Clear Sky Science · de
MDI-YOLO: ein leichtgewichtiges, transformer‑CNN‑basiertes Modell zur multidimensionalen Merkmalsfusion für die Erkennung kleiner Objekte
Scharfere Augen am Himmel
Von der Verkehrskontrolle bis zur Katastrophenhilfe überwachen Drohnen und Satelliten unsere Welt zunehmend. Doch gerade die Dinge, die in diesen Bildern am wichtigsten sind—winzige Autos, Menschen, Boote und Flugzeuge—erscheinen oft nur als wenige Pixel. Die Arbeit zu MDI‑YOLO beschäftigt sich mit einer einfachen, aber entscheidenden Frage: Wie können Computer diese winzigen Objekte zuverlässig in Echtzeit erkennen, selbst auf leistungsschwachen Geräten, die von Drohnen getragen werden?
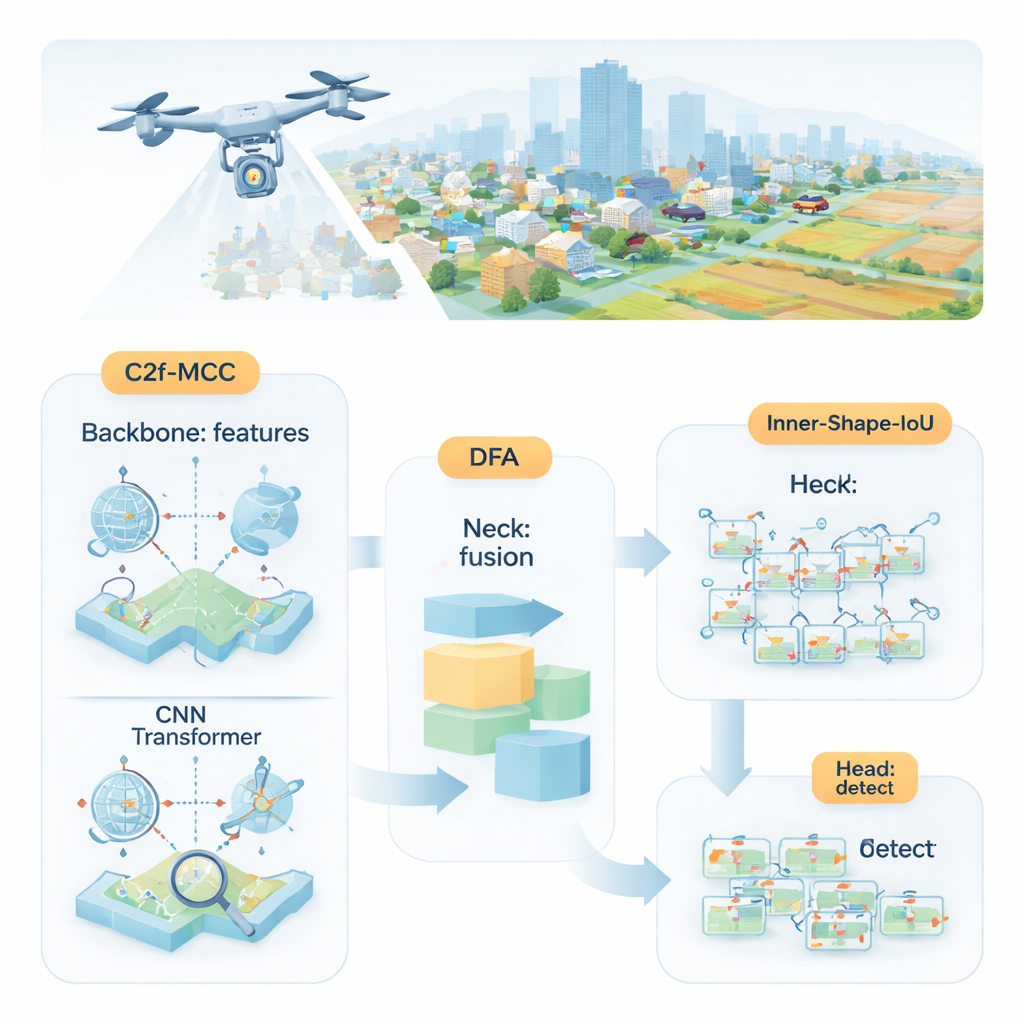
Warum kleine Objekte schwer zu erkennen sind
In Luft‑ und Satellitenaufnahmen sind Objekte von Interesse meist sehr klein, häufig dicht beieinander und teilweise von Gebäuden, Bäumen oder Schatten verdeckt. Standard‑Detektoren stehen vor einem Zielkonflikt: Leichtgewichtige Modelle laufen schnell auf Edge‑Geräten wie Bordcomputern von Drohnen, verpassen aber viele kleine Ziele; schwerere, genauere Modelle sind zu langsam und ressourcenintensiv für den praktischen Einsatz vor Ort. Kleine Objekte verschmelzen außerdem leicht mit komplexen Hintergründen—denken Sie an graue Autos auf grauen Straßen—sodass ihre markanten Merkmale beim Komprimieren und Durchlaufen tiefer Netzwerke schnell verloren gehen können.
