Clear Sky Science · de
Effiziente Berechnung und Entwurf einer hochschnellen Doppelpräzisions-Vedic-Multiplier-Architektur
Warum schnellere Zahlberechnung wichtig ist
Jedes Mal, wenn Sie ein Video streamen, die Navigation auf Ihrem Telefon nutzen oder ein KI-System medizinische Bilder auswerten lassen, führt spezialisierte Computerhardware unauffällig Milliarden winziger Berechnungen pro Sekunde aus. Ein großer Anteil dieser Operationen sind Multiplikationen mit Gleitkommazahlen, der üblichen Darstellung reeller Werte wie 3,14159 in Computern. Dieser Artikel untersucht einen intelligenteren Weg, eine dieser Kernkomponenten zu bauen: einen hochschnellen, energieeffizienten Multiplikator, der Ideen aus der alten vedischen Mathematik nutzt, um moderne digitale Hardware zu verbessern.
Von alten Rechentricks zu modernen Chips
Gleitkommaarithmetik bildet die Grundlage für digitale Signalverarbeitung, Bildverarbeitung, Kommunikation und Beschleuniger für Deep Learning. Standardmultiplikatoren müssen breite Binärwörter verarbeiten — 64 Bit für Doppelpräzision — und dies schnell tun, ohne wertvollen Chip-Flächen- oder Energieaufwand zu verursachen. Traditionelle Ansätze wie Booth-, Karatsuba- und Array-Multiplizierer balancieren Kompromisse zwischen Geschwindigkeit, Hardwaregröße und Designkomplexität. Die vedische Mathematik, ein System von 16 klassischen