Clear Sky Science · de
Ein hybrides gestapeltes Ensemble-Learning-Framework zur mehrlabeligen Emotionserkennung in Texten
Warum es wichtig ist, Emotionen im Text zu erfassen
Jeden Tag gießen Menschen ihre Gefühle in Social-Media-Beiträge, Bewertungen und Nachrichten. In dieser Flut von Worten verbergen sich frühe Warnzeichen für psychische Belastungen, zunehmende Hassrede und die öffentliche Reaktion auf Krisen und Katastrophen. Computer sehen jedoch meist nur „positiv“ oder „negativ“ und übersehen die Mischung von Gefühlen, die reale Menschen oft gleichzeitig ausdrücken. Dieser Artikel untersucht einen neuen Ansatz, Maschinen beizubringen, mehrere Emotionen in einem einzelnen Textstück zu erkennen — und dies nicht nur in Englisch, sondern auch in Sprachen, die selten von fortgeschrittener künstlicher Intelligenz profitieren.
Über das einfache positiv oder negativ hinaus
Traditionelle Sentiment-Analyse-Tools sind wie grobe Thermometer: Sie zeigen an, ob die Stimmung gut oder schlecht ist, aber nicht, ob jemand zugleich Wut, Angst, Hoffnung oder Erleichterung empfindet. Die Autorinnen und Autoren argumentieren, dass das Erfassen dieses reicheren emotionalen Spektrums für Anwendungen wie Katastrophenhilfe, therapeutische Unterstützung und Kundenbetreuung entscheidend ist. Eine Nachricht, die Angst und Dringlichkeit mischt, könnte beispielsweise sofortige Aufmerksamkeit erfordern, während eine, die Traurigkeit und Optimismus verbindet, eine andere Art von Unterstützung nötig macht. Mehrere parallel vorhandene Emotionen zu erfassen — bekannt als „Multi-Label“-Emotionserkennung — ist daher ein wichtiger Schritt hin zu sensibleren, menschenorientierteren Systemen.
Sprachen, die bisher übersehen wurden, eine Stimme geben
