Clear Sky Science · de
UncerTrans: unsicherheitsbewusster zeitlicher Transformer zur frühen Handlungsvorhersage
Warum frühes Erkennen von Handlungen uns schützen kann
Stellen Sie sich einen Haushaltsroboter vor, der allein am ersten Handgelenkszucken erkennen kann, ob jemand gerade dabei ist, heißes Wasser sicher in eine Tasse zu gießen oder versehentlich den Wasserkocher umzuwerfen. In Fabriken, Krankenhäusern und Smart Homes teilen Maschinen zunehmend den Raum mit Menschen, und erst zu reagieren, wenn ein Unfall begonnen hat, ist zu spät. Dieses Papier stellt UncerTrans vor, ein neues KI-System, das nicht nur vorhersagt, was eine Person auf Basis des sehr frühen Verlaufs einer Handlung wahrscheinlich tun wird, sondern auch angibt, wie sicher es sich bei dieser Einschätzung ist — eine Fähigkeit, die entscheidend ist, wenn es um menschliche Sicherheit geht.
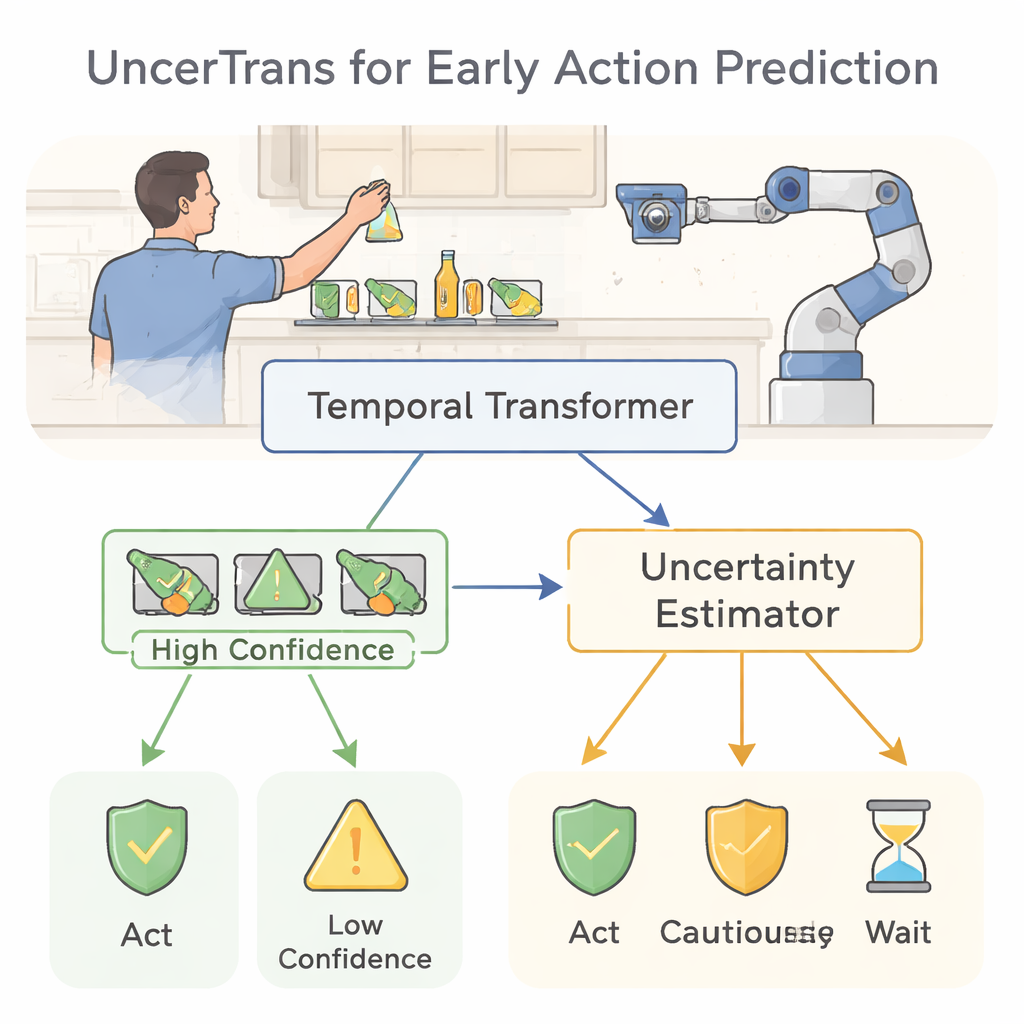
Vom Beobachten zum Vorhersagen menschlicher Handlungen
Die meisten aktuellen Computer-Vision-Systeme erkennen, was jemand tut, erst wenn die Handlung nahezu abgeschlossen ist: Sie klassifizieren einen vollständigen Videoclip als „Gemüse schneiden“ oder „eine Tasse aufheben“. Das ist für spätere Analysen nützlich, aber nicht, um Verbrennungen, Kollisionen oder Stürze zu verhindern. Frühe Handlungsvorhersage löst ein schwierigeres Problem: Sie muss entscheiden, welche vollständige Handlung folgen wird, nachdem sie nur 10–20 % davon gesehen hat. Die Schwierigkeit besteht darin, dass sich viele Handlungen am Anfang ähnlich sehen — auf eine Kanne zu greifen kann bedeuten, ein Getränk einzuschenken oder sie umzustoßen — daher muss ein System mit wenigen Informationen arbeiten und dennoch gefährliche Fehlentscheidungen vermeiden.
