Clear Sky Science · de
NeuroAction: ein neuro-evolutionärer Ansatz für Reinforcement Learning bei autonomen Fahrzeugen
Warum intelligentere Fahrstile wichtig sind
Die meisten von uns stellen sich selbstfahrende Autos als ruhige, vollkommen rationale Fahrer vor. Die heutigen Systeme verfolgen jedoch meist eine einzige Mischung von Zielen – etwa nicht zu kollidieren und gleichzeitig schnell ans Ziel zu kommen – und diese Mischung wird von Ingenieuren vorgegeben. NeuroAction, der in diesem Beitrag beschriebene Ansatz, zielt darauf ab, autonomen Fahrzeugen eher menschliche Flexibilität zu verleihen: die Fähigkeit, aus vielen sicheren Fahrstilen zu wählen, von vorsichtigem "Baby an Bord"-Verhalten bis zu zügigem Autobahnfahren, ohne das Fahrzeug bei jeder Änderung neu trainieren zu müssen.
Von Einheitslösungen zu vielen sicheren Optionen
Aktuelle Deep-Reinforcement-Learning-Systeme fürs Fahren lernen durch Trial-and-Error: Sie beobachten die Straße, führen Aktionen wie Lenken und Beschleunigen aus und erhalten eine einzelne numerische Belohnung, die verschiedene Ziele wie Geschwindigkeit, Sicherheit und Spurtreue vermischt. Um das System anzupassen, müssen Ingenieure diese eine Belohnung sehr sorgfältig entwerfen. Wird der Geschwindigkeit zu großes Gewicht gegeben, kann das Fahrzeug aggressiv fahren; wird die Sicherheit überbetont, könnte es im Schneckentempo unterwegs sein. Präferenzen später zu ändern bedeutet in der Regel, ein großes neuronales Netzwerk von Grund auf neu zu trainieren, was langsam ist, viel Speicher braucht und empfindlich gegenüber technischen Einstellungen.
Fahrt in einfache Ziele aufteilen
