Clear Sky Science · de
DT-gestützte Ressourcenallokation mittels generativem adversarialem Imitationslernen in komplexen Cloud-Edge-End-Szenarien
Intelligentere Datenautobahnen für das Internet der Dinge
Wenn Städte, Fabriken und Wohnungen mit vernetzten Sensoren und Geräten volllaufen, erzeugen sie gewaltige Datenmengen, die schnell und zuverlässig verarbeitet werden müssen. Alles an entfernte Cloud-Server zu schicken, kann zu langsam sein, während kleine Geräte am "Edge" oft nicht genug Rechenleistung haben. Dieser Artikel untersucht eine neue Methode, um automatisch Rechen-, Speicher- und Netzwerkressourcen über Geräte, nahegelegene Edge-Server und die Cloud zu verteilen—sodass intelligente Anwendungen auch dann schnell und robust bleiben, wenn reale Bedingungen unübersichtlich und unvorhersehbar sind.
Warum heutige Methoden an ihre Grenzen stoßen
Moderne Systeme setzen häufig auf Deep Reinforcement Learning, bei dem ein Algorithmus durch Trial-and-Error mithilfe von Belohnungssignalen aus der Umgebung lernt. In komplexen, verrauschten Netzwerken sind diese Belohnungen jedoch schwer zu definieren und zu messen. Ist die Reward-Funktion falsch oder durch Störungen verzerrt, kann das System unsicheres oder verschwenderisches Verhalten erlernen. Viele bestehende Methoden gehen zudem von umfangreichem Vorwissen über Verkehrsprofile und Geräteverhalten aus—das in produktiven industriellen Netzwerken selten vorliegt. Darüber hinaus optimieren die meisten Lösungen nur eine Ressourcenart zurzeit, etwa Rechenleistung, und ignorieren dabei Speicher oder Netzwerkbandbreite, obwohl alle drei zusammen die reale Leistung bestimmen.
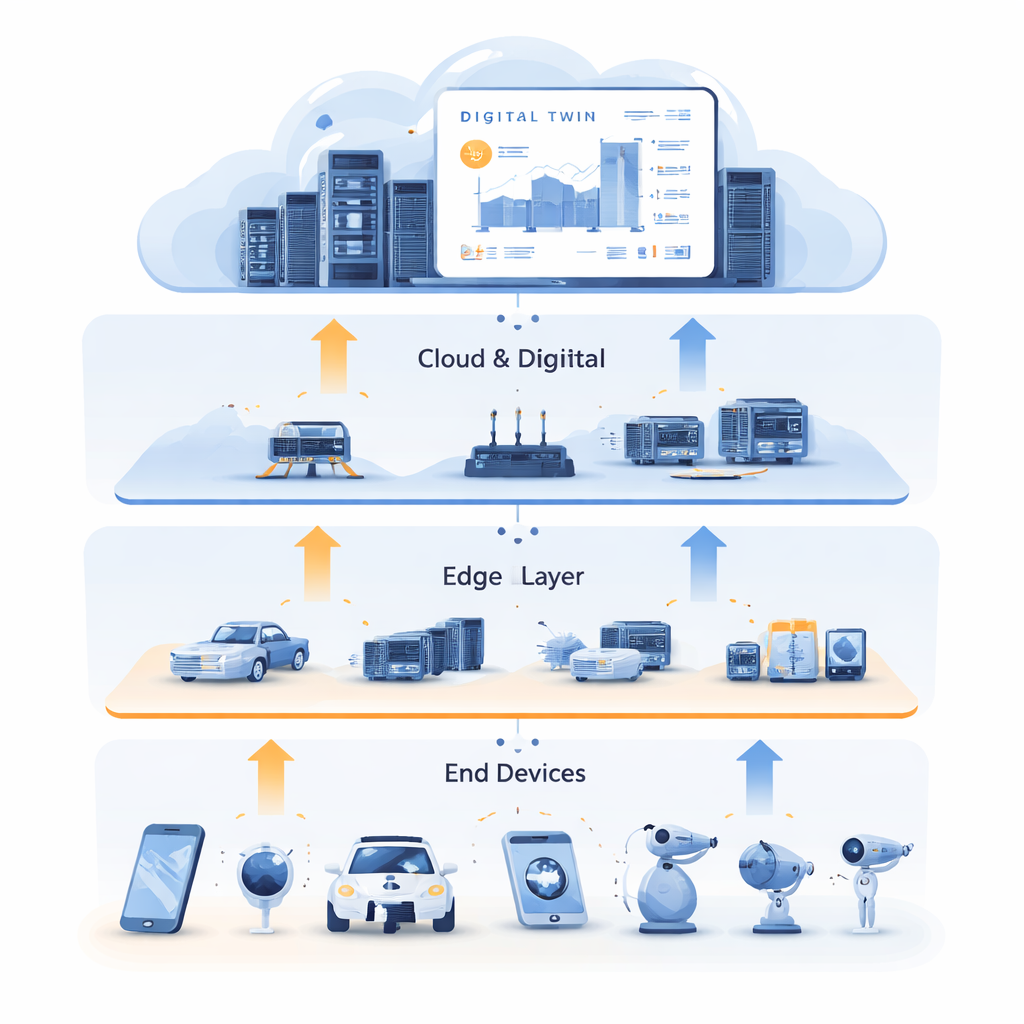
Lernen vom digitalen Doppelgänger
Um diesen Engpass zu überwinden, kombinieren die Autoren die Ressourcenallokation mit Digital-Twin-Technologie. Ein Digital Twin ist ein detailliertes virtuelles Abbild des physischen Netzwerks, das in der Cloud gepflegt wird. Es spiegelt den Zustand von Edge-Servern, Verbindungen und Aufgaben über die Zeit wider und nutzt umfangreiche historische Daten aus Sensoren und Logs. In dieser Arbeit dient der Digital Twin nicht nur als Dashboard; er wird zur Trainingsumgebung. Das System verwendet Vergangenheitsdaten, um „Experten“-Beispiele guter Entscheidungen zu erzeugen, die zeigen, wie Aufgaben zwischen Rechenleistung und Caching aufgeteilt werden sollten und wo sie zur geringen Latenz verarbeitet werden sollten. Dieses Training findet offline statt, ohne Live-Dienste zu stören, und nutzt die reichhaltigen Rechenressourcen der Cloud, um viele mögliche Situationen zu erkunden.