Der Maschine beibringen, sich auf die richtigen Momente zu konzentrieren
UncerTrans geht das Problem mit einem zeitlichen Transformer an, einer modernen neuronalen Netzwerkarchitektur, die ursprünglich für Sprache entwickelt wurde. Statt Wörter in einem Satz zu lesen, betrachtet sie kurze Videosequenzen über die Zeit. Das Modell teilt eine frühe Handlungssequenz in einige wenige Segmente und nutzt einen Aufmerksamkeitsmechanismus, um zu bestimmen, welche Momente am wichtigsten sind. Jüngeren Frames wird dabei zusätzliches Gewicht eingeräumt, was unserer Intuition entspricht, dass die jüngste Bewegung meist die klarste Absicht zeigt. Dieses Design ermöglicht es dem System, sowohl feine Details wie Fingerbewegungen als auch größere Muster wie die Bahn des Arms zu erfassen, selbst wenn nur ein Bruchteil der vollständigen Handlung sichtbar ist.
Der Maschine beibringen, zuzugeben, wenn sie unsicher ist
Eine Schlüsselinnovation von UncerTrans ist, dass es nicht bei einer einzigen harten Antwort bleibt. Stattdessen wird derselbe Input mehrfach leicht unterschiedlich durch das Netzwerk geschickt, mithilfe einer Technik namens Monte-Carlo-Dropout. Bei jedem Durchlauf werden unterschiedlich interne Verbindungen zufällig deaktiviert, was zu leicht unterschiedlichen Vorhersagen führt. Indem das System betrachtet, wie stark diese Vorhersagen auseinandergehen, kann es seine eigene Unsicherheit abschätzen: eng beieinanderliegende Vorhersagen signalisieren hohe Sicherheit, während verstreute Vorhersagen Zweifel anzeigen. UncerTrans trennt zudem Unsicherheit, die durch begrenzte Trainingserfahrung entsteht, von Störungen im Video selbst und passt die Anzahl der Testdurchläufe dynamisch an — es verwendet mehr Durchläufe, wenn die ersten Proben uneindeutig wirken, und weniger, wenn sie bereits übereinstimmen.
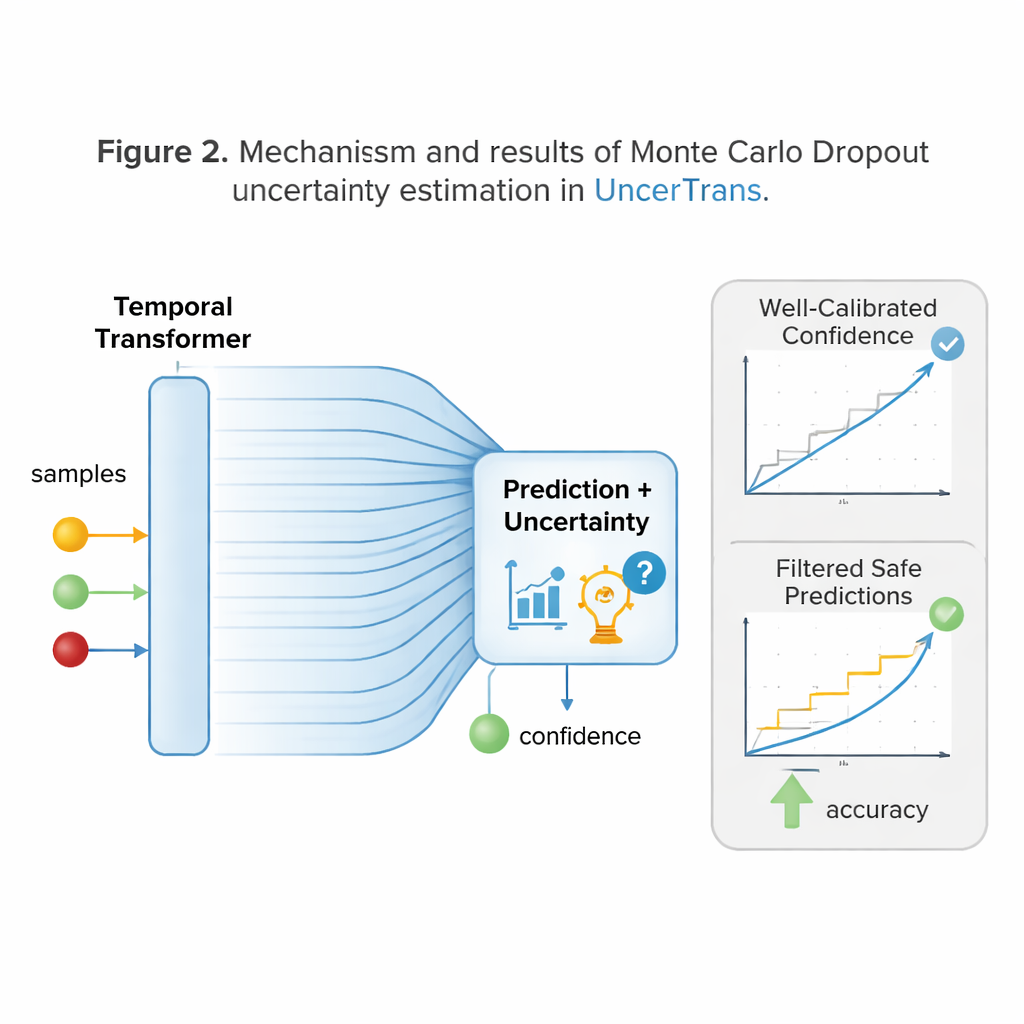
Vertrauen in sichereres Verhalten ummünzen
