Clear Sky Science · de
Anwendung schwarmbasierter tiefer neuronaler Netze und Ensemble‑Modelle zur Rekonstruktion von spezifischer Leitfähigkeitsdaten
Warum das Auffüllen von Datenlücken wichtig ist
Küstengewässer sind die erste Front, an der menschliche Aktivitäten auf das Meer treffen. Wissenschaftlerinnen und Wissenschaftler beobachten die Salinität dieser Gewässer mit einer Messgröße namens spezifische Leitfähigkeit, die hilft, Leckagen von Verschmutzungen, Veränderungen im Süßwasserzufluss und langfristige Umweltveränderungen zu erkennen. Doch Sensoren fallen aus, Stürme unterbrechen die Stromversorgung und Messgeräte haben Grenzen. Das Ergebnis sind frustrierende Lücken in wichtigen Aufzeichnungen — ausgerechnet dann, wenn Verantwortliche und Forschende kontinuierliche Daten am dringendsten brauchen. Diese Studie stellt eine praktische Frage: Kann moderne Künstliche Intelligenz solche beschädigten Aufzeichnungen zuverlässig „reparieren“, sodass Entscheidungen an der Küste auf vollständigen, vertrauenswürdigen Informationen beruhen?
Dem Atem des Golfs zuschauen
Die Forschenden konzentrierten sich auf den Golf von Mexiko, eines der größten marinen Ökosysteme der Welt und eine Region unter erheblichem Industrie‑ und Landwirtschaftsdruck. Sie nutzten Messungen von fünf Stationen des US Geological Survey in der Nähe des Pascagoula River und des Mullet Lake, die jeweils alle 15 Minuten Salzgehalt (über spezifische Leitfähigkeit), Temperatur und Wasserstand aufzeichneten. Eine Station, bezeichnet als E, wies etwa 5 % fehlender spezifischer Leitfähigkeitsdaten auf — genau die Art von Problem, die reale Überwachungsnetze konfrontiert. Die Daten der vier benachbarten Stationen bildeten eine Art Umweltsicherheitsnetz: Selbst wenn Station E ausfiel, behielten die anderen die Beobachtung bei. Die zentrale Idee war, Computer‑Modelle so zu trainieren, dass sie lernen, wie alle fünf Stationen gemeinsam „atmen“, sodass Lücken an einer Stelle aus den vollständigen Aufzeichnungen der anderen geschlossen werden können.
Intelligente Algorithmen auf dem Prüfstand
Um das Problem anzugehen, stellten die Autorinnen und Autoren zehn verschiedene Modellierungsansätze gegenüber. Am einen Ende standen bekannte Werkzeuge wie multiple lineare Regression, die versuchen, Eingaben und Ausgaben durch Geradenbeziehungen zu verbinden. In der Mitte lagen flexiblere Modelle wie klassische neuronale Netze, Fuzzy‑Logik‑Systeme und ein spezielles Long Short‑Term Memory (LSTM)‑Netz, das häufig für Zeitreihendaten verwendet wird. Sie nutzten auch ein selbstorganisierendes Verfahren namens Group Method of Data Handling (GMDH) und eine nichtlineare Variante (NGMDH), die eigenständig mehrlagige Formeln aufbauen kann. Schließlich setzten sie baumbasierte Methoden ein: ein einzelnes Entscheidungsbaum‑Modell (CART) und zwei Ensemble‑Ansätze — Random Forest und XGBoost — die viele Bäume kombinieren, um eine finale Entscheidung zu treffen, ähnlich einem Gremium von Expertinnen und Experten, die über eine Antwort abstimmen.
Schwarmgestütztes Deep Learning
Das Training tiefer neuronaler Netze ist berüchtigt schwierig: Ihre vielen Stellschrauben können leicht in suboptimalen Konfigurationen festhängen. Um das zu verbessern, kombinierten die Autorinnen und Autoren LSTM und NGMDH mit einer neueren Optimierungsmethode, die vom Wirbeln von Wasser inspiriert ist, genannt turbulent flow of water‑based optimization (TFWO). In diesem Ansatz wird jede mögliche Einstellung von Modellparametern als „Partikel“ vorgestellt, das sich in einem wirbelnden Muster durch den Lösungsraum bewegt. Über viele Zyklen werden die Partikel in Richtung Regionen gelenkt, die geringere Vorhersagefehler liefern. Diese schwarmartige Suche machte beide neuronalen Netztypen spürbar genauer als ihre Standardversionen und verringerte deren mittlere Fehler um etwa 6–11 Prozent. Dennoch wurden selbst diese verbesserten Deep‑Modelle letztlich von den baumbasierten Ansätzen übertroffen.
