Clear Sky Science · de
Ein VLM-gesteuertes Netzwerk zur Kopplung von Degradationsmodellierung für degradationsbewusste Fusion von Infrarot- und sichtbaren Bildern
Scharfere Nachtsicht für eine verrauschte Welt
Moderne Kameras können in der Dunkelheit sehen, Wärme erfassen und den Straßenverkehr überwachen – doch ihre Bilder sind oft alles andere als perfekt. Straßenlaternen blenden, Schatten verschlucken Details und Sensoren fügen punktuelles Rauschen hinzu. Diese Studie stellt eine neue Methode vor, um gewöhnliche Farbvideos mit wärmeempfindlichen Infrarotbildern zu verschmelzen, sodass das Ergebnis auch dann klarer und verlässlicher ist, wenn beide Eingangsbilder stark degradierte sind. Das Verfahren könnte autonome Fahrzeuge, Überwachungssysteme und andere intelligente Kameras in den Situationen robuster machen, in denen wir sie am dringendsten brauchen: nachts, bei schlechtem Wetter und in unübersichtlichen, realen Szenen.
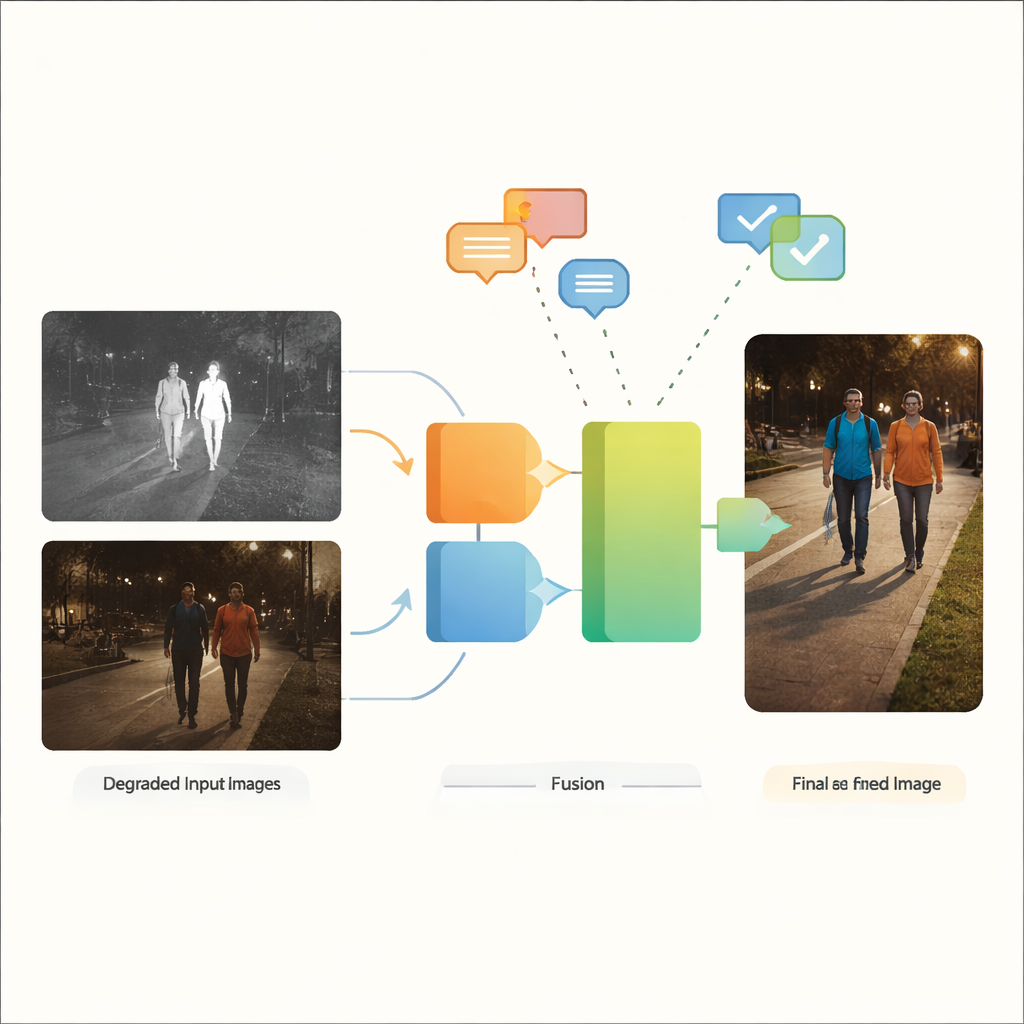
Warum zwei Augen besser sind als eines
Sichtbare Lichtkameras erfassen die reichen Farben und Texturen, an die Menschen gewöhnt sind, haben jedoch bei schwachem Licht, störender Blendung und tiefen Schatten ihre Schwierigkeiten. Infrarotkameras dagegen nehmen Wärme wahr und heben im Dunkeln leicht warme Objekte wie Personen oder Fahrzeuge hervor, obwohl ihre Bilder oft flach wirken und feine Details fehlen. Die Fusion von Infrarot- und sichtbaren Bildern zielt darauf ab, das Beste aus beiden Welten zu vereinen: die klaren Konturen warmer Ziele aus dem