Clear Sky Science · de
Bewertung der Überschwemmungsanfälligkeit mit drei maschinellen Lernverfahren und Vergleich ihrer Leistung
Warum das Überschwemmungsrisiko in einem äthiopischen Einzugsgebiet wichtig ist
Überschwemmungen töten weltweit jedes Jahr Tausende von Menschen, vernichten Ernten und beschädigen Häuser und Straßen. Im Choke-Einzugsgebiet in Äthiopien, einer Hochlandregion, die den Blauen Nil speist, treffen Sturzfluten schnell und oft ohne Vorwarnung ein. Diese Studie zeigt, wie moderne Computerverfahren Satellitenbilder, Karten und Niederschlagsaufzeichnungen in detaillierte Gefahrenkarten verwandeln können, die Gemeinden und Planern helfen zu entscheiden, wo gebaut, wo Landwirtschaft betrieben und wo Menschen vor dem nächsten Sturm geschützt werden sollten.

Eine Berglandschaft unter Druck
Das Choke-Einzugsgebiet liegt im Hochland Nordwest-Äthiopiens, wo steile Berge mehr als 60 Flüsse und Hunderte von Quellen speisen. Dieses zerklüftete Gelände trägt zur Landwirtschaft, Wasserkraft, Trinkwasserversorgung und sogar zum Tourismus bei, leitet aber auch starke saisonale Regenfälle in enge Täler und Überflutungsflächen. In den vergangenen zehn Jahren haben wiederkehrende Überschwemmungen Felder, Straßen, Brücken, Schulen und Häuser beschädigt, besonders während der Hauptregenzeit von Juni bis September. Bevölkerungswachstum, Abholzung und wachsende Ortschaften haben die Landoberfläche verändert und sie oft weniger aufnahmefähig für Wasser gemacht, wodurch plötzliche Abflusssteigerungen flussabwärts wahrscheinlicher werden.
Karten und Messungen in eine Überschwemmungshistorie verwandeln
Um zu verstehen, wo Überschwemmungen am häufigsten auftreten, erstellten die Forschenden zunächst ein Überschwemmungs‚inventar‘ für das Einzugsgebiet. Sie kombinierten Regierungsberichte zu Katastrophen, Feldinformationen und Radaraufnahmen der Sentinel‑1‑Satelliten, die über Wolken hinweg überschwemmte Gebiete erkennen können. Für fünf große Überschwemmungsjahre zwischen 2005 und 2020 verglichen sie Bilder vor und nach den Ereignissen, um überflutete Zonen zu lokalisieren. Außerdem nutzten sie Höheninformationen, um permanente Seen und steile Hänge auszuschließen, die kein stehendes Überschwemmungswasser beherbergen würden. Daraus stellten sie eine ausgeglichene Auswahl von Standorten zusammen, die überschwemmt waren, und anderen, die trocken geblieben waren — das Lernmaterial für ihre Computermodelle.
Das Land lesen, um künftige Überschwemmungen vorherzusagen
Als Nächstes sammelte das Team elf Arten von Informationen, die beeinflussen, wo sich Wasser ansammelt, darunter Geländehoehe, Neigungssteilheit, die Krümmung von Hängen, Bodenfeuchteneigungen, Flussnetzwerke, Entfernung zu Gewässern, Niederschlag, Bodentyp und Landnutzung. Alle diese Faktoren wurden in einem geografischen Informationssystem zu übereinstimmenden Kartenebenen verarbeitet. Die Modelle wurden darauf trainiert, Muster zu erkennen, die diese Ebenen mit vergangenen Überschwemmungen verknüpfen. In den Tests hoben sich drei Merkmale als besonders wichtig hervor: Höhe, Hangneigung und ein Feuchtigkeitsindex, der widerspiegelt, wie leicht sich Wasser an bestimmten Stellen ansammelt. Tieflagen mit flachen Hängen und hohen Feuchtigkeitswerten erwiesen sich als eindeutige Brennpunkte für Überschwemmungen, während Exposition (also die Hangausrichtung) und selbst Niederschlagsvariabilität in diesem speziellen Gebirge weniger ins Gewicht fielen.