Rechenregeln, das in Indien entwickelt wurde, enthält eine Multiplikationsmethode namens Urdhva Tiryakbhyam, „vertikal und kreuzweise“. Sie erzeugt Partialprodukte in sehr paralleler Weise, was die Anzahl der Zwischenschritte und die benötigte Hardware reduzieren kann. Forscher haben diese Ideen kürzlich auf digitale Schaltungen übertragen, doch bestehende Entwürfe bringen bei Doppelpräzisions-Gleitkommaoperationen weiterhin Overheads mit sich.
Was an diesem neuen Multiplikator besonders ist
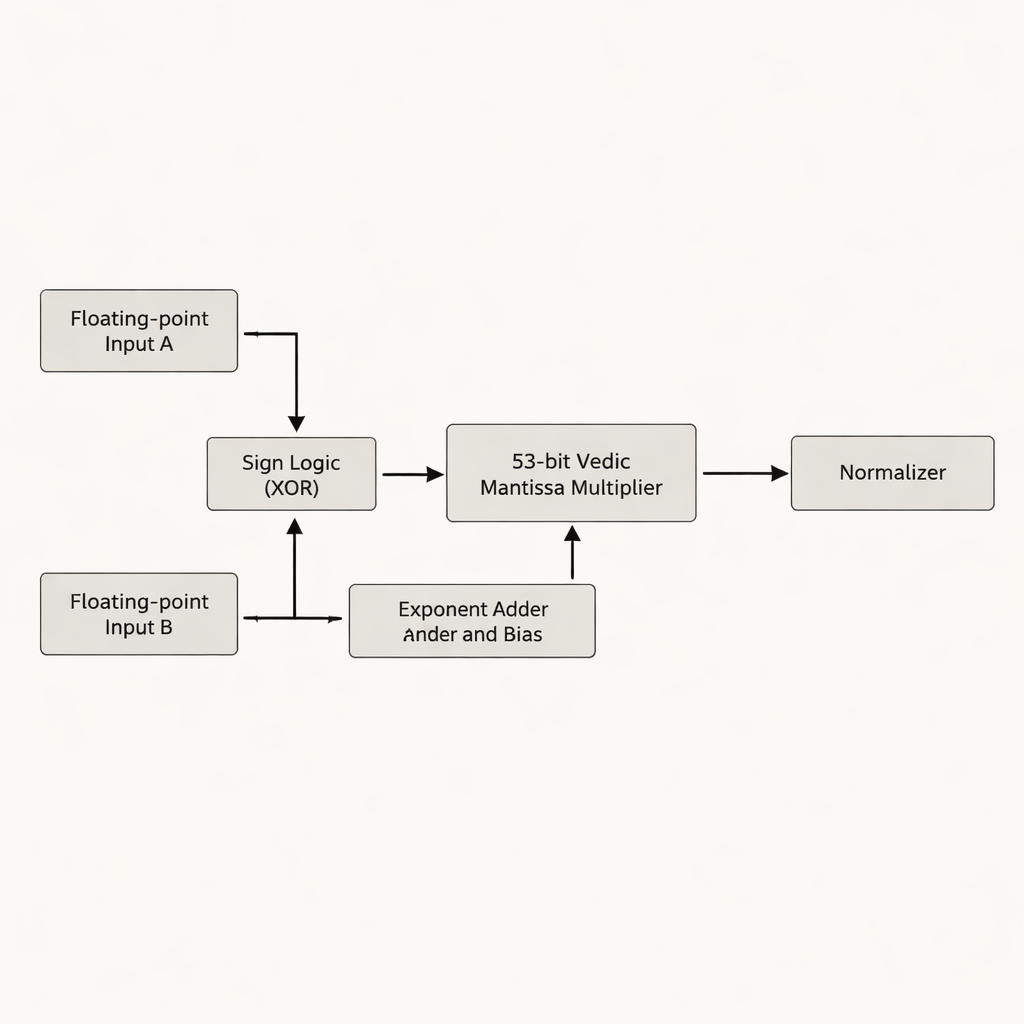
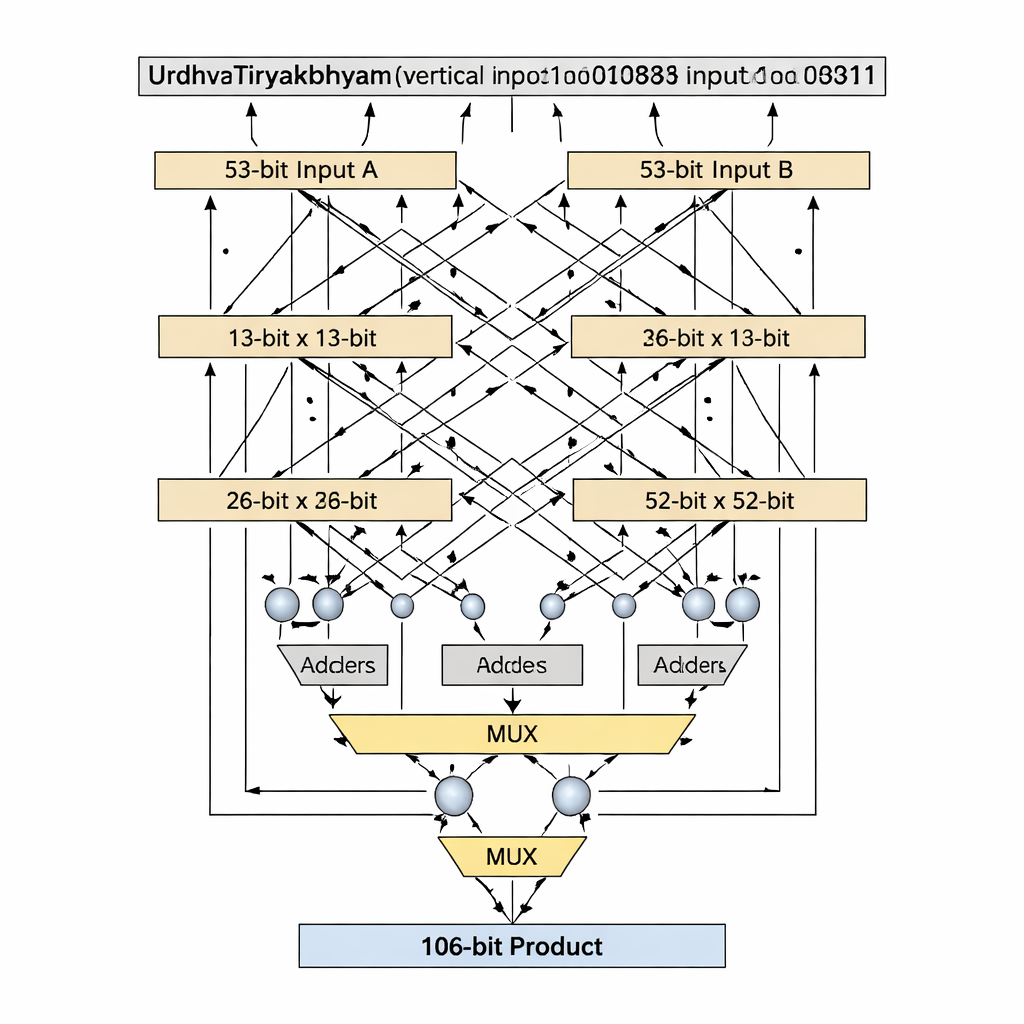
Die Autoren schlagen einen Doppelpräzisions-Gleitkomma-Multiplikator vor, der den Mantissenanteil — den Teil einer Gleitkommazahl, der die signifikanten Ziffern trägt — in den Mittelpunkt stellt. Statt die 52‑Bit-Mantisse wie viele frühere Entwürfe auf 54 Bit aufzufüllen, arbeiten sie mit der tatsächlichen, effektiven 53‑Bit-Mantisse und vermeiden so verschwendete „weiße“ Bits, die auf dem Chip zusätzlichen Speicher und Verdrahtung beanspruchen. Das Herzstück des Entwurfs ist ein 53‑Bit-Vedic-Multiplizierer auf Basis von Urdhva Tiryakbhyam, angeordnet in einer Hierarchie kleinerer Bausteine: 3‑Bit-Einheiten bilden 6‑Bit‑Einheiten, daraus werden 12‑, 13‑, 26‑ und 52‑Bit‑Einheiten, die schließlich zur finalen 53‑Bit‑Stufe kombiniert werden. Die Architektur trennt die Arbeit in drei