Clear Sky Science · de
Ranglose Tensorzerlegung durch metrisches Lernen
Muster finden in einem Meer von Daten
Die moderne Wissenschaft erstickt in komplexen Daten: Stapel medizinischer Aufnahmen, Karten der Gehirnaktivität, astronomische Bilder und Simulationen von Materialien. Aus diesen Daten sinnvolle Erkenntnisse zu gewinnen bedeutet oft, sie in einfachere Formen zu pressen, ohne das Wesentliche zu verlieren. Dieses Papier stellt einen neuen Weg vor. Anstatt zu versuchen, jedes Pixel originalgetreu wiederherzustellen, konzentriert es sich darauf, die echten Beziehungen zwischen Proben einzufangen – welches Gehirn einem anderen ähnelt, welche Galaxienform welcher anderen entspricht – sodass die resultierende Abbildung der Daten Bedeutung wiedergibt statt roher Details.
Vom Rekonstruieren von Bildern zum Messen von Ähnlichkeit
Traditionelle Werkzeuge zur Vereinfachung mehrdimensionaler Daten, bekannt als Tensorzerlegungen, funktionieren ein wenig wie das Zerlegen eines Akkords in einzelne Töne. Sie zerlegen einen Datenblock in eine kleine Zahl grundlegender Muster plus Gewichte. Dazu muss im Voraus festgelegt werden, wie viele Muster – der „Rang“ – erlaubt sind, und der Erfolg wird daran bemessen, wie gut die ursprünglichen Daten rekonstruiert werden können. Das ist ideal für Kompression oder Rauschunterdrückung, aber nicht notwendigerweise für Aufgaben wie „gehören diese beiden Gesichter zur gleichen Person?“ oder „gehört dieser Hirnscan zu einem autistischen oder typischen Probanden?“, wo korrektes Gruppieren wichtiger ist als perfekte Rekonstruktion.
Parallel dazu hat Deep Learning eine andere Idee populär gemacht: Anstatt einen Tensor algebraisch zu zerlegen, lernt man durch ein neuronales Netz einen kompakten numerischen Code oder eine Einbettung. Klassische Autoencoder fokussieren weiterhin die Rekonstruktion. Diese Arbeit dreht das Ziel um. Sie schlägt ein „rangloses“ Framework vor, das keinen Rang im Voraus festlegt und dem pixelgenaue Wiederherstellung egal ist. Stattdessen lernt es ein Distanzmaß, sodass Punkte, die nahe beieinander liegen sollten (gleiche Person, gleiche Diagnose, gleiche physikalische Klasse), im Einbettungsraum Nachbarn werden und sich Punkte, die unterschiedlich sein sollten, voneinander entfernen.
