Clear Sky Science · de
Baum-Forst-Beschneidung und Resampling für das Problem unausgewogener Klassen
Warum seltene Fälle für intelligente Vorhersagen wichtig sind
Viele Entscheidungen, die von künstlicher Intelligenz getroffen werden, hängen davon ab, seltene Ereignisse zu erkennen: eine betrügerische Kreditkartenbuchung, ein frühes Krankheitszeichen oder ein gefährlicher Maschinendefekt. In solchen Situationen sind die wichtigen Fälle deutlich seltener als die gewöhnlichen, und die meisten Lernalgorithmen tendieren dazu, sie zu übersehen. Dieser Artikel stellt eine Methode vor, die einen verbreiteten Ansatz—Random Forests—stärker auf diese seltenen, aber entscheidenden Fälle ausrichtet und zugleich das Modell schlanker und schneller macht.
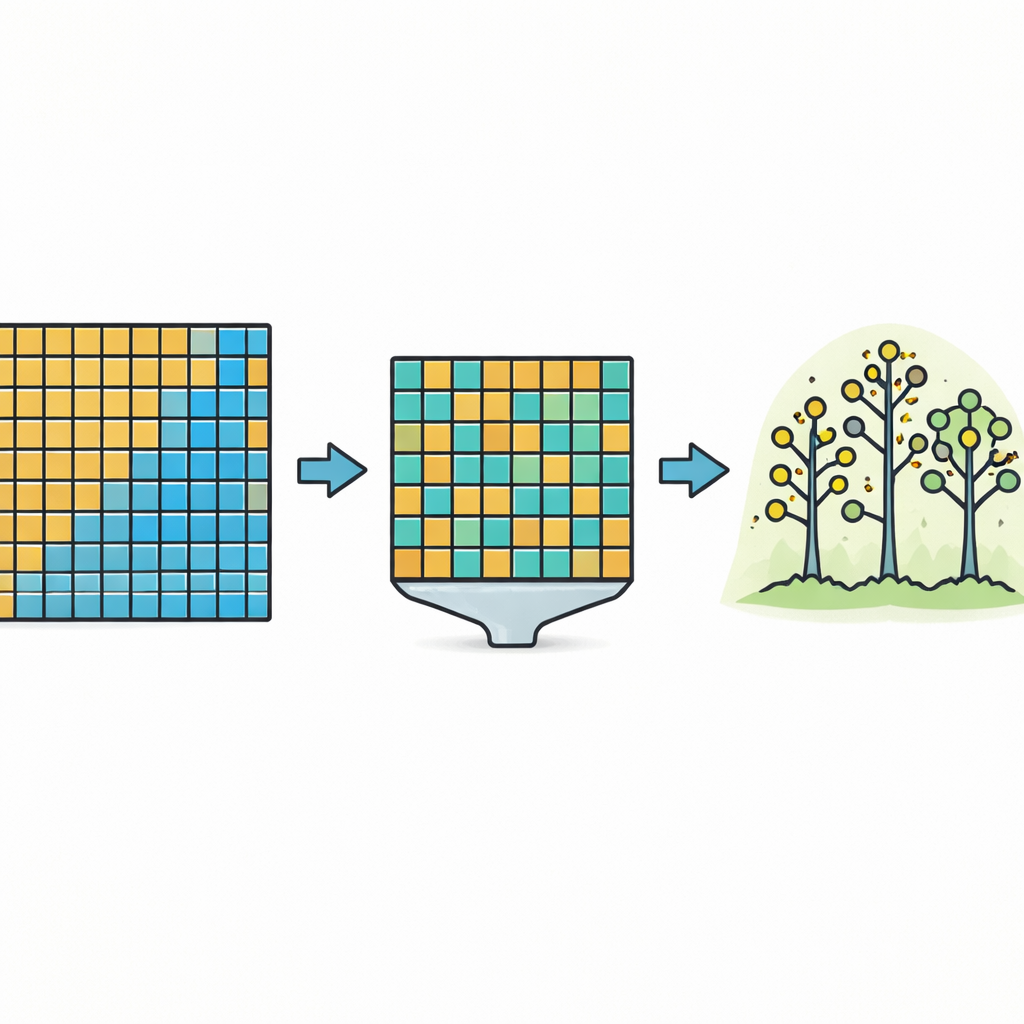
Das Problem ungleicher Beispiele
Standardverfahren des maschinellen Lernens arbeiten am besten, wenn die Daten ausgeglichen sind—wenn für jede Zielklasse in etwa gleich viele Beispiele vorliegen. In der Praxis dominieren jedoch in vielen Aufgaben die seltenen Ereignisse. Beispielsweise zeigen nur wenige medizinische Untersuchungen einen Tumor, und nur ein verschwindend kleiner Anteil an Transaktionen ist betrügerisch. Dieses Ungleichgewicht macht es einfach, dass ein Algorithmus auf dem Papier gut aussieht, indem er meist das häufige Ergebnis vorhersagt, selbst wenn er die seltenen Fälle immer wieder verpasst. Mit wachsendem Abstand zwischen Mehrheit und Minderheit verschiebt sich die Entscheidungsgrenze des Modells zugunsten der Mehrheit, und die seltene Klasse wird schwerer erkennbar.