Infrarot mit dem Kontext und der Farbgebung des sichtbaren Lichts. Traditionell gehen die meisten Fusionsverfahren jedoch davon aus, dass beide Eingangsaufnahmen bereits sauber und hochwertig sind – eine schlechte Annahme für reale Straßen, Städte und industrielle Umgebungen, in denen Unschärfe, Rauschen, schwache Beleuchtung und Überbelichtung eher die Regel als die Ausnahme sind.
Wenn Vorverarbeitung nicht ausreicht
Bestehende Systeme gehen mit fehlerhaften Bildern typischerweise in zwei voneinander getrennten Schritten um. Zuerst hellen separate Aufwertungswerkzeuge dunkle Szenen auf, reduzieren Rauschen oder korrigieren den Kontrast. Erst danach verschmilzt ein Fusionsnetz die verbesserten Bilder. Dieser zweistufige Ansatz hat mehrere Nachteile. Er zwingt Entwickler, für jeden Defekttyp und jeden Sensor unterschiedliche Enhancer auszuwählen und abzustimmen, was Workflows brüchig und komplex macht. Wichtiger ist: Informationen, die bei der separaten Aufbereitung verloren gehen oder verzerrt werden, lassen sich in der anschließenden Fusionsphase nicht wiederherstellen. Einige neuere Arbeiten führten spezielle Netze ein, die auf eine bestimmte Art von Degradation zugeschnitten sind, oder nutzten sprachgesteuerte Modelle, die jeweils nur eine schlechte Modalität bearbeiten. Wenn jedoch sowohl Infrarot- als auch sichtbare Bilder degradierte sind – und oft auf unterschiedliche Weise – sind diese Strategien weiterhin stark auf manuelle Vorverarbeitung angewiesen und haben Schwierigkeiten mit gemischten, realen Bedingungen.
