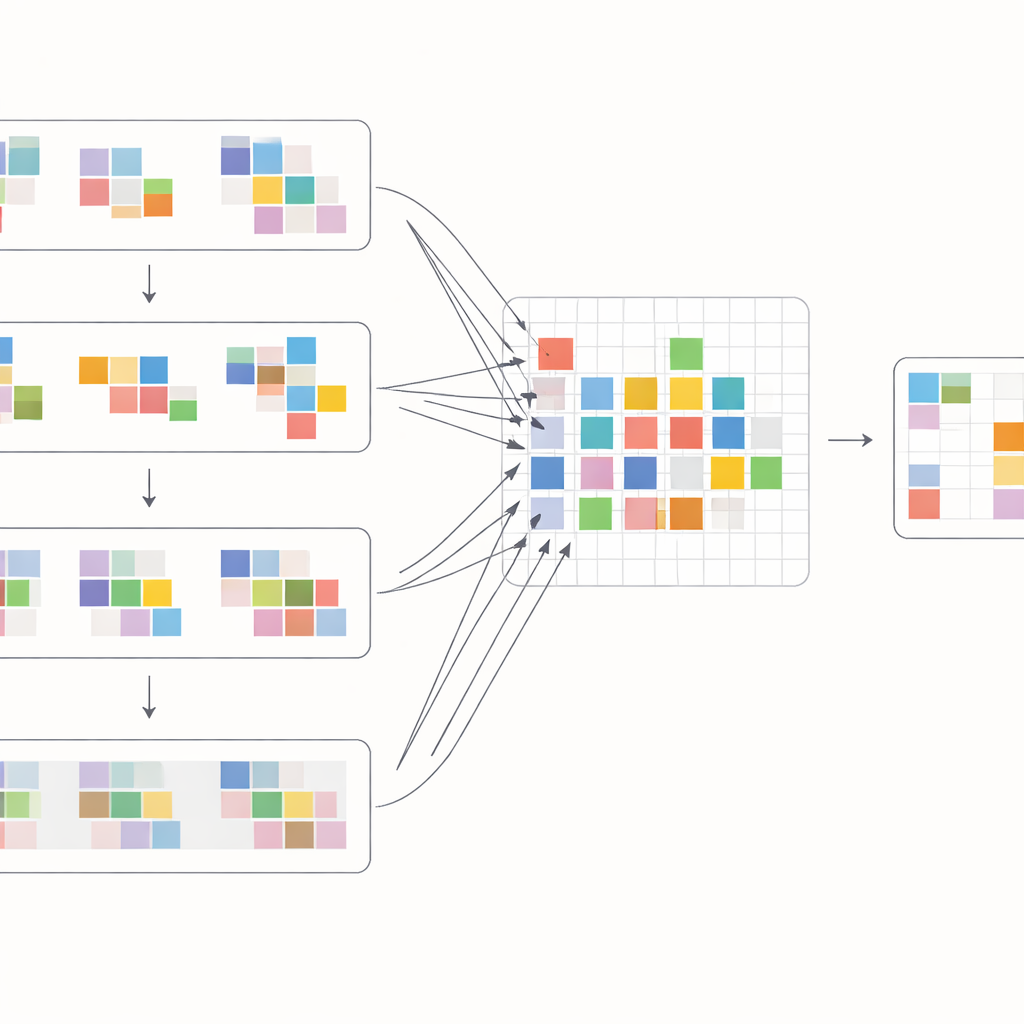
Wie gut es in der Praxis funktioniert
Die Forschenden testen ihren Ansatz an zwei anspruchsvollen Benchmarks. Die erste nutzt saubere Videos, die künstlich mit unterschiedlichen Rauschstärken verfälscht wurden, sodass sich präzise messen lässt, wie eng die wiederhergestellten Frames an den Originalen liegen. Hier erreicht die neue Methode durchgehend zumindest die Qualität früherer Faltungs- und rekurrenter Netze und kommt den besten existierenden Transformer-basierten Modellen nahe, während sie weniger Rechenleistung benötigt. Der zweite Benchmark verwendet reales Filmmaterial von Bildsensoren bei wenig Licht, bei dem das Rauschen ungleichmäßig, gefärbt und deutlich weniger vorhersehbar ist. In diesem realistischeren Test übertrifft der Shift Alignment Transformer die bisherigen State-of-the-Art-Methoden deutlich und erzeugt Videos, die sauberer, schärfer und zeitlich stabiler wirken, mit weniger Farbverschiebungen und weniger verbleibenden Artefakten.
Was das für künftige Videotools bedeutet
Vereinfacht gesagt zeigen die Autoren, dass es möglich ist, Videos effektiv zu entrauschen, ohne Bewegung explizit zu verfolgen, indem man intelligente Verschiebungen in Zeit und Raum mit aufmerksamkeitsbasiertem Feature-Matching kombiniert. Ihr Shift Alignment Transformer bietet eine gute Balance aus Genauigkeit und Effizienz, insbesondere für realweltliche Low-Light-Aufnahmen, bei denen traditionelle Bewegungsschätzung anfällig ist. Mit steigender Effizienz aufmerksamkeitsbasierter Modelle könnten Ansätze wie dieser in Alltagskameras und Streaming-Diensten Einzug halten und dabei helfen, verrauschte, schwer anzuschauende Clips für Nutzer in glatte, scharfe Videos zu verwandeln — mit minimalem Aufwand.
Zitation: Zhang, X., Fan, S., Zhang, H. et al. SAT: shift alignment transformer for video denoising without flow estimation. Sci Rep 16, 8207 (2026). https://doi.org/10.1038/s41598-026-38431-9
Schlüsselwörter: Video-Rauschreduzierung, Transformer, Bildrauschen, Low-Light-Video, Computer Vision