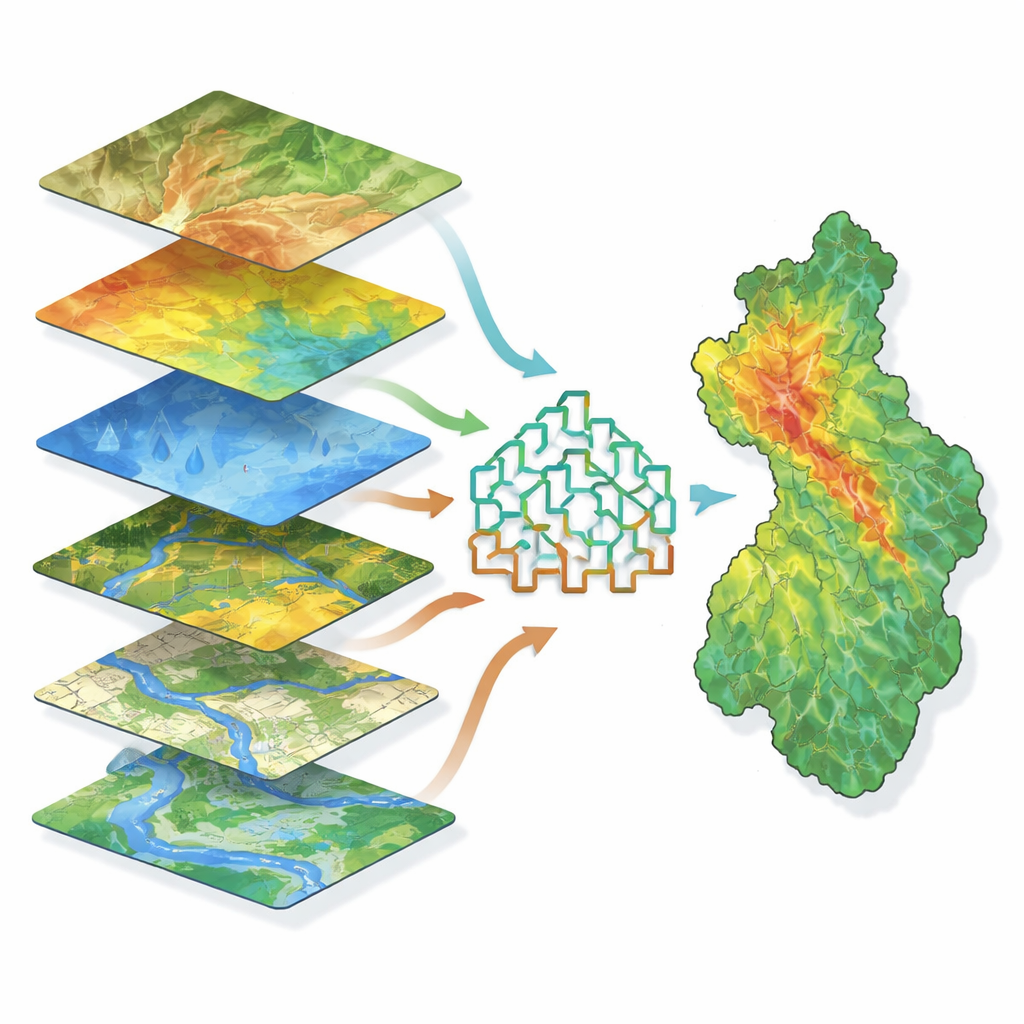
Mashinen beibringen, Gefährdungszonen zu erkennen
Die Studie verglich drei fortgeschrittene Methoden des maschinellen Lernens, die alle auf vielen gemeinsam arbeitenden Entscheidungsbäumen basieren: Random Forest, Gradient Boosting und Extreme Gradient Boosting. Diese Ansätze sind gut darin, verwobene Beziehungen zwischen vielen Faktoren zu handhaben, ohne perfekte Daten oder einfache Formeln zu benötigen. Nachdem sie ihre Daten in Trainings‑ und Testgruppen aufgeteilt hatten, optimierten die Autoren jedes Modell und überprüften die Leistung mit mehreren statistischen Kennzahlen. Zwei der Methoden, Gradient Boosting und Extreme Gradient Boosting, waren besonders genau und unterschieden überschwemmte von nicht überschwemmten Punkten in etwa 97 Prozent der Fälle richtig; Random Forest folgte dicht dahinter. Alle drei lieferten Karten der Überschwemmungsanfälligkeit, die das Einzugsgebiet in fünf Klassen von sehr gering bis sehr hoch einteilten, wobei die nördlichen und südwestlichen Abschnitte das größte Risiko zeigten.
Von Computerkarten zu sichereren Gemeinden
Für Nichtfachleute ist das wichtigste Ergebnis, dass diese maschinell erstellten Karten verstreute Berichte und Satellitenbilder zu einem klaren Bild darüber zusammenführen, wo sich Überschwemmungswasser am wahrscheinlichsten ausbreitet. Nur ein geringer Anteil des Choke‑Einzugsgebiets fällt in die Hochrisikozonen, doch diese Gebiete stimmen mit besiedelten Tieflagen und wichtigen Ackerflächen überein. Lokale Behörden können die Ergebnisse nutzen, um Standorte für neuen Wohnungsbau zu lenken, Brücken und Entwässerung zu verstärken oder Vegetation wiederherzustellen, um den Abfluss zu verlangsamen. Zwar können die Modelle detaillierte hydraulische Simulationen nicht ersetzen, doch sie bieten eine schnelle, kosteneffektive Möglichkeit, begrenzte Ressourcen auf die verwundbarsten Bereiche zu konzentrieren und ließen sich auf andere Gefahren wie Erdrutsche oder Erdbeben übertragen. In einem Land, in dem Daten und Budgets oft knapp sind, bietet diese Kombination aus Satelliten und intelligenten Algorithmen einen praxisnahen Weg zu widerstandsfähigeren Landschaften und Gemeinden.
Zitation: Asrade, T., Abebe, S., Tadesse, K. et al. Flood susceptibility assessment using three machine learning techniques and comparison of their performance. Sci Rep 16, 8099 (2026). https://doi.org/10.1038/s41598-026-38391-0
Schlüsselwörter: Überschwemmungsanfälligkeit, maschinelles Lernen, Choke-Einzugsgebiet, Fernerkundung, Katastrophenvorsorge