Clear Sky Science · de
Eine multiskalige End-to-End-Methode zur Fusion von sichtbarer und Infrarot-Bildverbesserung
Scharferes Nachtsehen für Menschen und Maschinen
Wer schon einmal bei Nacht fotografiert hat, weiß, wie schnell Dunkelheit Details verschluckt: Szenen wirken körnig, unscharf und voller seltsamer Farben. Viele wichtige Technologien – von Straßenkameras und Haussicherheit bis hin zu selbstfahrenden Autos und Rettungsdrohnen – müssen jedoch gerade unter solchen Bedingungen zuverlässig sehen. Dieser Beitrag stellt eine neue Methode vor, die gewöhnliche Farbkameras mit Infrarot-„Wärme“-Kameras kombiniert, sodass Computer und letztlich Menschen auch bei nahezu vollständiger Dunkelheit helle, detailreiche Ansichten der Welt erhalten.
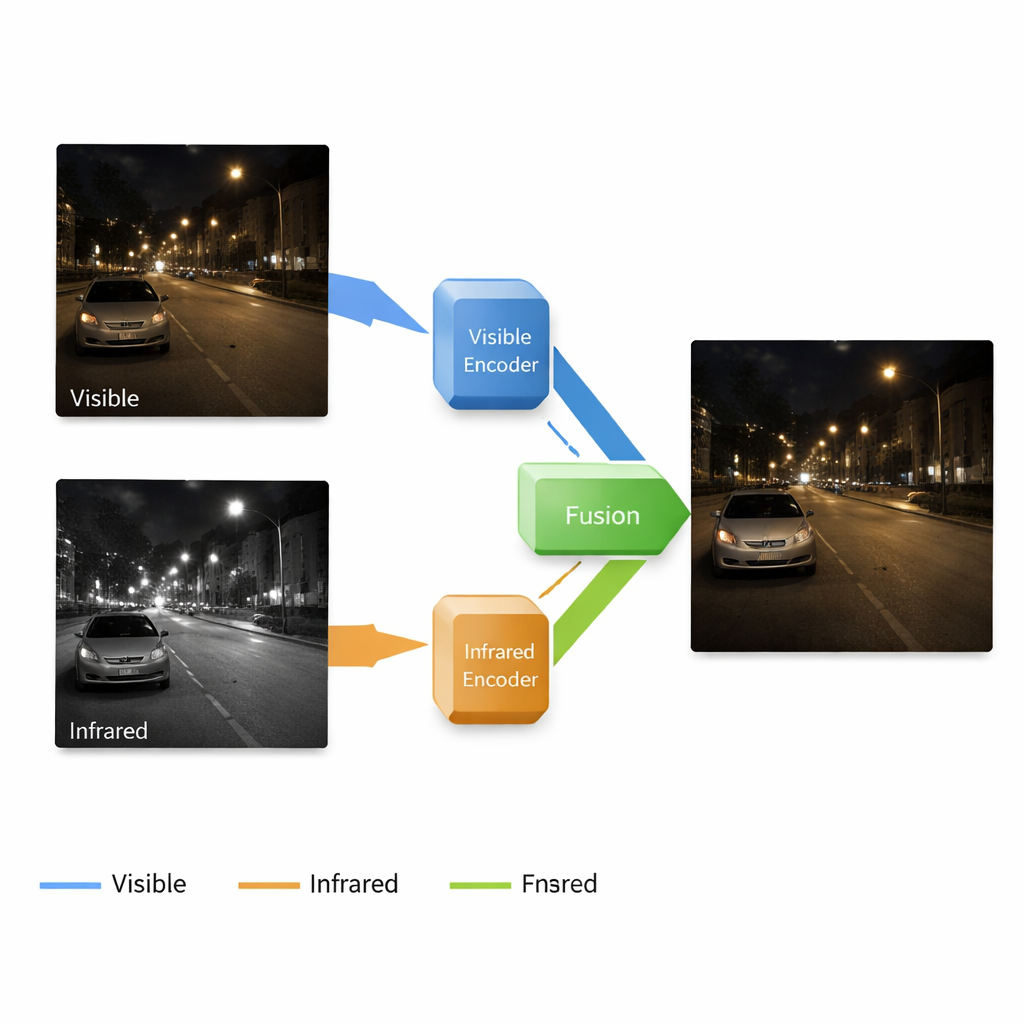
Warum zwei Kameratypen besser sind als einer
Standardkameras erfassen die gleiche Art von Licht, die auch unser Auge sieht, weshalb ihre Bilder für Menschen leicht zu interpretieren sind. Bei wenig Licht versagen sie jedoch oft: Schatten verschlucken Details, Rauschen tritt auf und Farben verschieben sich. Infrarotkameras wirken entgegengesetzt: Sie erfassen Wärmeverteilungen und machen Menschen, Tiere und Fahrzeuge im Dunkeln oder durch leichten Nebel sichtbar, doch ihre Aufnahmen fehlen feine Texturen und natürliche Erscheinung. Forscher versuchen seit langem, diese beiden Blickwinkel zu einem einzigen Bild zu verschmelzen, das wie ein klares Farbfoto wirkt und gleichzeitig warme, verborgene Objekte hervorhebt. Bestehende Methoden behandeln jedoch häufig die einzelnen Schritte – Aufhellen dunkler Bilder, Rauschreduktion und Einspeisung infraroter Informationen – als getrennte Aufgaben. Dieses stückweise Vorgehen kann zu nicht übereinstimmenden Merkmalen und enttäuschenden Fusionsresultaten führen.
