Clear Sky Science · de
Föderiertes Lernen für heterogene elektronische Gesundheitsakten-Systeme mit kosteneffizienter Teilnehmerauswahl
Warum das Teilen von Krankenhausdaten so schwierig ist
Moderne Krankenhäuser sammeln enorme Mengen digitaler Informationen über ihre Patientinnen und Patienten, von Laborwerten und Vitalzeichen bis hin zu Medikamenten und Eingriffen. Theoretisch sollte das Zusammenführen dieser Daten aus vielen Einrichtungen es Ärzten ermöglichen, intelligentere Computermodelle zu entwickeln, die vorhersagen, wer gefährdet ist und welche Behandlungen am meisten helfen könnten. Praktisch verwenden Krankenhäuser jedoch unterschiedliche Softwaresysteme, speichern Daten in inkompatiblen Formaten und müssen gleichzeitig die Privatsphäre der Patienten und ihr Budget strikt schützen. Diese Studie untersucht, wie Krankenhäuser voneinander lernen können, ohne Daten zu kopieren oder zu viel zu investieren.
Gemeinsames Training ohne Austausch roher Datensätze
Die Autoren bauen auf einem Ansatz namens föderiertes Lernen auf, bei dem jedes Krankenhaus ein lokales Modell auf seinen eigenen Patientendaten trainiert und nur Modellupdates, nicht die Rohdaten, weitergibt. Ein zentrales „Host“-Krankenhaus koordiniert diesen Prozess und zielt darauf ab, ein Vorhersagemodell für seine eigenen Bedürfnisse zu verbessern, etwa zur Vorhersage von Komplikationen auf der Intensivstation. Andere Krankenhäuser, sogenannte Subjects, beteiligen sich im Austausch gegen eine Entschädigung. Dieses Setup vermeidet das Verschieben sensibler Akten zwischen Institutionen, wirft aber zwei schwierige Fragen auf: Wie geht man mit vielen verschiedenen Aufzeichnungssystemen um, und wie vermeidet man Zahlungen an Partner, die dem Modell faktisch nicht helfen?
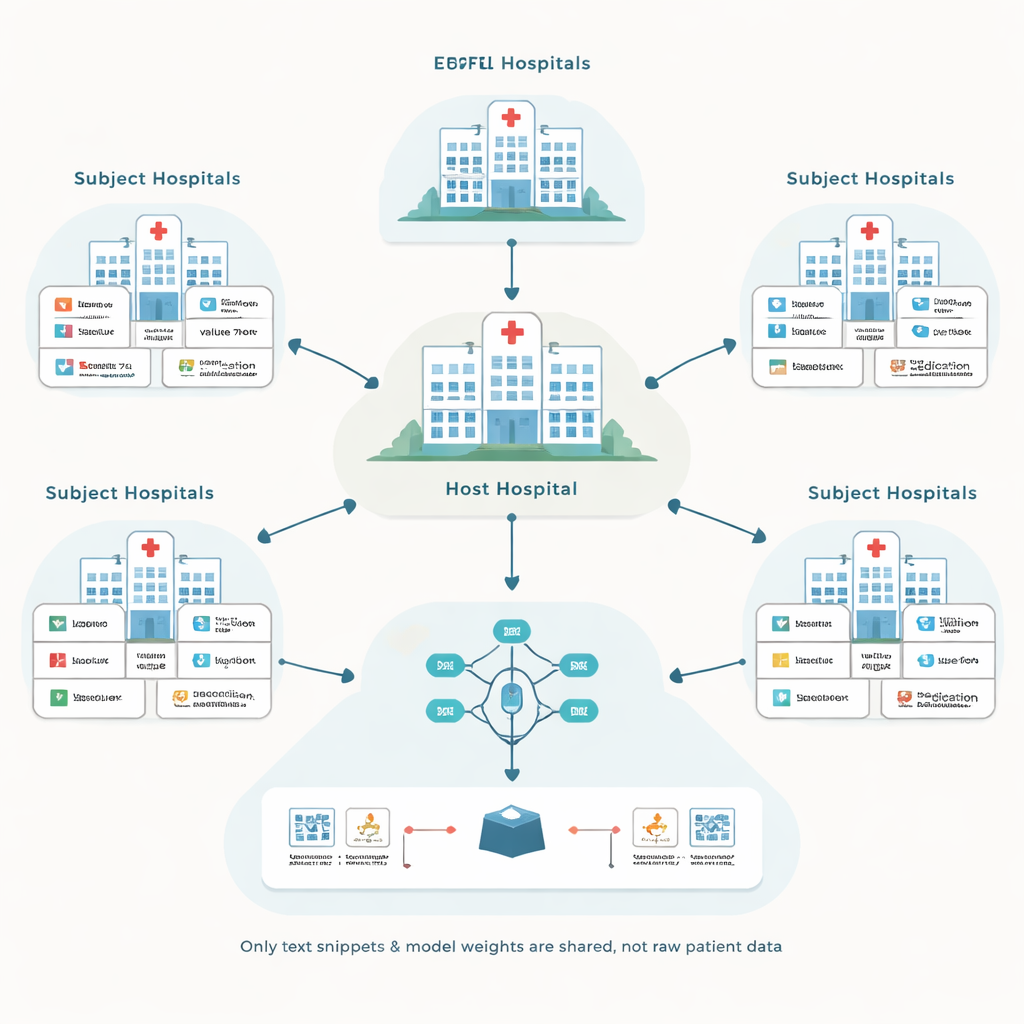
Unordentliche Akten in eine gemeinsame Sprache überführen
Systeme für elektronische Gesundheitsakten unterscheiden sich stark darin, wie Informationen beschriftet und kodiert werden. Ein Krankenhaus kann einen Blutzuckertest unter einem numerischen Code speichern, während ein anderes denselben Test mit einem anderen Code erfasst. Traditionelle Lösungen versuchen, alles in eine einzige, sorgfältig gestaltete Standarddatenbank zu überführen, was teuer ist und viele Expertenstunden erfordert. Stattdessen wandelt das vorgeschlagene Framework, genannt EHRFL, jedes medizinische Ereignis in ein kurzes Textstück um. Ein Laboreintrag wie eine Glukosemessung wird beispielsweise zu einer Formulierung wie „Laborevent Glukose Wert 70 mg/dL.“ Da jedes Krankenhaus bereits Wörterbücher pflegt, die lokale Codes in menschenlesbare Namen abbilden, lässt sich diese Umwandlung automatisieren, ohne aufwendige manuelle Anpassungen.