Hauptphasen — Vorzeichenberechnung, Exponentenaddition und Biasing sowie Mantissenmultiplikation gefolgt von Normalisierung — und entspricht damit dem IEEE‑754‑Gleitkommastandard, während redundante Schaltungsteile reduziert werden.
Primzahlgroße Bausteine für sauberere Hardware
Eine wichtige Innovation ist, wie der Entwurf mit Bitbreiten umgeht, die Primzahlen sind, etwa 13 und 53, die sich nicht sauber in gleich große Blöcke teilen lassen. Standard-Vedic-Zerlegungen setzen gleichmäßige Aufteilungen voraus, was bei Primlängen unpraktisch oder verschwenderisch wird. Die Autoren führen einen „Prime‑Bit“-Algorithmus ein, der geschickt einen kleineren (n−1)-Bit‑Vedic‑Multiplizierer plus Addierer, Multiplexer und ein einzelnes zusätzliches Logikgatter wiederverwendet, um einen n‑Bit‑Multiplikator ohne Padding zu emulieren. Für die 13‑Bit‑Stufe werden die Eingänge in 1‑Bit‑ und 12‑Bit‑Abschnitte geteilt; Partialprodukte werden mit einem 12‑Bit‑Vedic‑Multiplizierer erzeugt und per bedingter Auswahl (über Multiplexer) basierend auf den höchstwertigen Bits kombiniert, ergänzt durch eine kleine Anzahl von Addierern. Dasselbe Muster skaliert bis zu 53 Bit mit einem 52‑Bit‑Kern. Diese maßgeschneiderte Zerlegung verkürzt den kritischen Pfad — die längste Logikkette, die ein Signal durchlaufen muss — und hält gleichzeitig die Anzahl der Logikelemente gering.