Eine einzige Pipeline, die aufhellt und fusioniert
Die Autoren schlagen ein End-to-End-System vor, das Bilder in einem kontinuierlichen Ablauf verbessert und fusioniert. Es basiert auf einem neuronalen Netzwerk mit vier Hauptkomponenten: Ein Zweig lernt, schwach beleuchtete Farbbilder zu säubern und aufzuhellen, ein anderer Zweig repräsentiert die Szene der Infrarotkamera, ein Fusionsblock kombiniert die gelernten Repräsentationen und ein Dekoder rekonstruiert aus diesen gemischten Signalen das endgültige Bild. Wichtig ist, dass das System auf mehreren Skalen arbeitet – von groben Formen bis hin zu feinen Texturen. Flache Schichten erhalten Kanten und Oberflächendetails wie Ziegel oder Fahrbahnmarkierungen, während tiefere Schichten weitere Strukturen erfassen – Gebäude, Autos oder Bäume – sowie die Lage warmer Ziele im Infrarotbild.
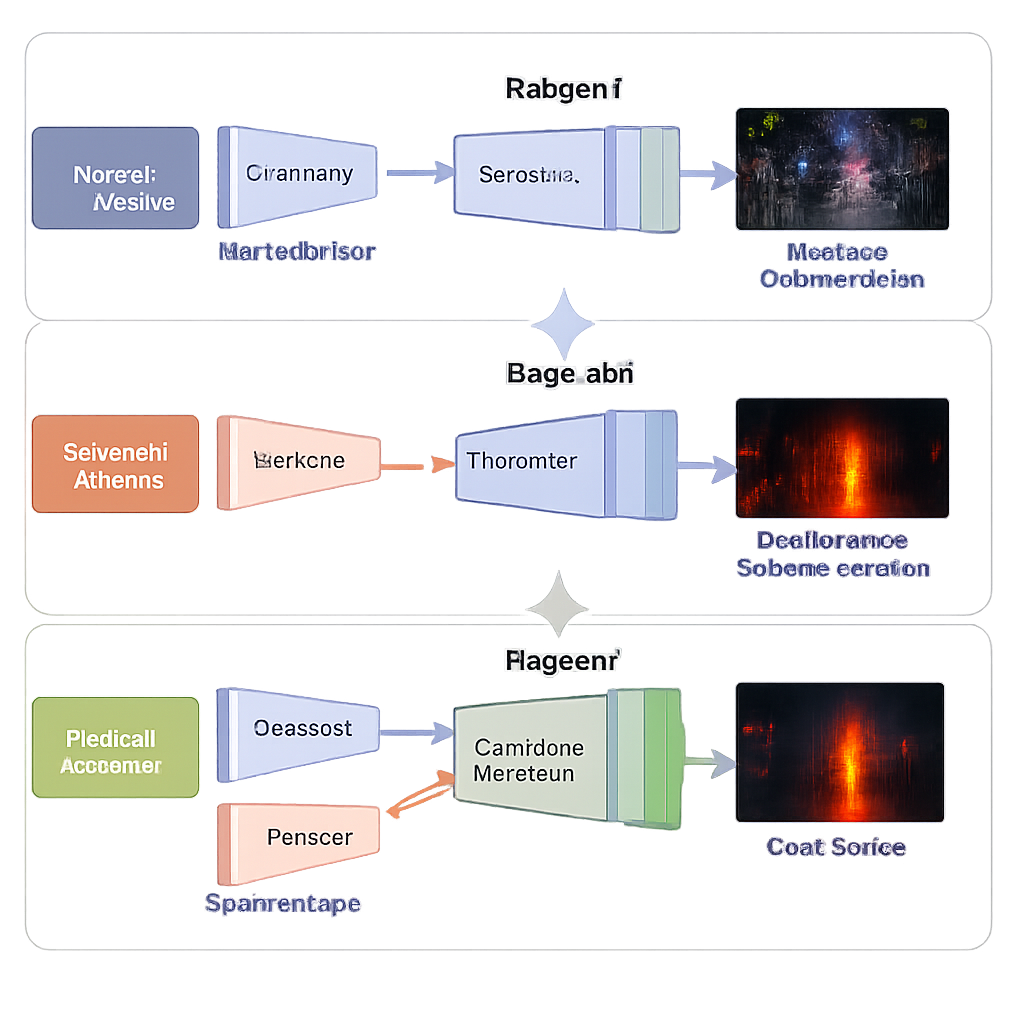
Drei Lernphasen statt eines großen Sprungs
Statt das System auf einmal zu trainieren, verwendet das Team eine dreistufige Lernstrategie, die auf Stabilität und Genauigkeit ausgelegt ist. In der ersten Phase sieht das Netzwerk nur dunkle Sichtlichtfotos und lernt, diese ohne menschlich vorgegebene „perfekte“ Referenzbilder aufzuhellen. Sorgfältig gewählte Verlustterme treiben die Ausgabe zu natürlicher Helligkeit, stabilen Farben, glatten Flächen ohne fleckiges Rauschen und erhaltener Textur. In der zweiten Phase wird derselbe Dekoder wiederverwendet, während ein neuer Infrarot-Zweig lernt, Infrarotbilder möglichst getreu zu rekonstruieren und dem Netzwerk beizubringen, wie Wärmeverteilungen aussehen sollten. In der dritten Phase werden die bisher gelernten Komponenten eingefroren, und nur der Fusionsblock wird trainiert, um die beiden Repräsentationen zu einem einzelnen, qualitativ hochwertigen Bild zu verschmelzen, das sowohl hell als auch informationsreich ist.
Erprobung der Methode