Eine neue Mischung aus globaler und lokaler Sicht
Die Forschenden schlagen MDI‑YOLO vor, eine überarbeitete Version des beliebten YOLOv8‑Detektors, die das Modell kompakt hält und zugleich seine Fähigkeit verbessert, winzige Ziele zu finden. Im Kern steht ein neuer Baustein namens C2f‑MCC, der die visuellen Informationen im Netzwerk in zwei Pfade aufteilt. Ein Pfad nutzt Transformer‑ähnliche Verarbeitung, die gut darin ist, fernräumige Beziehungen über das gesamte Bild zu erfassen—etwa wie eine Pixelgruppe in eine größere Straße oder Startbahn passt. Der andere Pfad arbeitet mit klassischen Faltungsfiltern, die lokal Details wie Kanten und Texturen hervorragend herausarbeiten. Durch Gruppierung von Kanälen und das Leiten nur eines Teils der Daten durch den schwereren Transformer‑Pfad gewinnt das Modell globale Einsicht, ohne stark zu wachsen oder langsamer zu werden.
Dem Netzwerk helfen, sich auf Wichtiges zu konzentrieren
Auch mit besseren Bausteinen muss das Netzwerk entscheiden, worauf es seine Aufmerksamkeit richten soll. Zur Lenkung führen die Autorinnen und Autoren einen Mechanismus namens Directional Fusion Attention (DFA) ein. Dieses Modul betrachtet Muster entlang der Breite und Höhe des Bildes sowie eine Gesamtzusammenfassung der Szene und lernt, wie verschiedene Regionen und Merkmalskanäle zu gewichten sind. In der Praxis ermutigt DFA das Modell, sich auf wahrscheinliche Objektbereiche zu konzentrieren—etwa fahrzeugähnliche Flecken auf Straßen—und repetitive oder irreführende Hintergrundtexturen herunterzuspielen. Diese kombinierte räumliche und kanalbezogene Fokussierung erleichtert es, winzige Ziele von unruhigen Umgebungen oder ähnlich aussehenden Hintergrundbereichen zu trennen.
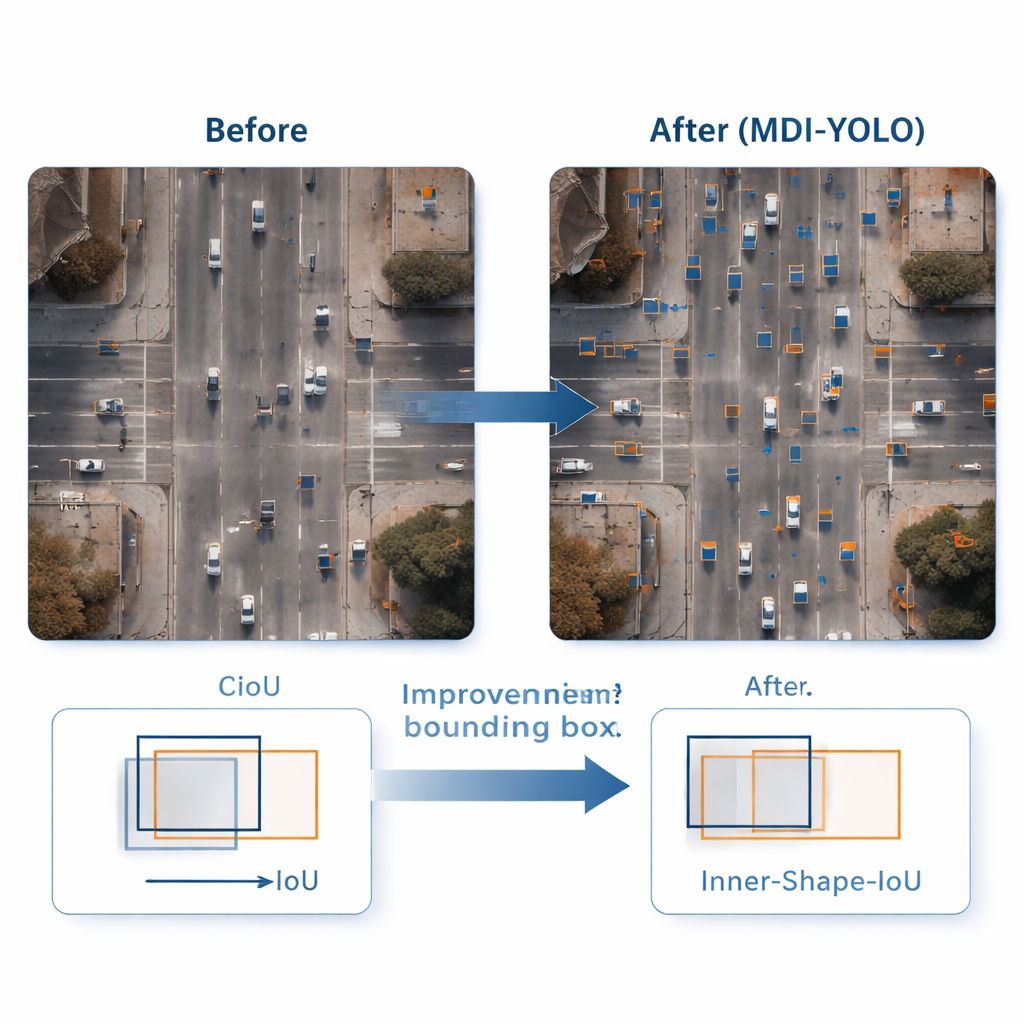
Engere Begrenzungsrahmen für winzige Ziele
Ein Objekt zu entdecken ist nur die halbe Miete; der Detektor muss es auch genau umreißen. Übliche Trainingsmethoden vergleichen vorhergesagte Rechtecke mit den wahren mithilfe einer Überlappungsmetrik, die bei kleinen oder ungewöhnlich geformten Objekten wenig empfindlich sein kann. Die Autorinnen und Autoren entwerfen eine neue Verlustfunktion, Inner‑Shape‑IoU, die Boxen nicht nur