Ein Fusionsnetz, das Degradation versteht
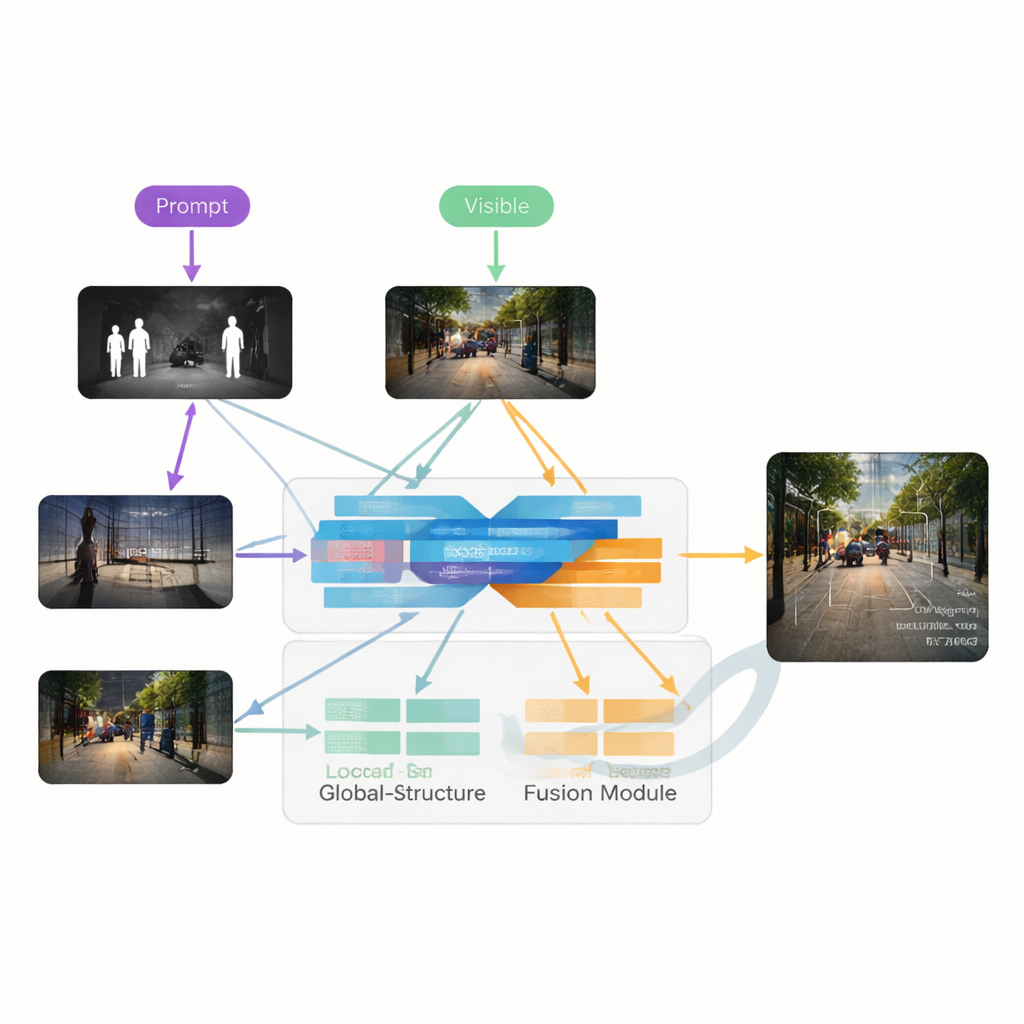
Die Autoren schlagen VGDCFusion vor, ein neues Deep-Learning-Framework, das die Behandlung von Degradationen direkt in den Fusionsprozess einwebt. Die zentrale Idee ist, dem Netzwerk in Worten mitzuteilen, welche Probleme zu erwarten sind, und dieses Wissen dann in jedem Schritt der Merkmalsextraktion und -verschmelzung zu nutzen. Kurze Textprompts beschreiben die Aufgabe (Infrarot–sichtbare Fusion) und die spezifischen auftretenden Probleme wie schwaches Licht, Überbelichtung, niedrigen Kontrast oder Rauschen. Ein leistungsfähiges Vision–Language-Modell – ähnlich in der Grundidee wie Systeme à la CLIP – wandelt diese Prompts in kompakte numerische Deskriptoren um. Diese Deskriptoren steuern zwei Hauptbausteine: den Specific-Prompt Degradation-Coupled Extractor (SPDCE), der getrennt für jede Modalität arbeitet, und den Joint-Prompt Degradation-Coupled Fusion (JPDCF), der Informationen über Modalitäten hinweg zusammenführt und dabei weiterhin darauf achtet, welche Degradationen noch vorhanden sind.