Imitation statt Trial-and-Error
Anstatt direkt aus Belohnungen zu lernen, verfolgt das vorgeschlagene E‑GAIL-Modell Imitationslernen: Der Agent versucht, sich wie ein Experte zu verhalten. Zunächst bauen die Autoren mehrere Experten-Politiken mit einem Actor–Critic-Framework auf, das um eine NoisyNet-Schicht erweitert ist. Das gezielte Injizieren von Rauschen in das Entscheidungsnetzwerk erlaubt es diesen Experten, eine Vielzahl von Bedingungen—einschließlich Störungen, die reales Funkinterferenzverhalten und schwankende Arbeitslasten nachbilden—zu erleben, sodass ihre Trajektorien realistischer werden. Anschließend verschmilzt das System mehrere Einzel-Experten-Trajektorien zu einer einzigen "Multi-Expert"-Referenz mithilfe spieltheoretischer Werkzeuge. Indem es entlang einer Nash-Gleichgewichtsidee nach Konsens unter den Experten sucht, vermeidet es Konflikte zwischen ihnen und erzeugt eine Konsensstrategie mit breiterer Abdeckung möglicher Szenarien.
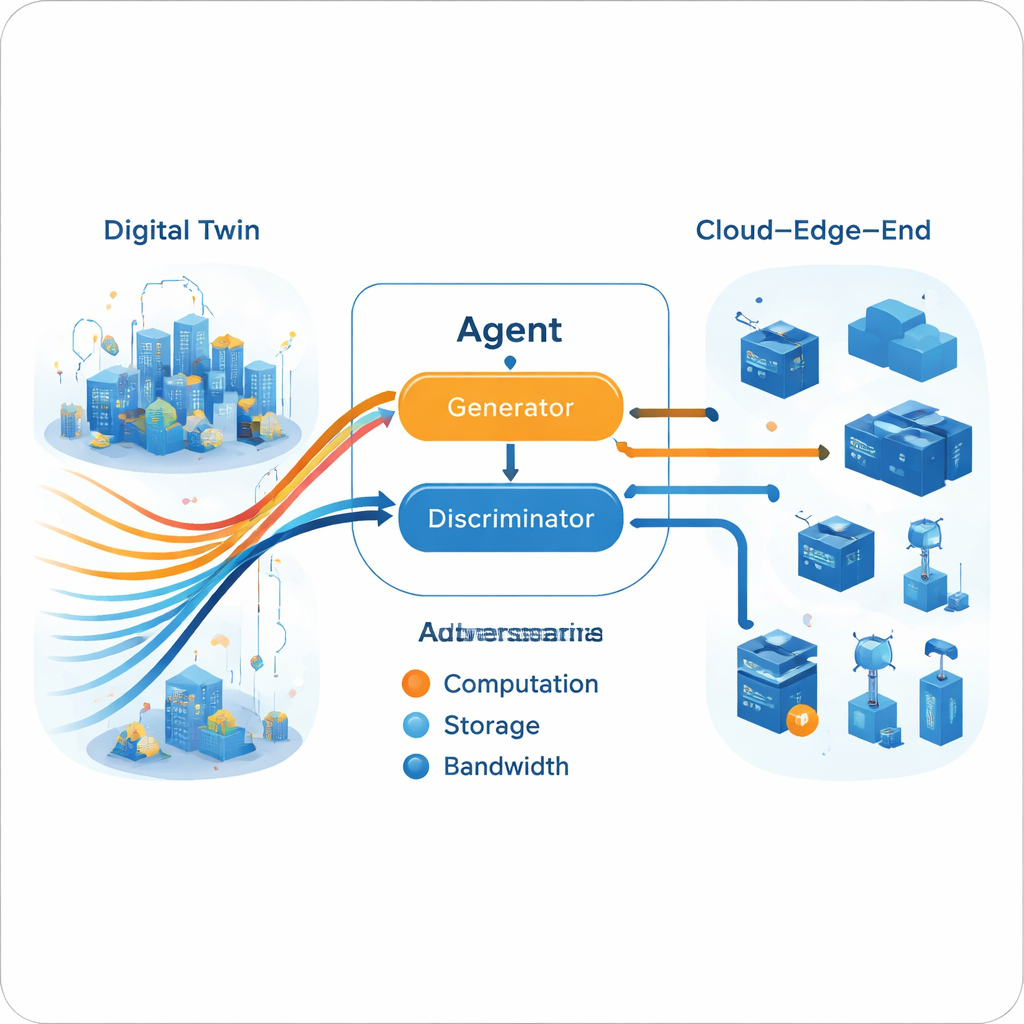
Eine generative adversariale Engine für Entscheidungen
Sobald die Multi-Expert-Trajektorie im Digital Twin aufgebaut ist, lernt der Live-Agent, sie in einem generativ-adversarialen Setup nachzuahmen—ähnlich dem Prinzip von bildgenerierenden neuronalen Netzen. Ein Generator schlägt Ressourcenallokationsaktionen anhand des aktuellen Netzwerkzustands vor, während ein Diskriminator versucht zu erkennen, ob eine Aktionssequenz vom Agenten oder aus den Experten-Trajektorien stammt. Mit der Zeit treibt dieses adversariale Spiel den Generator dazu, Entscheidungen zu produzieren, die der Diskriminator nicht von Expertenverhalten unterscheiden kann. Entscheidend ist, dass dieser Prozess keine explizite Reward-Funktion aus der realen Umgebung benötigt. Das Training ist zweigeteilt: intensives Offline-Lernen (in der Cloud) verfeinert Experten und Generator, während leichtere Online-Updates (am Edge) das Modell an aktuelle Bedingungen anpassen und die praktischen Grenzen von Edge-Hardware berücksichtigen.