nach Überlappung bewertet, sondern auch danach, wie gut Form, Größe und Zentralbereich mit dem echten Objekt übereinstimmen. Durch die Kombination zweier komplementärer Maßstäbe bestraft sie Boxen, die nur an den Rändern passen, aber den Kern des Ziels verfehlen, und führt so zu präziseren Umrissen—insbesondere für kleine, dicht gedrängte oder längliche Objekte.
Nachgewiesene Verbesserungen ohne zusätzliches Volumen
Um MDI‑YOLO zu testen, führte das Team Experimente auf zwei anspruchsvollen öffentlichen Benchmarks durch: VisDrone2019, mit Drohnenaufnahmen von Städten und Verkehr, und DOTAv1.0, einer großen Sammlung von Luftaufnahmen mit vielen kleinen, dicht gepackten Objekten. Ohne auf vortrainierte Modelle zurückzugreifen, steigerte MDI‑YOLO die gängigen Genauigkeitsmaße um mehrere Prozentpunkte gegenüber dem Basis‑YOLOv8, während die Parameteranzahl praktisch unverändert blieb und die Inferenzzeiten schnell blieben. Im Vergleich zu einer Reihe populärer Detektoren—von leichten YOLO‑Varianten bis hin zu schwereren Transformer‑basierten Systemen—bot es eine seltene Kombination aus hoher Genauigkeit, geringen Rechenkosten und Robustheit über verschiedene Szenen hinweg.
Was das für den Praxiseinsatz bedeutet
Für Nicht‑Spezialisten lautet die Erkenntnis, dass MDI‑YOLO Drohnen und Fernerkundungssystemen schärfere, verlässlichere „Augen“ verleiht, ohne große, energiehungrige Rechner zu verlangen. Durch die kluge Mischung aus globalem Kontext, lokalem Detail, zielgerichteter Aufmerksamkeit und einer anspruchsvolleren Methode zum Trainieren von Begrenzungsrahmen erleichtert das Verfahren die Erkennung winziger Objekte, die für Sicherheit, Überwachung und Kartierung wichtig sind. Diese Art von effizienter, hochpräziser Bildverarbeitung ist ein wichtiger Schritt zu autonomeren, reaktionsschnellen und breit einsetzbaren Luftplattformen in der Praxis.
Zitation: Shi, H., Wu, Y., Xu, Y. et al. MDI-YOLO a lightweight transformer-CNN-based multidimensional feature fusion model for small object detection. Sci Rep 16, 7233 (2026). https://doi.org/10.1038/s41598-026-38378-x
Schlüsselwörter: Drohnenbildgebung, Erkennung kleiner Objekte, Fernerkundung, YOLO, Computer Vision