Patientenprofile aus Text erstellen
Sobald Ereignisse als Text vorliegen, nutzt EHRFL moderne Sprachverarbeitungsmodelle, um jedes Ereignis in einen numerischen Vektor zu verwandeln, und fasst dann viele Ereignisse zu einer einzigen „Patienten-Einbettung“ zusammen – einer kompakten Zusammenfassung der Krankengeschichte dieser Person über ein Zeitfenster. Diese Einbettungen fließen in eine Vorhersageschicht, die mehrere klinische Aufgaben gleichzeitig angeht, etwa die Vorhersage von Todesfällen im Krankenhaus oder von Nierenschäden nach einer Intensivaufnahme. Die Autoren führen ein föderiertes Training an fünf großen, realen Intensivdatensätzen durch, die verschiedene Krankenhäuser, Zeiträume und Aktensysteme abdecken. Über eine Reihe von Algorithmen, einschließlich gängiger föderierter Methoden, schneiden Modelle, die mit diesem textbasierten Ansatz trainiert wurden, durchgängig besser ab als Modelle, die nur an einem einzelnen Krankenhaus trainiert wurden, obwohl die zugrundeliegenden Datenformate unterschiedlich sind.
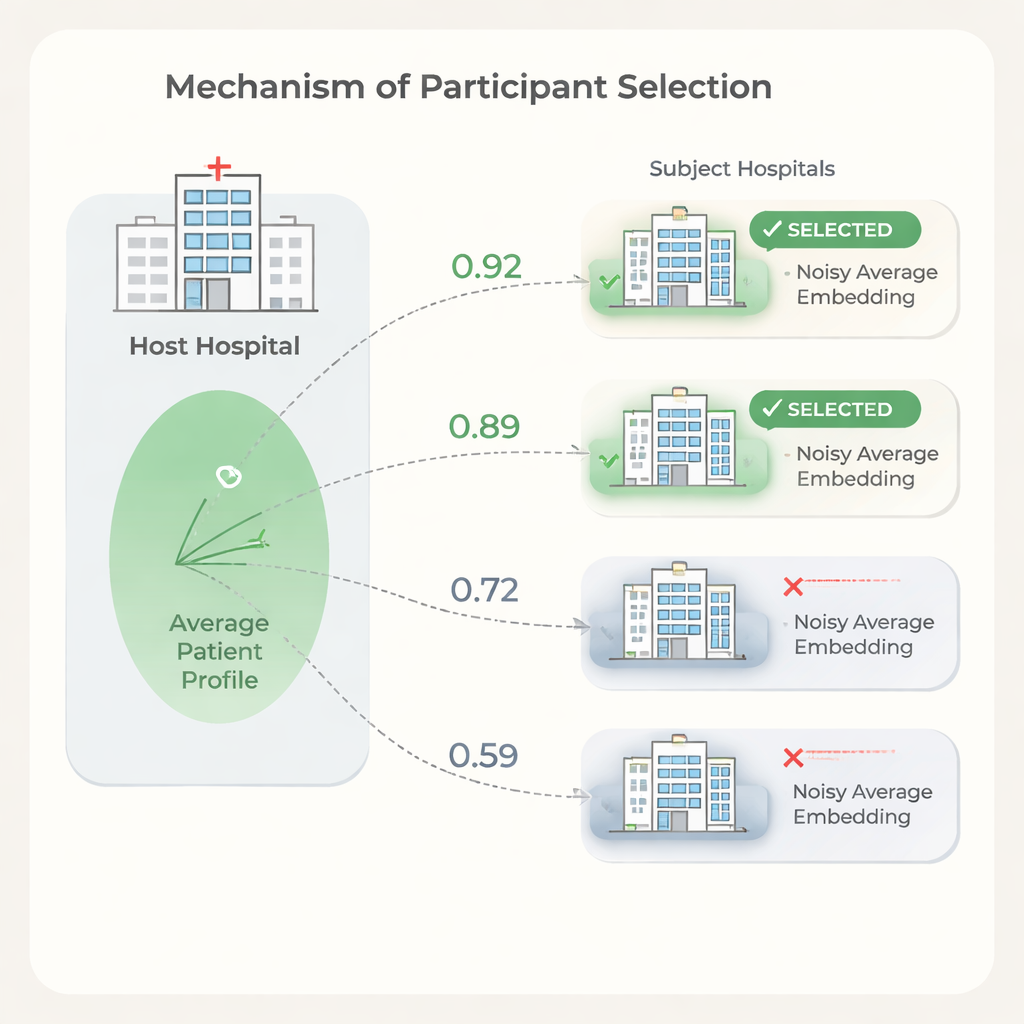
Die richtigen Partner auswählen und dabei Privatsphäre wahren
Mehr Partnerkrankenhäuser führen nicht immer zu besseren Ergebnissen. Einige Einrichtungen haben Patientenpopulationen oder Dokumentationsmuster, die sich so sehr vom Host unterscheiden, dass ihre Einbeziehung das Training verlangsamen oder die Leistung leicht verschlechtern kann, während sie dennoch Kosten verursachen. Um dem entgegenzuwirken, schlagen die Autoren einen Auswahlschritt vor, der auf der Ähnlichkeit zwischen den Patienten-Einbettungen der Krankenhäuser basiert. Der Host trainiert zunächst ein Modell auf seinen eigenen Daten, teilt die Modellgewichte, und jedes Kandidatenkrankenhaus nutzt diese, um Patienten-Einbettungen zu berechnen. Zum Schutz der Privatsphäre schneidet jedes Subject extreme Werte aus seinen Einbettungen, mittelt sie zu einem einzigen Vektor und fügt dann sorgfältig kalibriertes Rauschen hinzu, bevor es nur diesen verrauschten Mittelwert an den Host sendet. Der Host vergleicht seinen eigenen Mittelwert mit dem jedes Subjects mittels einfacher Ähnlichkeitsmaße und wählt nur die ähnlichsten Krankenhäuser für den vollständigen föderierten Lauf aus.