Die Forschenden bewerteten ihren Ansatz anhand öffentlicher Datensätze mit gepaarten sichtbaren und Infrarotbildern, die unter schwierigen Beleuchtungsbedingungen wie nächtlichen Straßen aufgenommen wurden. Sie verglichen ihre Methode mit mehreren führenden Fusionsverfahren, darunter solche, die auf klassischen Bildtransformationen, Standard-Convolutional-Netzwerken und komplexeren generativen Modellen basieren. Ihre Methode lieferte im Allgemeinen schärfere Details, gleichmäßigere Helligkeit und klarere thermische Ziele und erzielte höhere Werte bei quantitativen Maßen für Informationsgehalt, Kantenschärfe, strukturelle Ähnlichkeit und Kontrast. Zusätzliche Experimente, bei denen sie gezielt wichtige Systemkomponenten entfernten, zeigten, dass jedes Teil – der multiskalige Fusionsblock, das gestufte Training und die adaptive Gewichtung von sichtbaren gegenüber infraroten Merkmalen – messbar zur Endqualität beiträgt.
Was das für reale Sehsysteme bedeutet
Für Nicht-Spezialisten ist die Kernaussage einfach: Diese Arbeit zeigt, dass ein einzelnes, sorgfältig trainiertes Netzwerk sowohl dunkle Szenen aufhellen als auch Wärme- und Farbsichten intelligent zu einem kohärenten Bild zusammenführen kann. Die fusionierten Bilder bewahren feine Texturen und heben gleichzeitig warme Objekte hervor, wodurch sie für Aufgaben wie Nachtsurveillance, Fahrassistenz und erweiterte oder virtuelle Realität in schwach beleuchteten Umgebungen deutlich nützlicher werden. Obwohl die Autoren auf einige verbleibende Probleme hinweisen – etwa verringerter Kontrast in sehr hellen Bereichen und der Bedarf an schnelleren, leichteren Modellen – stellt ihr Ansatz einen wichtigen Schritt in Richtung Kamerasysteme dar, die bei Dunkelheit zuverlässig sehen können und für menschliche Nutzer natürlich und interpretierbar wirken.
Zitation: Xin, Y., Huang, J., Sun, C. et al. A multi-scale end-to-end visible and infrared image enhancement fusion method. Sci Rep 16, 7135 (2026). https://doi.org/10.1038/s41598-026-38323-y
Schlüsselwörter: Bildverbesserung bei schwachem Licht, Infrarot-Bildfusion, Nachtsehen, Multisensorische Bildgebung, Tiefenlern-Visionsysteme