Gemessene Gewinne bei Geschwindigkeit, Größe und Energie
Der Entwurf wurde in der Hardwarebeschreibungssprache Verilog beschrieben und auf einem Xilinx Zynq-FPGA mit Vivado‑Tools implementiert. Über 13‑, 26‑, 52‑, 53‑ und 64‑Bit‑Vedic‑Multiplizierer hinweg zeigt die vorgeschlagene 53‑Bit‑Einheit ein günstiges Verhältnis von Verzögerung, Logikaufwand (Lookup‑Tables und I/O‑Pins) und geschätztem Leistungsbedarf. Im Vergleich zu früheren Doppelpräzisions‑Multiplikatoren auf Basis von Booth, Karatsuba und anderen Vedic‑Anordnungen reduziert die neue Architektur signifikant die Worst‑Case‑Verzögerung und den Bedarf an FPGA‑Ressourcen, ohne die umgebende Gleitkomma‑Elektronik zu verkomplizieren. Da die Mantissenmultiplikation schneller ist und die Logiktiefe geringer ausfällt, verringert sich die Schaltaktivität, was auf ein besseres Power‑Delay‑Produkt hindeutet, obwohl direkte Technologie‑übergreifende Leistungsvergleiche schwer zu ziehen sind.
Auswirkungen auf KI und Signalverarbeitung
Um den Entwurf in einer realen Arbeitslast zu testen, integrierten die Autoren ihren vedischen Doppelpräzisions‑Multiplikator in die Faltungs‑Engine eines Convolutional Neural Network, wo Multiply‑and‑Accumulate‑Operationen die Laufzeit dominieren. Der Ersatz konventioneller IEEE‑754‑ und früherer Vedic‑Multiplikatoren durch das neue Design verkürzte die Faltungsverzögerung, senkte den Energieverbrauch und reduzierte die Inferenzzeit, bei gleichbleibender Klassifikationsgenauigkeit. Ähnliche Vorteile werden auch bei anderen rechenintensiven Aufgaben erwartet, etwa in digitaler Filterung, Kantenerkennung und medizinischer Bildverarbeitung, wo schnellere Multiplikatoren die Durchsatzrate direkt erhöhen und Geräten ermöglichen können, kühler zu laufen oder mit kleineren Batterien auszukommen.
Was das für die Alltagstechnik bedeutet
Einfach gesagt zeigt die Arbeit, dass das Übernehmen einer cleveren Multiplikationsidee aus der vedischen Mathematik und ihre sorgfältige Anpassung an moderne Binärformate einen Multiplikator ergeben kann, der kleiner, schneller und energieeffizienter ist als Standardentwürfe. Dieser verbesserte Baustein lässt sich in Prozessoren, Signalverarbeitungs‑Chips und KI‑Beschleunigern einsetzen, was zu schnellerer Datenanalyse, reaktionsfähigeren Geräten und potenziell geringerem Energieverbrauch in Systemen von Smartphones bis zu medizinischen Scannern führt. Die Autoren skizzieren auch zukünftige Richtungen, darunter reversible Logik für noch niedrigeren Energieverbrauch und Integration in größere Verarbeitungseinheiten, und deuten an, dass diese Verbindung von alter Arithmetik und moderner Hardware erst am Anfang steht.
Zitation: Kumar, A.S., Sahitya, G., Kusuma, R. et al. Efficient computation and design of high speed double precision Vedic multiplier architecture. Sci Rep 16, 7364 (2026). https://doi.org/10.1038/s41598-026-38147-w
Schlüsselwörter: Vedic-Multiplier, Gleitkommaarithmetik, FPGA-Design, digitale Signalverarbeitung, konvolutionale neuronale Netze