NeuroAction begegnet dem, indem die Fahraufgabe in mehrere klare Ziele anstatt eines einzigen aufgeteilt wird. In der Studie wird der virtuelle Fahrer des Fahrzeugs unabhängig an drei Kriterien bewertet: wie schnell er innerhalb eines sicheren Bereichs fährt, wie treu er in der rechten (typischerweise sichereren) Spur bleibt, und wie gut er Kollisionen vermeidet. Anstatt diese in einer einzigen Punktzahl zusammenzufassen, behandelt die Methode sie als separate Messgrößen. Im Hintergrund wird jede mögliche Fahrpolicy – das neuronale Netzwerk, das Sensorinformationen in Lenk- und Geschwindigkeitsentscheidungen umsetzt – gleichzeitig entlang aller drei Achsen bewertet.
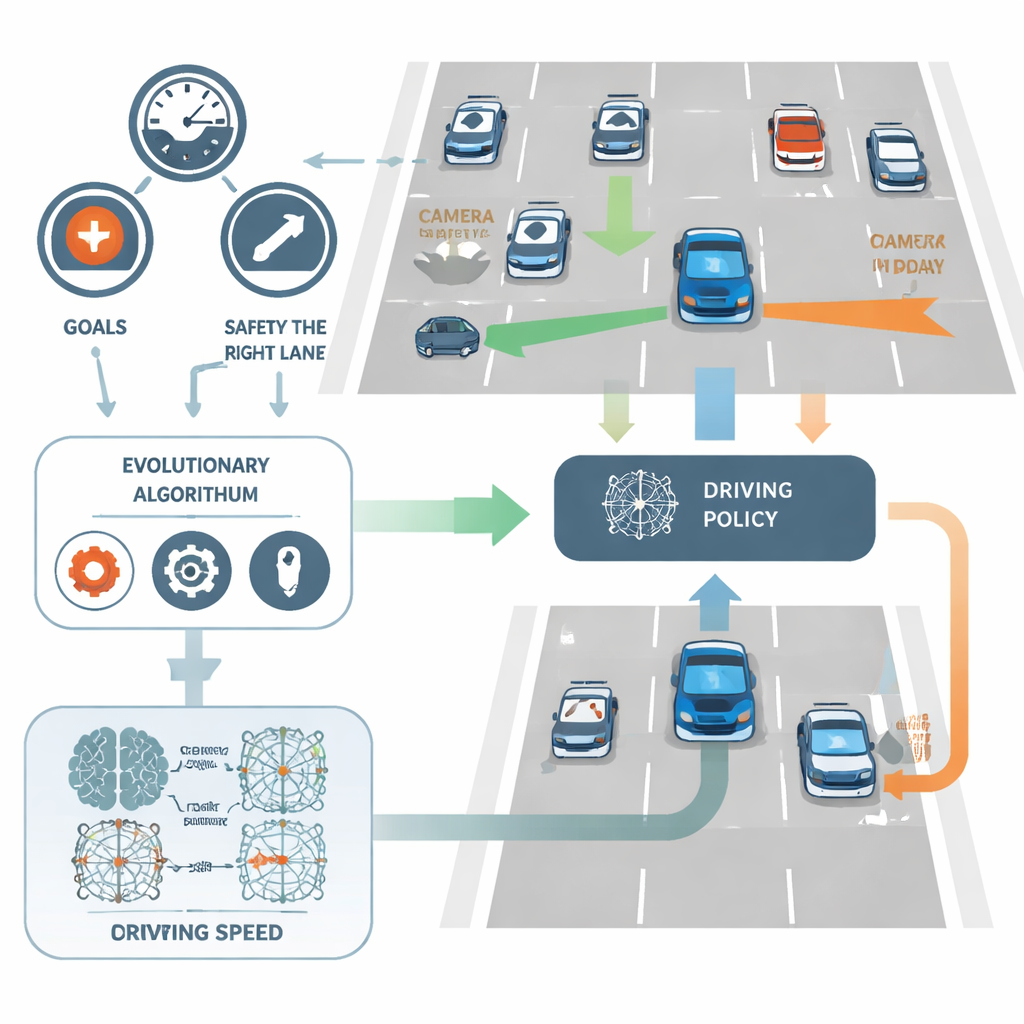
Lass die Evolution nach besseren Fahrern suchen
Anstelle des Feinabstimmens von Netzwerkgewichten mit der üblichen Backpropagation-Technik nutzt NeuroAction Ideen aus der biologischen Evolution. Eine Population unterschiedlicher Fahrpolicies wird erzeugt und in einer simulierten Autobahnumgebung getestet. Policies, die gute Kompromisse zwischen Geschwindigkeit, Spurdiziplin und Sicherheit finden, werden behalten und rekombiniert, während schlechtere verworfen werden. Über viele Generationen entdeckt dieser evolutionäre Prozess eine ganze Front starker Lösungen – bekannt als Pareto-Front – auf der keine Policy in einem Ziel verbessert werden kann, ohne mindestens eines der anderen zu opfern.
Vergleich evolutionärer und gradientenbasierter Lernverfahren
Die Forschenden wendeten NeuroAction auf einen weit verbreiteten 2D-Autobahn-Simulator an und nutzten einen standardmäßigen, neuronalen Fahragenten. Sie optimierten dann die Parameter des Agenten mit mehreren etablierten Multi-Objective-Evolutionsalgorithmen und verglichen, wie gut jeder die Bandbreite wünschenswerter Kompromisse abdecken konnte. Eine wichtige Leistungskennzahl, das „Hypervolumen“ der entdeckten Frontier, erfasst sowohl die Qualität als auch die Vielfalt der Lösungen. Ein Algorithmus, NSGA-II, erzielte die beste Gesamtdeckung, während ein naher Verwandter, NSGA-III, besonders konsistente Ergebnisse über wiederholte Läufe lieferte.