Wie der gesteuerte Fusionsprozess funktioniert
Innerhalb jedes SPDCE-Moduls lenkt die aus dem Prompt abgeleitete Steuerung das Netzwerk auf relevante Merkmale und weg von Artefakten. Multi-Skalen-Faltungsschichten betrachten kleine Nachbarschaften, um Kanten und Texturen zu bewahren, während Transformer-Schichten großräumigere Strukturen und Kontext erfassen. Zusammengenommen lernen sie beispielsweise, wichtige Wärmesignaturen in einem verrauschten Infrarotbild oder schwache Fahrbahnmarkierungen in einem unterbelichteten Sichtbild hervorzuheben und gleichzeitig Sensorrauschen und Beleuchtungsfehler zu unterdrücken. Parallel dazu nehmen JPDCF-Module die bereinigten Merkmale aus beiden Zweigen und kombinieren sie wiederum unter Prompt-Steuerung. Sie nutzen räumliche und Kanal-Aufmerksamkeit, um informative Regionen zu betonen, verbleibende Degradation zu filtern und komplementäre Hinweise zusammenzuführen – etwa eine helle Infrarotkontur eines Fußgängers mit Farbe und Hintergrundstruktur der sichtbaren Kamera zu korrelieren – bevor sie ein fusioniertes Drei-Kanal-Ausgabebild rekonstruieren.
Erprobung der Methode
Um die Nützlichkeit zu demonstrieren, bewertete das Team VGDCFusion auf mehreren öffentlichen Datensätzen, die unter anderem unterbelichtete und überbelichtete sichtbare Bilder sowie verrauschte oder kontrastarme Infrarotbilder enthalten. Sie verglichen ihre Methode mit einer Reihe von State-of-the-Art-Fusionstechniken, darunter Autoencoder, Faltungsnetze, generative gegnerische Netze und Transformer. Mithilfe gängiger Bildqualitätsmaße lieferte VGDCFusion konsistent fusionierte Bilder mit schärferen Kanten, besserem Kontrast und natürlicheren Farben, selbst wenn konkurrierenden Methoden den Vorteil sorgfältig abgestimmter Vorverarbeitung eingeräumt wurde. Der neue Ansatz verbesserte zentrale Metriken in stark degradierten Szenarien im Mittel um etwa 15 %. Wurden die fusionierten Bilder in ein populäres Objekterkennungssystem eingespeist, führte das außerdem zu höheren Erkennungsraten als bei Verwendung nur von Infrarot- oder sichtbaren Bildern allein oder beim Einsatz anderer Fusionsnetze.
Klarere Sicht für sicherere Systeme
Einfach gesagt zeigt diese Arbeit, dass es vorteilhaft ist, einem Bildfusionsnetz mitzuteilen, mit welchen Arten visueller Probleme zu rechnen ist – und es in einem eng gekoppelten Schritt gleichzeitig zu reparieren und zu verschmelzen. Durch die Kopplung von Degradationsmodellierung mit dem Fusionsprozess und den Einsatz sprachgesteuerter Hinweise auf jeder Ebene kann VGDCFusion sich an unterschiedliche und gemischte Formen der Bilddegradation anpassen, ohne ständiges manuelles Nachjustieren. Diese Art von intelligenter, degradationsbewusster Fusion könnte dazu beitragen, dass zukünftige Sehsysteme – von selbstfahrenden Autos bis zu Überwachungskameras – unter den unordentlichen, unvollkommenen Bedingungen der realen Welt verlässlichere Bilder liefern.
Zitation: Zhao, J., Zhang, T. & Cui, G. A VLM guided network coupling degradation modeling for degradation aware infrared and visible image fusion. Sci Rep 16, 8249 (2026). https://doi.org/10.1038/s41598-026-38181-8
Schlüsselwörter: Fusion von Infrarot- und sichtbaren Bildern, Niedriglichtaufnahmen, Vision-Language-Modelle, Bilddegradation, Wahrnehmung im autonomen Fahren