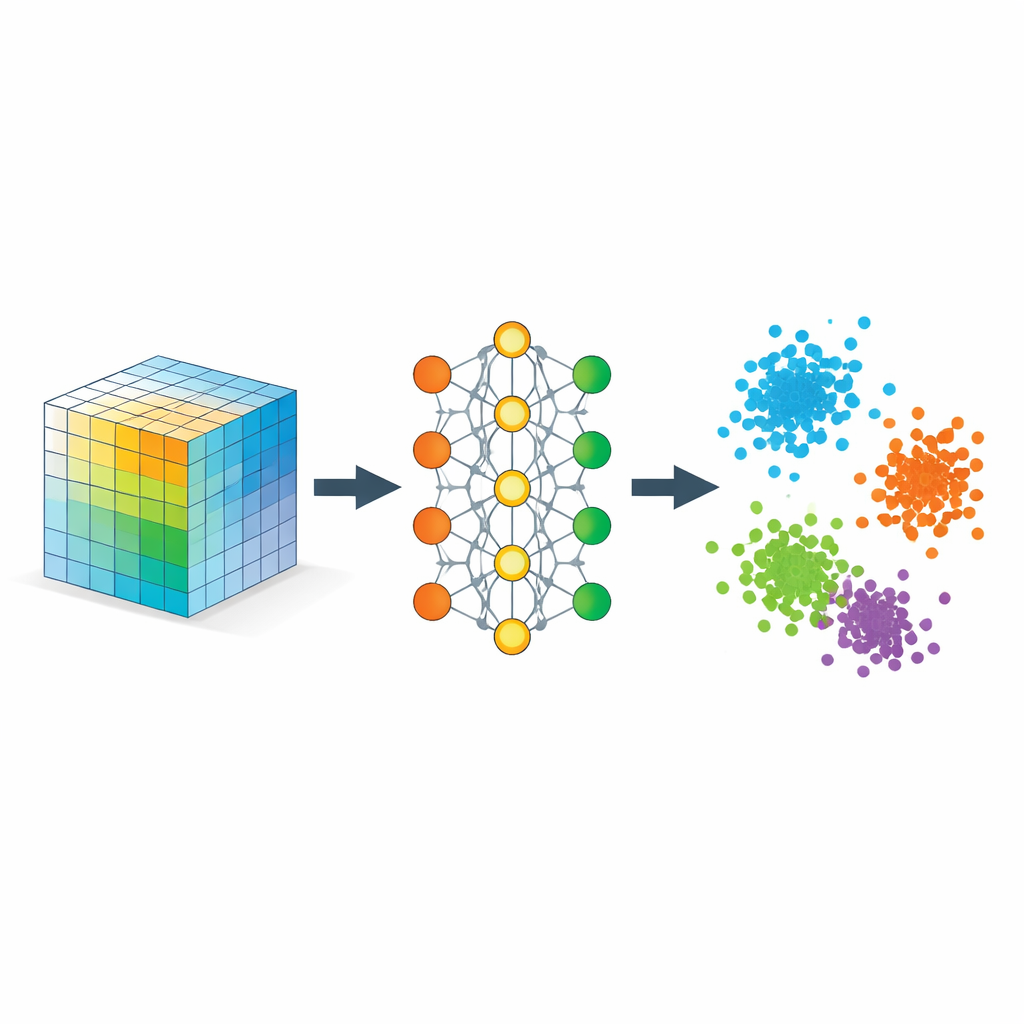
Dem Netzwerk beibringen, was „nah“ bedeuten soll
Die Schlüsselkomponente ist eine Strategie namens metrisches Lernen, hier umgesetzt durch Tripel von Beispielen: ein Anker, ein positives Beispiel desselben Typs und ein negatives Beispiel eines anderen Typs. Während des Trainings wird das Netzwerk belohnt, wenn der Anker näher am positiven als am negativen Beispiel ist, um eine Sicherheitsmarge. Über viele solche Tripel formt diese einfache Regel den Einbettungsraum so, dass Distanzen semantische Ähnlichkeit widerspiegeln statt rohe Pixelähnlichkeit. Zusätzliche Regularisierer ermutigen das Netzwerk, Informationen gleichmäßig über die Dimensionen zu verteilen, vermeiden, dass alles zu einer Linie kollabiert, und erhalten lokale Nachbarschaften weitgehend, sodass Punkte, die im ursprünglichen Datenraum nahe beieinanderliegen, auch in der Einbettung nahe bleiben.
Mathematisch zeigen die Autoren, dass sich diese Einbettung wie eine flexible Tensorzerlegung verhält, aber ohne vorgegebenen Rang. Die gelernten Koordinaten können als Faktoren in einer klassischen Zerlegung eines Ähnlichkeitstensors interpretiert werden, dessen Einträge messen, wie stark verschiedene Teile der Daten aufeinander abgestimmt sind. Weil das Modell redundante Richtungen bestraft, neigt es dazu, alle Einbettungsdimensionen effektiv zu nutzen und lässt die Daten entscheiden, wie viele sinnvolle Komponenten benötigt werden. Gleichzeitig liefern die Autoren theoretische Garantien, dass Standard-Trainingsverfahren konvergieren und dass die resultierende Geometrie die Klassen zuverlässig trennt, ohne bedeutende lokale Beziehungen stark zu verzerren.
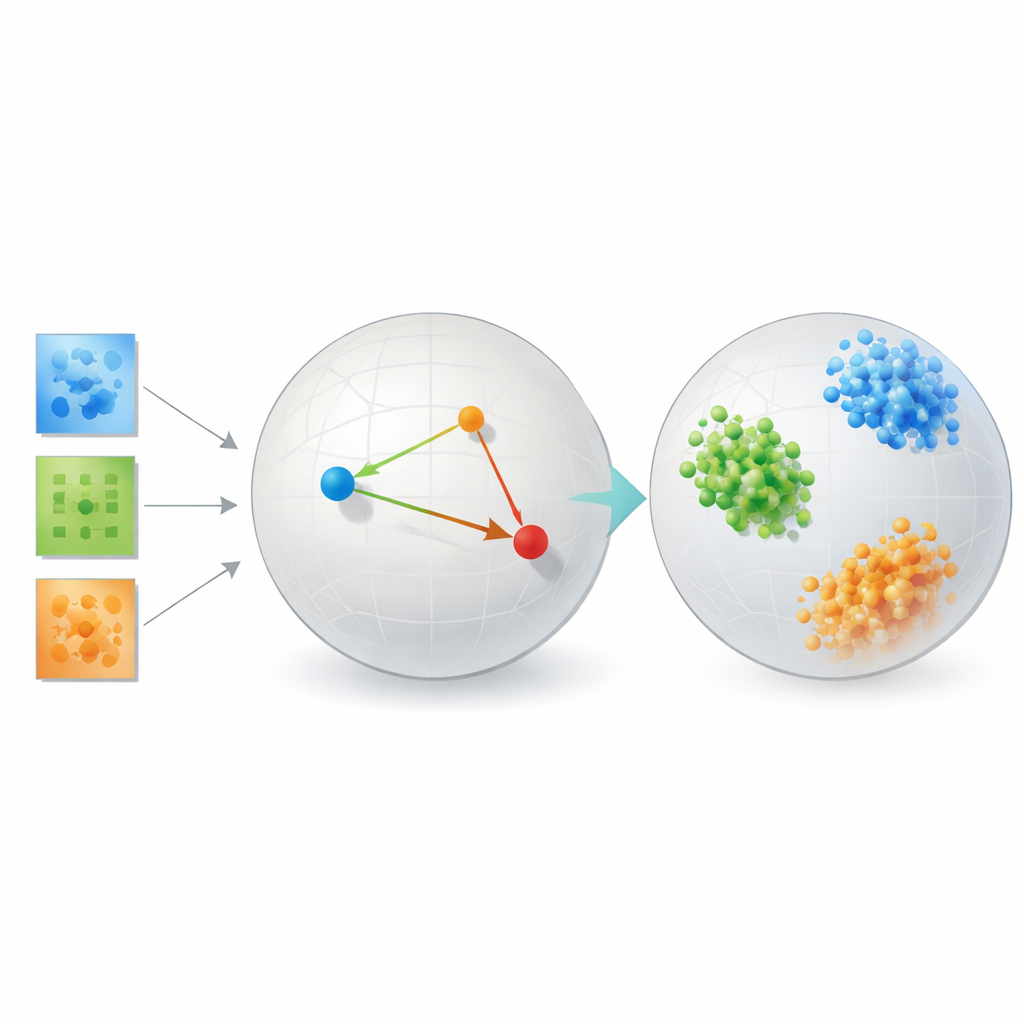
Die Methode auf die Probe stellen
Um zu zeigen, dass ihr Ansatz nicht nur elegante Theorie ist, testet der Autor ihn an mehreren sehr unterschiedlichen Problemen. Bei Benchmarks zur Gesichtserkennung gruppieren die gelernten Einbettungen Bilder derselben Person zu engen, gut getrennten Clustern und übertreffen klassische Methoden wie Hauptkomponentenanalyse, populäre Visualisierungstools wie t-SNE und UMAP sowie traditionelle Tensorzerlegungen mit festem Rang deutlich. Bei Daten zur Gehirnkonnektivität von Personen mit und ohne Autismus findet die Methode einen Raum, in dem sich die beiden Gruppen sauberer trennen lassen als mit rekonstruktionsorientierten Tensorwerkzeugen oder autoencoderbasierten neuronalen Netzen, was darauf hindeutet, dass sie klinisch relevante Muster in der Interaktion von Hirnregionen herausarbeitet.