Die meisten leistungsfähigen Sprachtechnologien werden auf Englisch und einigen wenigen weit verbreiteten Sprachen trainiert und abgestimmt. Sprecherinnen und Sprecher von Sprachen mit wenigen Ressourcen — also solchen mit wenigen gelabelten Daten und wenigen digitalen Werkzeugen — bleiben oft zurück. Um diese Lücke zu schließen, konzentriert sich die Studie auf drei Datensätze: ein bekanntes englisches Emotions-Benchmark; eine Bahasa-Indonesia-Sammlung, die sich auf beleidigende und hasserfüllte Sprache konzentriert; und ein brandneues Hausa-Twitter-Korpus, das die Forschenden erstellt haben und HaEmoC_V1 nennen. Der Hausa-Datensatz umfasst mehr als zwölftausend sorgfältig bereinigte und annotierte Tweets, von denen jeder mit einer oder mehreren von elf Emotionen wie Wut, Freude, Vertrauen, Pessimismus und Erwartung versehen ist. Expertinnen und Experten überprüften die Labels, und die Übereinstimmungswerte zeigen, dass die Annotationen sowohl konsistent als auch zuverlässig sind.
Mehrere intelligente Lesegeräte zu einem verbinden
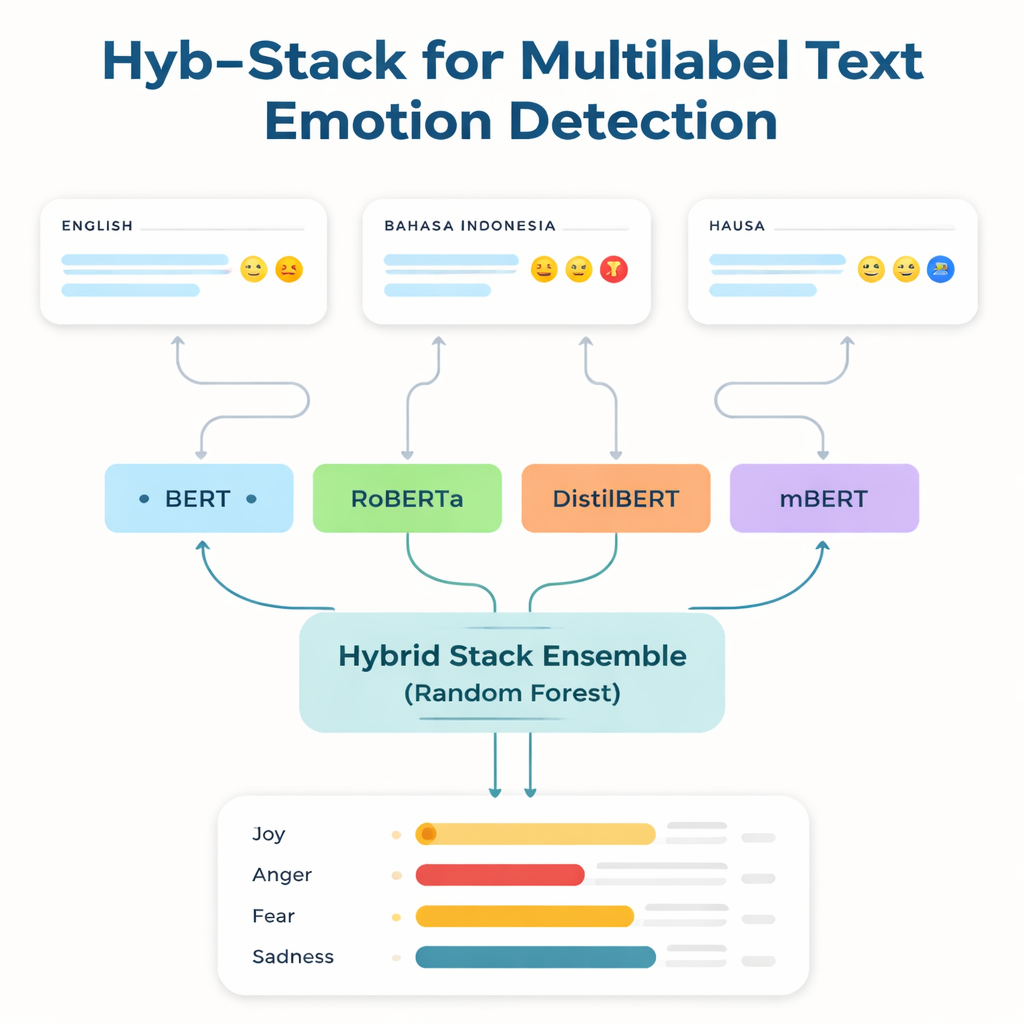
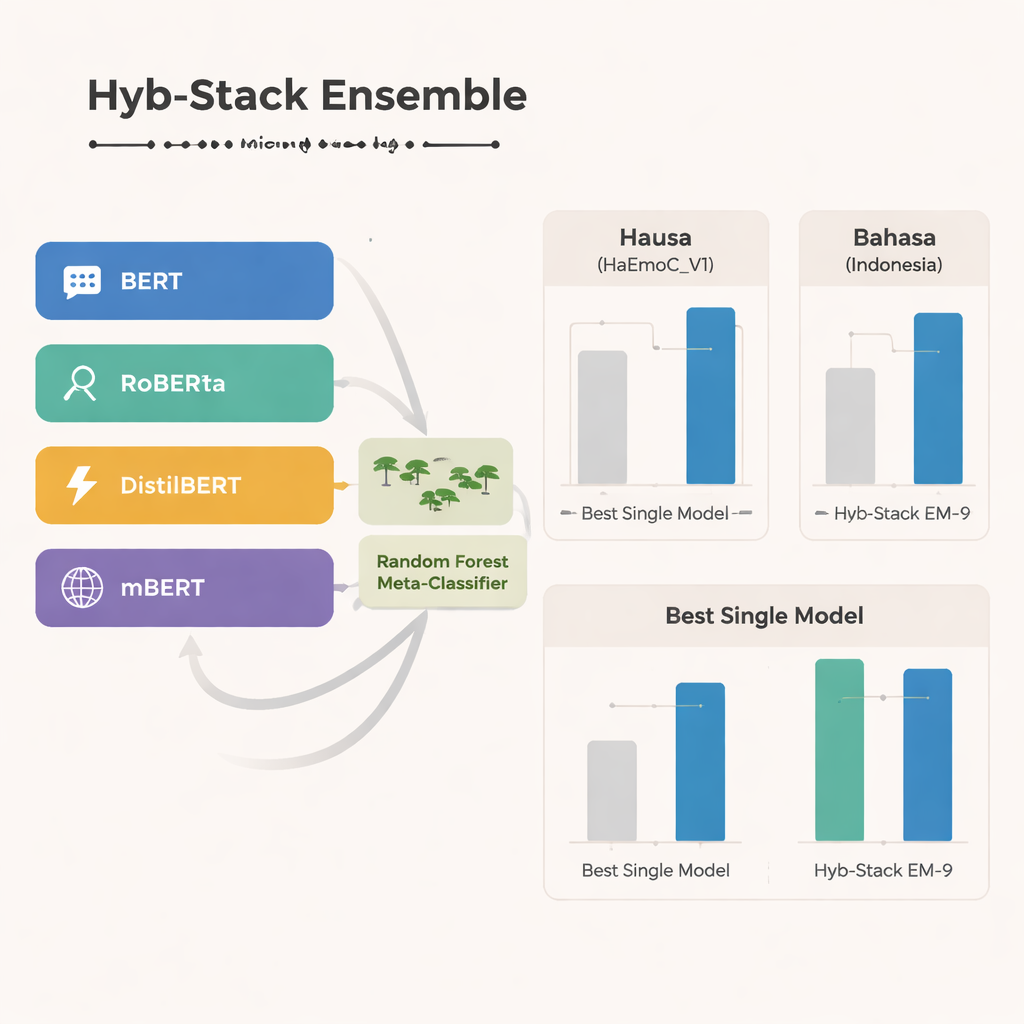
Im Kern der Studie steht Hyb-Stack, ein hybrides gestapeltes Ensemble — eine Art „Expertenkomitee“ für Sprache. Vier fortgeschrittene, auf Transformern basierende Modelle (BERT, RoBERTa, DistilBERT und das mehrsprachige mBERT) werden jeweils feinabgestimmt, um emotionale Signale im Text zu erkennen. Anstatt nur einem Modell zu vertrauen, lässt Hyb-Stack alle Vorhersagen treffen und führt deren interne Scores in eine Entscheidungsinstanz der zweiten Ebene: einen Random-Forest-Klassifikator. Dieser Meta-Klassifikator lernt, wie er die unterschiedlichen Stärken der einzelnen Modelle gewichten muss und erfasst komplexe Muster darin, wie Emotionen gemeinsam auftreten. Das Team testet zudem einfachere Ensemble-Methoden, die Vorhersagen nur mitteln, mit und ohne Gewichtung nach früherer Leistung, um zu prüfen, ob das aufwendigere Stacking sich wirklich auszahlt.
Wie gut der hybride Ansatz abschneidet
