Clear Sky Science · de
Abfrageeffiziente entscheidungsbasierte adversariale Attacke mit geringem Abfragebudget
Warum winzige Bildstörungen intelligente Maschinen in die Irre führen können
Moderne künstliche Intelligenz erkennt Gesichter, Tiere und Alltagsgegenstände mit beeindruckender Genauigkeit. Dieselben Systeme lassen sich jedoch durch Veränderungen an einem Bild täuschen, die so klein sind, dass Menschen sie kaum sehen. Dieses Papier untersucht eine neue Methode, um solche „täuschenden“ Bilder zu erzeugen, während die KI so wenig wie möglich befragt wird. Das zeigt sowohl, wie zerbrechlich aktuelle Modelle sein können, als auch wie Angreifer sie in der realen Welt ausnutzen könnten.
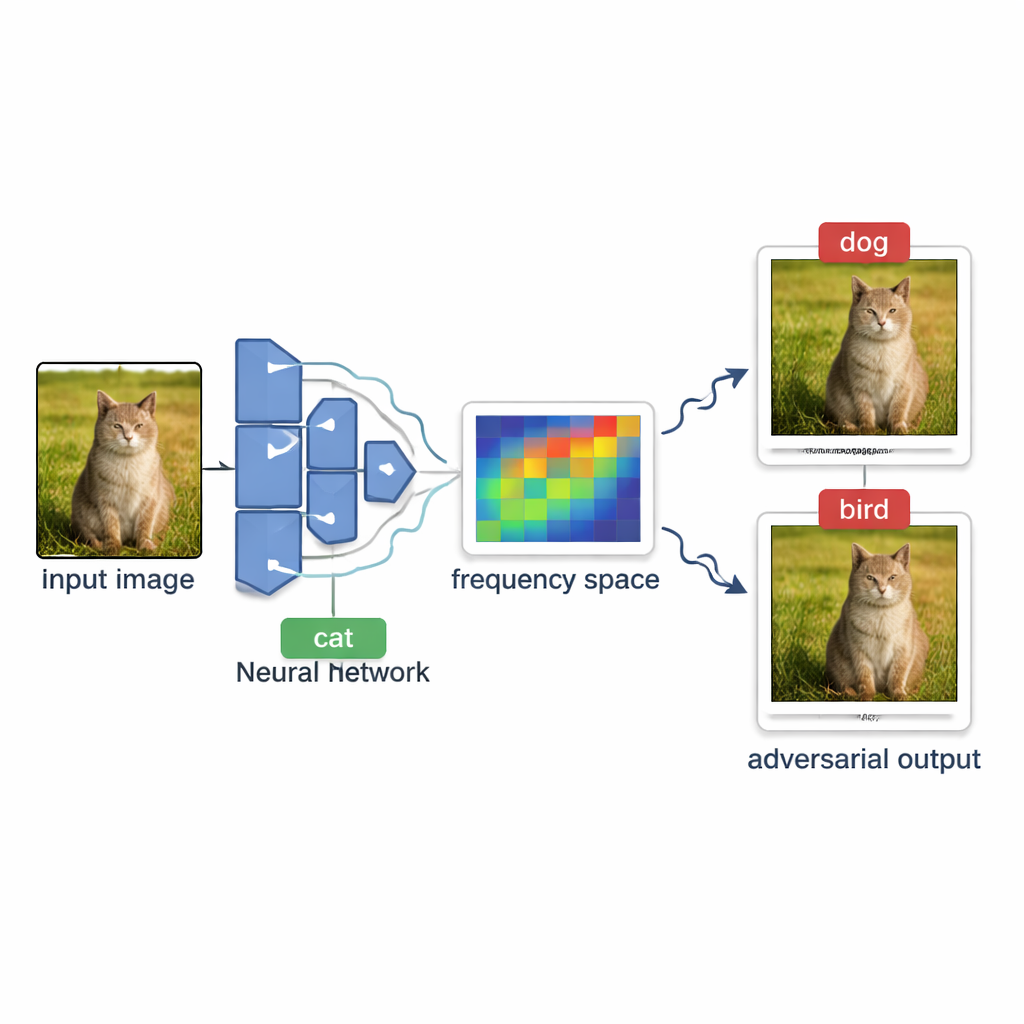
Wie Angreifer KI-Systeme von außen ausloten
Bei vielen realen Diensten – etwa Online-Fototagging oder Inhaltsfilter – verhält sich das Modell wie eine Black Box. Außenstehende können ein Bild hochladen und nur das finale Label sehen, etwa „Hund“ oder „Stoppschild“, aber niemals interne Vertrauenswerte oder die Struktur des Modells. Unter diesen Bedingungen ein irreführendes Bild zu erzeugen, nennt man einen entscheidungsbasierten Black-Box-Angriff. Die Herausforderung besteht darin, ein normales Bild so behutsam zu verändern, dass das Modell es falsch klassifiziert, ohne sehen zu können, wie „nah“ das Modell an einer Meinungsänderung ist, und ohne so viele Testanfragen zu senden, dass das System es bemerkt oder die Abfragen zu teuer werden.