Geld sparen ohne Genauigkeitsverlust
Experimente zeigen, dass die Ähnlichkeit zwischen den durchschnittlichen Patienten-Einbettungen der Krankenhäuser mit dem Ausmaß übereinstimmt, in dem jedes Krankenhaus die Vorhersageleistung des Hosts verbessert oder verschlechtert. Nutzt der Host dieses Signal zur Partnerauswahl, kann er Krankenhäuser mit geringer Ähnlichkeit ausschließen und dabei die Vorhersagequalität im Vergleich zur Nutzung aller verfügbaren Standorte beibehalten oder sogar verbessern. Die Autoren skizzieren zudem ein Kostenmodell, das zeigt, dass aufgrund von Nutzungsgebühren und Trainingszeit, die mit der Anzahl der teilnehmenden Krankenhäuser skalieren, schon moderate Reduktionen der Partner zu erheblichen Einsparungen führen können. Gleichzeitig ist der Auswahlschritt leichtgewichtig: Das Modell wird einmal trainiert, und jedes Krankenhaus führt nur einfache Berechnungen an einem einzigen gemittelten Vektor durch.
Was das für die künftige KI im Gesundheitswesen bedeutet
Für Leser außerhalb des Fachgebiets lautet die Kernbotschaft: Es könnte möglich sein, dass Krankenhäuser „gemeinsam lernen“, ohne rohe Patientenakten zu poolen, und dies auf eine Weise, die sowohl die Privatsphäre als auch finanzielle Beschränkungen respektiert. Indem unterschiedliche Akten in eine gemeinsame Textform übersetzt und anschließend datenschutzwahrende Zusammenfassungen von Patientenpopulationen zur Auswahl kompatibler Partner verwendet werden, bietet EHRFL ein praktisches Rezept zum Aufbau krankenhausspezifischer Vorhersagewerkzeuge. Obwohl die Studie sich auf Intensivfalldaten konzentriert, könnten dieselben Ideen auf ambulante Kliniken, Notaufnahmen und sogar nicht-medizinische Bereiche ausgeweitet werden, in denen Organisationen zusammen an besseren Modellen arbeiten möchten, ohne die Kontrolle über ihre Daten aufzugeben.
Zitation: Kim, J., Kim, J., Hur, K. et al. Federated learning for heterogeneous electronic health record systems with cost effective participant selection. Sci Rep 16, 6876 (2026). https://doi.org/10.1038/s41598-026-38299-9
Schlüsselwörter: föderiertes Lernen, elektronische Gesundheitsakten, Patientenprivatsphäre, klinische Vorhersage, KI im Gesundheitswesen