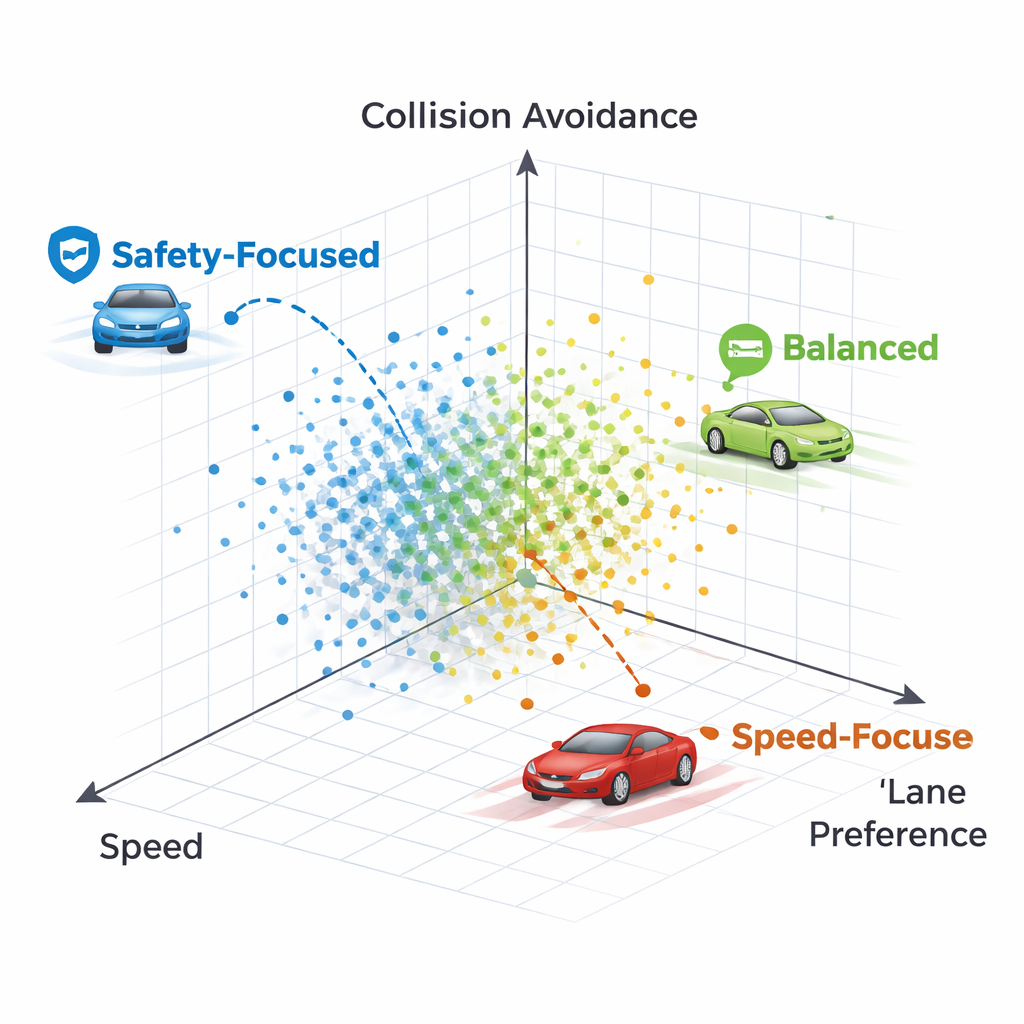
Wie unterschiedliche Fahrstile aussehen
Beim Betrachten einzelner Policies auf der Pareto-Front zeigen die Autorinnen und Autoren, dass jeder Punkt einem erkennbar anderen Fahrstil entspricht. Eine Policy hält fast um jeden Preis strikt in der rechten Spur, opfert dabei Geschwindigkeit und kollidiert schließlich mit einem sehr langsamen Fahrzeug vor ihr – eine übervorsichtige Strategie, die der Spurpräferenz zu viel Gewicht gibt. Eine andere Policy wechselt zunächst die Spur, kehrt dann aber in eine freie rechte Spur zurück, hält höhere Geschwindigkeit und vermeidet dennoch Unfälle. Im Allgemeinen erzeugen die Methoden ein Spektrum von Strategien, das von konservativen Spurhaltefahrern bis zu durchsetzungsfähigeren, aber immer noch sicheren Reisenden reicht, die alle gleichzeitig ohne Nachtraining verfügbar sind.
Was das für zukünftige selbstfahrende Autos bedeutet
Für Nichtfachleute ist die zentrale Botschaft, dass NeuroAction das Training selbstfahrender Autos in die Suche nach vielen guten Optionen statt einem festen Verhalten verwandelt. Dadurch lässt sich eine Fahrpolicy auswählen, die zur Situation passt – langsam und extrem sicher beim Transport von Kindern, schneller wenn Eile geboten ist – und dabei weiterhin Sicherheitsbeschränkungen respektieren. Obwohl die aktuellen Experimente in Simulationen und mit vereinfachten Zielen durchgeführt wurden, weist das Konzept in Richtung anpassungsfähigerer, präferenzbewusster autonomer Fahrzeuge, die personalisierte und zugleich verlässliche Fahrstile auf einer soliden mathematischen Grundlage bieten können.
Zitation: Aboyeji, E., Ajani, O.S., Fenyom, I. et al. NeuroAction: a neuroevolutionary approach to reinforcement learning for autonomous vehicles. Sci Rep 16, 7403 (2026). https://doi.org/10.1038/s41598-026-38269-1
Schlüsselwörter: autonomes Fahren, Reinforcement Learning, evolutionäre Algorithmen, Multi-Objective-Optimierung, selbstfahrende Autos