Über alle drei Sprachen hinweg sticht das mehrsprachige mBERT als das jeweils stärkste Einzelmodell hervor und erzielt besonders gute Ergebnisse beim neu erstellten Hausa-Datensatz und dem Bahasa-Indonesia-Datensatz zu Hassrede. Doch das hybride Ensemble geht noch weiter. Eine bestimmte Kombination — EM-9 genannt, die BERT, DistilBERT und mBERT innerhalb des Hyb-Stack-Frameworks vereint — liefert konsequent die besten Ergebnisse. Sie erreicht höhere F1-Werte, ein gängiges Maß für Genauigkeit, als jedes Einzelmodell oder einfache Mittelungsansätze, wobei die größten Verbesserungen in den ressourcenarmen Hausa- und Bahasa-Indonesia-Datensätzen auftreten. Detaillierte Fehleranalysen zeigen, dass verbleibende Fehler meist zwischen eng verwandten Emotionen auftreten, etwa Freude versus Überraschung oder Traurigkeit versus Angst, was die natürliche Unscharfheit menschlicher Gefühle widerspiegelt und keine klaren Systemfehler darstellt.
Was das für reale Systeme bedeutet
Für eine breite Leserschaft ist die wichtigste Erkenntnis, dass das smarte Kombinieren mehrerer KI-Modelle Computern helfen kann, Emotionen in Texten genauer zu lesen — insbesondere in Sprachen, die in der Technologie lange vernachlässigt wurden. Durch den Aufbau eines hochwertigen Hausa-Emotionskorpus und den Nachweis, dass hybride Ensembles Einzelmodelle und einfache Abstimmungsschemata übertreffen, zeigen die Autorinnen und Autoren einen praktischen Weg zu inklusiveren, emotional sensibleren Werkzeugen auf. Zukünftige Arbeiten werden den Ansatz auf subtilere emotionale Nuancen, Code-Mixing, Emojis und weitere unterrepräsentierte Sprachen ausdehnen, mit dem Ziel, Systeme zu schaffen, die nicht nur erkennen, ob Menschen glücklich oder traurig sind, sondern auch wie und warum sie sich so fühlen — unabhängig davon, welche Sprache sie sprechen.
Zitation: Adamu, H., Azmi Murad, M.A. & Nasharuddin, N.A. A hybrid stacked ensemble learning framework for multilabel text emotion detection. Sci Rep 16, 7714 (2026). https://doi.org/10.1038/s41598-026-38172-9
Schlüsselwörter: Emotionserkennung, mehrsprachiges NLP, Ensemble-Learning, Transformer-Modelle, Sprachen mit wenigen Ressourcen