Die Waage ausgleichen durch intelligentes Sampling
Forscher versuchen oft, solche Daten vor dem Training auszugleichen. Eine Möglichkeit ist, die Mehrheitsklasse zu verkleinern (Under-Sampling), also einige häufige Fälle zu verwerfen, um die Anzahl der seltenen Beispiele anzugleichen. Eine andere besteht darin, seltene Beispiele zu kopieren oder neu zu erzeugen (Over-Sampling), um ihre Präsenz zu erhöhen, ohne Originaldaten zu verlieren. Ein dritter, hybrider Ansatz mischt beide Ideen, indem er einige Mehrheitsbeispiele entfernt und gleichzeitig die Minderheit verstärkt. Jede Strategie hat Vor- und Nachteile: Durch Wegwerfen gehen womöglich nützliche Informationen verloren, während übermäßig viele Duplikate das Training verlangsamen und Overfitting begünstigen können. Die Autoren nutzen alle drei Strategien, um gleichmäßigere Trainingssätze zu erstellen, die an die jeweiligen Daten angepasst sind.
Ein Wald aus Entscheidungsbäumen lehren und stutzen
Die Studie konzentriert sich auf Random Forests, eine Ensemble-Methode, die viele Entscheidungsbäume auf leicht unterschiedlichen Datenstichproben erzeugt und deren Stimmen dann kombiniert. Random Forests sind dafür bekannt, komplexe Daten zu verarbeiten und aufzuzeigen, welche Merkmale am wichtigsten sind. Wenn sie jedoch auf stark unausgeglichenen Daten trainiert werden, können auch große Wälder zugunsten der Mehrheitsklasse verzerrt sein. In der vorgeschlagenen Methode gleichen die Autoren zunächst die Daten durch Under-Sampling, Over-Sampling oder eine hybride Variante aus. Anschließend wachsen sie viele Bäume nach dem üblichen Random-Forest-Verfahren, allerdings mit einer wichtigen Wendung: Anstatt jeden Baum zu behalten, bewerten sie jeden mithilfe der Out-of-Bag-Beobachtungen—Datenpunkte, die beim Aufbau dieses bestimmten Baums nicht verwendet wurden—und verwerfen die Hälfte mit den schlechtesten Fehlerquoten. Dieser Beschneidungsschritt liefert einen kleineren, selektiveren Wald, der aus den zuverlässigsten Bäumen besteht.
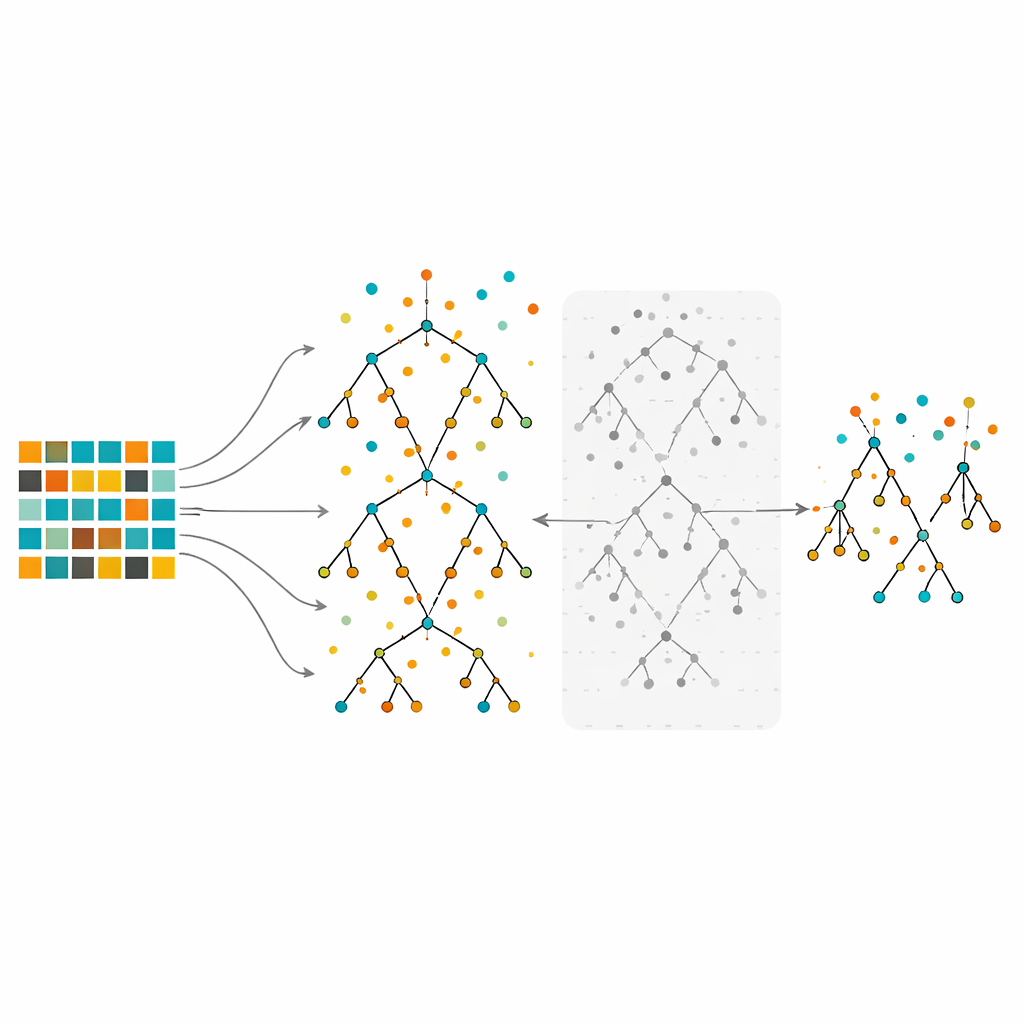
Test auf vielen realen Datensätzen