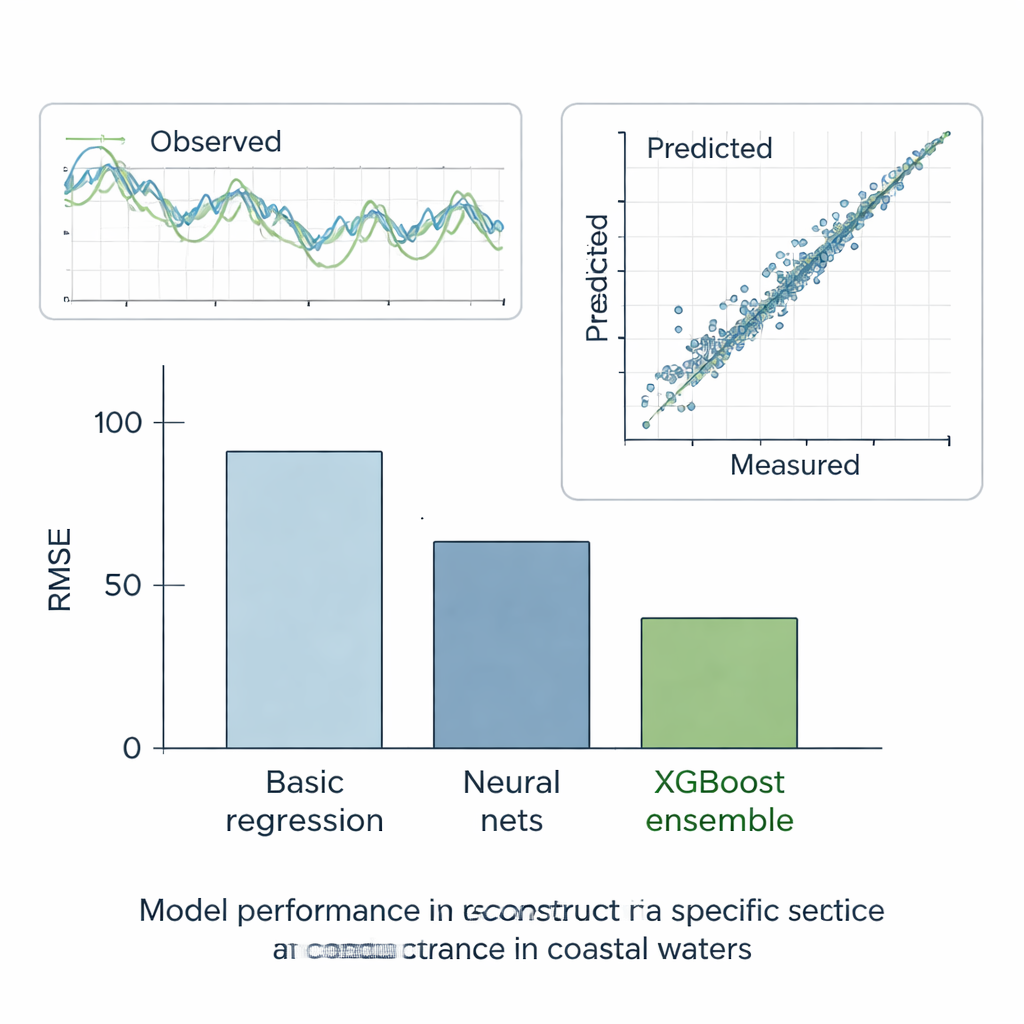
Ensembles übernehmen die Führung
Die Autorinnen und Autoren testeten alle Methoden rigoros in sechs Szenarien. In fünf „Was‑wenn“Fällen versteckten sie Teile ansonsten vollständiger Aufzeichnungen und prüften, wie gut jedes Modell die fehlenden Werte rekonstruieren konnte. Im letzten, realen Fall baten sie die Modelle, die tatsächlichen Lücken an Station E mit Hilfe der Daten der Nachbarstationen zu füllen. Über diese Tests hinweg schnitt die einfachste Geradenmethode am schlechtesten ab, während standardmäßige Machine‑Learning‑Modelle deutlich besser waren und den Fehler in etwa halbierten. Entscheidungsbäume, die Daten automatisch in homogenere Gruppen aufteilen, verbesserten die Ergebnisse weiter. Aber der klare Sieger war das XGBoost‑Ensemble: Indem es Hunderte von Bäumen aufbaute, von denen jeder die Fehler der Vorgänger korrigiert, erzielte es extrem niedrige Fehler und eine nahezu perfekte Übereinstimmung zwischen vorhergesagter und gemessener spezifischer Leitfähigkeit. Seine Rekonstruktionen folgten den beobachteten Zeitreihen eng und reproduzierten das generelle statistische Verhalten der Wasserqualitätsaufzeichnungen.
Was das für Küsten und darüber hinaus bedeutet
Für Nicht‑Spezialistinnen und -Spezialisten ist die Kernaussage klar: Sorgfältig gestaltete KI kann fehlende Teile von Küsten‑Wasserqualitätsaufzeichnungen zuverlässig auffüllen, besonders wenn benachbarte Stationen Kontext liefern. Während fortgeschrittene neuronale Netze leistungsfähig sind, zeigt diese Studie, dass baumbasierte Ensemble‑Methoden wie XGBoost noch genauer sind und in der Praxis die beste Wahl zur Reparatur umweltbezogener Datensätze sein können. Mit robusten Lückenschluss‑Werkzeugen können Forschende subtile Veränderungen der Küstensalinität besser verfolgen, Verschmutzungsereignisse identifizieren und Managemententscheidungen unterstützen, ohne von unvermeidlichen Sensorstörungen ausgebremst zu werden. Dieselben Strategien lassen sich auf viele weitere ingenieur‑ und umweltbezogene Probleme übertragen, in denen Datenströme reichhaltig, verrauscht und gelegentlich unvollständig sind.
Zitation: Mahdavi-Meymand, A., Sulisz, W. & Nandan Bora, S. Application of swarm-based deep neural networks and ensemble models for reconstruction of specific conductance data. Sci Rep 16, 7292 (2026). https://doi.org/10.1038/s41598-026-38136-z
Schlüsselwörter: Wasserqualität an Küsten, spezifische Leitfähigkeit, maschinelles Lernen, Rekonstruktion fehlender Daten, XGBoost