Die Studie enthält außerdem kontrollierte Simulationen von Galaxienformen und Kristallstrukturen, bei denen die „wahren“ Kategorien genau bekannt sind. Hier clustert das metrische Lern-Framework die synthetischen Galaxien und Kristalle nahezu perfekt nach ihren zugrunde liegenden physikalischen Typen. In all diesen Settings tauscht die Methode konsistent etwas Treue zur ursprünglichen Pixeleinteilung gegen eine Repräsentation ein, in der Ähnlichkeit und Unterschied mit wissenschaftlicher Bedeutung übereinstimmen. Wichtig ist, dass sie dies ohne die gewaltigen Daten- und Rechenressourcen schafft, die oft nötig sind, um transformerbasierte tiefe Modelle zu trainieren, welche in diesen relativ kleinen wissenschaftlichen Datensätzen Probleme hatten.
Warum das für künftige wissenschaftliche Daten wichtig ist
Für Wissenschaftler, die in begrenzten, hochdimensionalen Daten nach Mustern suchen, bietet diese Arbeit eine attraktive Perspektivverschiebung. Anstatt einen Rang zu raten und für Rekonstruktion zu optimieren, können Forschende direkt eine Einbettung anfordern, die die Beziehungen widerspiegelt, die ihnen wichtig sind: gleiche Diagnose, gleiche Materialphase, gleiche astrophysikalische Klasse. Das vorgeschlagene ranglose metrische Lern-Framework zeigt, dass solche Einbettungen sowohl interpretierbar als auch leistungsfähig sein können, besonders wenn Daten knapp sind. Wie der Autor bemerkt, bleiben Herausforderungen – etwa der Umgang mit Klassenungleichgewicht und die Skalierung auf viele Kategorien – bestehen, doch die Botschaft ist klar: In vielen wissenschaftlichen Problemen kann das Erlernen eines guten Ähnlichkeitsbegriffs wertvoller sein als das Rekonstruieren jedes Details des ursprünglichen Signals.
Zitation: Bagherian, M. No-rank tensor decomposition via metric learning. Sci Rep 16, 8326 (2026). https://doi.org/10.1038/s41598-026-38221-3
Schlüsselwörter: metrisches Lernen, Tensorzerlegung, Repräsentationslernen, Dimensionsreduktion, wissenschaftliche Datenanalyse