Eine neue Suchstrategie mit sehr wenigen Anfragen
Die Autoren stellen OPOQA (One Plane One Query Attack) vor, eine Methode, die mit Abfragen geizt und dennoch hochwertige adversariale Bilder erzeugt. Anstatt wiederholt in einer einzigen vermuteten Richtung zu probieren, arbeitet OPOQA in Runden. In jeder Runde startet es von einem bereits irreführenden Bild und dem ursprünglichen sauberen Bild und schlägt mehrere neue Kandidatenbilder vor, die in sorgfältig gewählten Richtungen liegen. Entscheidend ist, dass jede Richtung höchstens einmal abgefragt wird, wodurch das begrenzte Abfragebudget frei wird, um viel mehr Möglichkeiten zu erkunden, statt eine einzelne Vermutung zu überfeinern.
Den sanften Wellen im Bild folgen
Um vielversprechende Richtungen zu wählen, baut OPOQA auf die Idee, dass die effektivsten, kaum sichtbaren Änderungen oft glatt und breit angelegt sind statt scharfer Pixelstörungen. Die Methode nutzt ein mathematisches Werkzeug, die diskrete Kosinustransformation, um das Bild in eine „Frequenz“-Ansicht zu überführen, in der langsame, sanfte Variationen kompakt liegen. Sie sampelt zufällig einige dieser Niederfrequenz-Komponenten, wandelt sie zurück in normale Pixeländerungen und verwendet sie als grundlegende Erkundungsrichtungen. Jede ausgewählte Richtung definiert eine flache zweidimensionale Fläche, die das Originalbild, das aktuelle adversariale Bild und einen neuen Kandidaten verbindet. Auf jeder dieser Flächen wählt OPOQA einen einzigen Punkt zum Testen aus, wobei zwei Ziele abgewogen werden: näher am Original zu bleiben und dennoch wahrscheinlich das Modell in eine falsche Entscheidung zu treiben.

Den besten Kandidaten wählen und unterwegs anpassen
Sobald OPOQA eine kleine Menge Kandidatenbilder erzeugt hat, misst es, wie weit jedes von ihnen vom Originalbild entfernt ist, und sortiert sie von den geringsten zu den stärksten Veränderungen. Dann fragt es das Modell in dieser Reihenfolge ab. Sobald ein Kandidat gefunden wird, den das Modell falsch klassifiziert, hält es an und behandelt dieses Bild als neuen Startpunkt für die nächste Runde. Falls keiner der Kandidaten das Modell täuscht, behält OPOQA das bisher beste adversariale Bild bei, passt jedoch ein internes Steuerungsparameter an, das bestimmt, wie konservativ oder aggressiv die nächsten Schritte sein sollen. Diese „gierige“ Strategie – stets das beste verfügbare fehlklassifizierte Bild anzunehmen und die Schrittgröße dynamisch zu justieren – erlaubt es dem Angriff, sich auf subtile, wirkungsvolle Störungen zu konzentrieren, ohne Abfragen an wenigversprechende Richtungen zu verschwenden.
Was die Experimente über AIs Schwachstellen zeigen
Die Forscher testeten OPOQA an 200 Bildern des groß angelegten ImageNet-Benchmarks und sechs weit verbreiteten neuronalen Netzen, darunter Inception-v3, ResNet, VGG, DenseNet und Vision Transformer. Unter einer strikten Begrenzung von 1.000 Modellabfragen pro Bild erreichte OPOQA Ergebnisse auf Augenhöhe mit oder besser als mehrere führende Angriffsverfahren. Beispielsweise täuschte es Inception-v3 bei 94 Prozent der Bilder erfolgreich, während die Veränderungen so gering blieben, dass sie für das menschliche Auge nahezu unsichtbar waren, und verbesserte damit die bisher beste Methode um mehrere Prozentpunkte. Modellübergreifend erreichte OPOQA tendenziell hohe Erfolgsraten früher – mit weniger Abfragen –, obwohl einige konkurrierende Methoden aufholten oder sie übertrafen, wenn sehr große Abfragebudgets und Zeit für Feinabstimmung zur Verfügung standen.
Was das für die alltägliche KI-Sicherheit bedeutet
Die Studie zeigt, dass heutige Sichtsysteme auch dann getäuscht werden können, wenn Angreifer nur finale Entscheidungen sehen und nur begrenzte Möglichkeiten haben, das Modell zu befragen. Durch intelligentes Ausloten sanfter, niederfrequenter Änderungen und sparsames Rationieren jeder Abfrage kann OPOQA Bilder erzeugen, die für Menschen gleich aussehen, Maschinen aber massiv in die Irre führen. Für Nicht-Expertinnen und -Experten lautet die Quintessenz, dass das „Sehen“ der KI weiterhin recht brüchig ist: Es lässt sich auf subtile, schwer erkennbare Weise aus dem Gleichgewicht bringen. Solche effizienten Angriffe zu erkennen und zu untersuchen ist ein wichtiger Schritt, um reale Systeme – etwa Überwachungskameras, medizinische Bildanalyse oder autonome Fahrzeuge – gegen Manipulationen zu härten, die andernfalls unbemerkt blieben.
Zitation: Tuo, Y., Yin, M. & Che, S. Query-efficient decision-based adversarial attack with low query budget. Sci Rep 16, 6886 (2026). https://doi.org/10.1038/s41598-026-38428-4
Schlüsselwörter: adversariale Beispiele, Black-Box-Angriffe, Sicherheit bei Deep Learning, Bildklassifikation, abfrageeffiziente Attacke