Zu wissen, wann man falsch liegen könnte, ist nur nützlich, wenn es das Verhalten ändert. UncerTrans wandelt seine Zuverlässigkeitsschätzungen in praktische Entscheidungen um. Bei Vorhersagen mit geringer Unsicherheit kann das System entschlossen handeln — etwa eine Warnung auslösen oder einen Roboterarm aus der Gefahrenzone bewegen. Bei moderater Unsicherheit kann es konservativere Verhaltensweisen wählen, wie das Abbremsen eines Roboters oder das Einholen weiterer Informationen. Ist die Unsicherheit sehr hoch, kann es sich weigern, eine Entscheidung zu treffen, und einfach weiter beobachten. Tests an einem großen First-Person-Küchendatensatz zeigen, dass UncerTrans kommende Handlungen genauer vorhersagt als mehrere starke Alternativen, besonders wenn nur die ersten 10 % einer Handlung sichtbar sind. Bemerkenswert ist, dass bei Ausschluss der 30 % der unsichersten Fälle die Genauigkeit der verbleibenden Vorhersagen auf etwa 84 % steigt — ein klarer Beleg für den Wert unsicherheitsbewusster Filterung.
Was das für die tägliche Mensch–Roboter-Zusammenarbeit bedeutet
Für Nicht-Fachleute ist die Botschaft einfach: UncerTrans ist ein Schritt hin zu Maschinen, die aus wenigen Hinweisen unsere nächste Bewegung erraten und zugleich einschätzen können, wann diese Vorhersagen vertrauenswürdig sind. Durch die Kombination eines zeitlich empfindlichen Visionsmodells mit einem internen „Vertrauensmesser“ kann das System in unübersichtlichen, realen Umgebungen wie Küchen, Fabriken und Pflegeeinrichtungen schneller und sicherer reagieren. Zwar verursacht die Methode weiterhin Rechenaufwand und bedarf weiterer Verfeinerung, doch sie liefert ein vielversprechendes Konzept für künftige Roboter und Überwachungssysteme, die Gefahren frühzeitig antizipieren, bei Unsicherheit vorsichtig reagieren und sich so sicherer in menschliche Räume einfügen.
Zitation: Zhai, X., Liu, Y. UncerTrans: uncertainty-aware temporal transformer for early action prediction. Sci Rep 16, 7068 (2026). https://doi.org/10.1038/s41598-026-38107-4
Schlüsselwörter: frühe Handlungsvorhersage, Mensch-Roboter-Zusammenarbeit, Unsicherheit in der KI, Transformer-Modelle für Vision, sichere intelligente Systeme