Um zu prüfen, wie gut dieser beschnittene Wald funktioniert, testen die Autoren ihn an zehn öffentlich verfügbaren Datensätzen, die ein breites Anwendungsspektrum abbilden—von medizinischen und biologischen Messungen bis zu Spam-Erkennung in E-Mails und Schallerkennung. Jeder Datensatz hat zwei Klassen, wobei eine deutlich seltener ist als die andere; sie unterscheiden sich in Größe, Merkmalsanzahl und Ausmaß des Ungleichgewichts. Die neue Methode wird mit mehreren verbreiteten Ansätzen verglichen: k-Nächste-Nachbarn, ein einzelner Entscheidungsbaum, ein Standard-Random-Forest, eine Balanced-Random-Forest-Variante und Support-Vektor-Maschinen. Über verschiedene Sampling-Strategien hinweg erzielt der beschnittene Wald auf den meisten Datensätzen konstant geringere Klassifikationsfehler als die Alternativen. Die Kombination aus hybridem Sampling und Beschneidung liefert insgesamt die besten Ergebnisse, sowohl hinsichtlich Genauigkeit als auch in stabiler Leistung über alle zehn Aufgaben hinweg.
Scharfkantigere Modelle, die weniger Aufwand verschwenden
Neben der Genauigkeit verbessert der Ansatz auch die Effizienz. Durch das Entfernen weniger effektiver Bäume ist das finale Ensemble kleiner und benötigt weniger Rechenaufwand für Training und Vorhersagen, ohne die Fähigkeit zur Erkennung seltener Fälle zu opfern—oft verbessert sie sich sogar. Statistische Tests bestätigen, dass die Verbesserungen gegenüber konkurrierenden Methoden nicht zufällig sind. Für Praktiker mit unausgeglichenen Daten zeigt diese Arbeit, dass sorgfältiges Ausgleichen des Trainingssatzes und anschließendes Beschneiden eines Random Forest basierend auf Out-of-Bag-Leistung Modelle hervorbringen kann, die sowohl genauer als auch effizienter sind. Alltäglich ausgedrückt hilft die Methode Algorithmen, den seltenen, aber wichtigen Signalen in einem Meer gewöhnlicher Beispiele die angemessene Aufmerksamkeit zu schenken.
Zitation: Faiz, N., Iftikhar, S., Jan, S. et al. Pruning tree forest and re-sampling for class imbalanced problem. Sci Rep 16, 8087 (2026). https://doi.org/10.1038/s41598-026-38320-1
Schlüsselwörter: Klassenungleichgewicht, Random Forest, Resampling, Maschinelles Lernen, Ensemble-Methoden