Wie gut funktioniert das in der Praxis?
Die Autoren testen E‑GAIL gegenüber mehreren gängigen Baselines, darunter Deep Q‑Learning, spieltheoretisches Offloading, gierige Heuristiken, reine Cloud-Verarbeitung und zufällige Allokation. Über viele Experimente hinweg—mit Variationen in Anzahl der Endgeräte, Kanälen, Aufgabenmix, Arbeitslasten, Datengrößen, Distanzen und Rauschmustern—erreicht E‑GAIL durchgehend End-to-End-Latenzen, die sehr nahe an denen der Experten-Politik liegen und deutlich besser sind als bei anderen automatisierten Methoden. Es passt sich gut an, wenn Aufgaben zwischen rechenintensiv und speicherintensiv wechseln, wenn das Netzwerk wächst oder wenn die Interferenz zunimmt. Der Digital Twin beschleunigt die Erzeugung von Experten-Trajektorien und verbessert deren Qualität, während die Multi-Expert-Fusion die Bandbreite der Szenarien erweitert, die der Agent ohne komplettes Retraining bewältigen kann.
Was das für Alltagssysteme bedeutet
Für Nicht-Spezialisten ist die Kernbotschaft, dass dieser Ansatz Netzwerke in die Lage versetzt, sich intelligenter selbst zu verwalten, wenn Unsicherheit herrscht. Anstatt Regeln von Hand zu entwerfen oder auf fragiles Trial-and-Error-Lernen zu setzen, lernt E‑GAIL aus reichhaltigen, simulierten Erfahrungen des Digital Twins und von mehreren erfahrenen "Experten", deren Ratschläge mathematisch versöhnt werden. Das Ergebnis ist ein Ressourcenallokator, der schnell entscheiden kann, wo Aufgaben ausgeführt und wo Daten gespeichert werden sollen, und der die Reaktionszeiten niedrig hält, selbst wenn sich die Bedingungen ändern. In zukünftigen Industrie- und Smart-City-Systemen könnten solche selbstgelernten Koordinatoren dezent im Hintergrund Rechenleistung, Speicher und Bandbreite jonglieren und so unsere vernetzte Welt schneller, zuverlässiger und energieeffizienter machen.
Zitation: Zhang, X., Xin, M., Li, Y. et al. DT-aided resource allocation via generative adversarial imitation learning in complex cloud-edge-end scenarios. Sci Rep 16, 7657 (2026). https://doi.org/10.1038/s41598-026-38367-0
Schlüsselwörter: digitaler Zwilling, Edge-Computing, Imitationslernen, Ressourcenallokation, Industrielles Internet der Dinge