Clear Sky Science · de
YOLC mit dynamischer sparsamer Aufmerksamkeit zur Erkennung schneller kleiner Ziele in tragbaren Sportbildern
Sport durch die Augen des Spielers sehen
Stellen Sie sich vor, Sie verfolgen einen Tennisaufschlag oder eine Tischtennis-Rallye nicht von den Tribünen, sondern durch eine Kamera, die am Kopf eines Athleten befestigt ist. Der Ball rast als winziger Wischer durchs Blickfeld, doch Trainer und Analysten möchten genau wissen, wo er hinging, wie schnell er war und wie die Spieler reagierten. Dieses Papier stellt ein neues Computer-Vision-System namens YOLC vor, das dafür entwickelt wurde, diese schnellen, kleinen Objekte in Echtzeit auf winzigen, energieeffizienten Wearables zu erkennen und zu verfolgen.
Warum winzige, schnelle Ziele so schwer zu fassen sind
Wearable-Kameras sind im Sporttraining verbreitet und liefern Ich-Perspektiven von Spielen und Übungen. Aus dieser Sicht nehmen entscheidende Objekte – ein Federball, ein Tennisball, der Startfuß eines Sprinters – oft nur wenige Pixel ein und bewegen sich zwischen Frames sehr schnell. Bestehende Erkennungssysteme sind entweder zu rechenintensiv für stromsparende Geräte oder verlieren die Spur, wenn Objekte klein, verschwommen oder weit entfernt sind. Die Autor:innen zeigen, dass in realem Sportmaterial viele Ziele kleiner als 32×32 Pixel sind und sich so schnell zwischen Frames bewegen, dass Standardmethoden sie übersehen oder ihre Identität wiederholt verlieren, wodurch Trajektorien abbrechen und aussagekräftige Leistungsanalysen unmöglich werden.
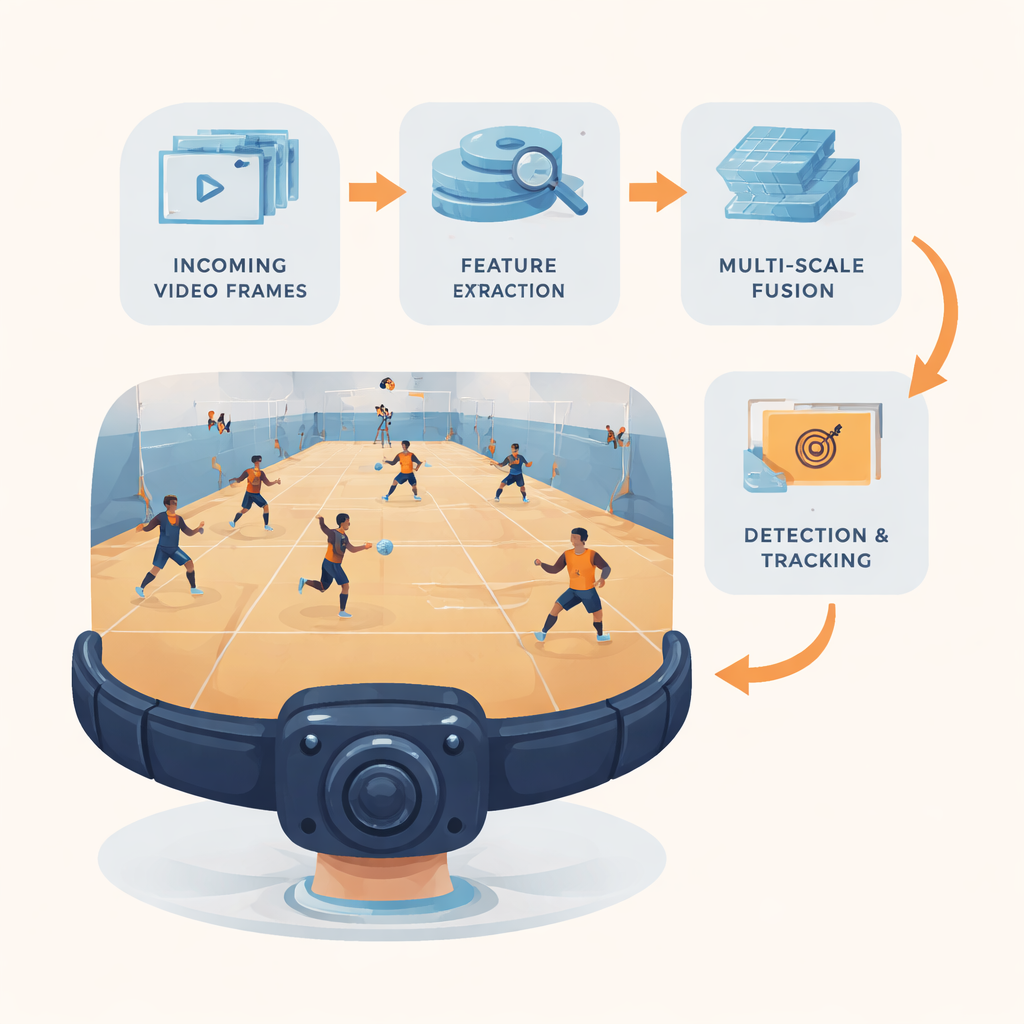
Eine leichte Vision-Pipeline für tragbare Kameras
Die Forschenden stellen YOLC (Kurzform für „You Only Look Clusters“) vor, eine komplette Erkennungs‑ und Tracking-Pipeline, zugeschnitten auf Edge-Hardware wie ein NVIDIA Jetson Nano. Im Kern steht ein schlanker Feature‑Extraktor aus einer effizienten Netzwerkfamilie namens MobileNet, umgebaut, um überwiegend „günstige“ Operationen zu verwenden, die sowohl Speicher als auch Rechenaufwand verringern und dennoch genug Details erhalten, um winzige Objekte zu sehen. Videoframes werden auf eine ausgewogene Auflösung skaliert, und es entstehen drei Ebenen von Merkmalskarten: eine mit feinen Details für sehr kleine Ziele, eine für mittelgroße Objekte und eine mit stärkeren semantischen Informationen für große oder entfernte Objekte. Diese Multi‑Scale-Karten speisen den Rest des Systems, das sorgfältig darauf ausgelegt ist, aus jeder Rechnung so viel Information wie möglich herauszuholen.
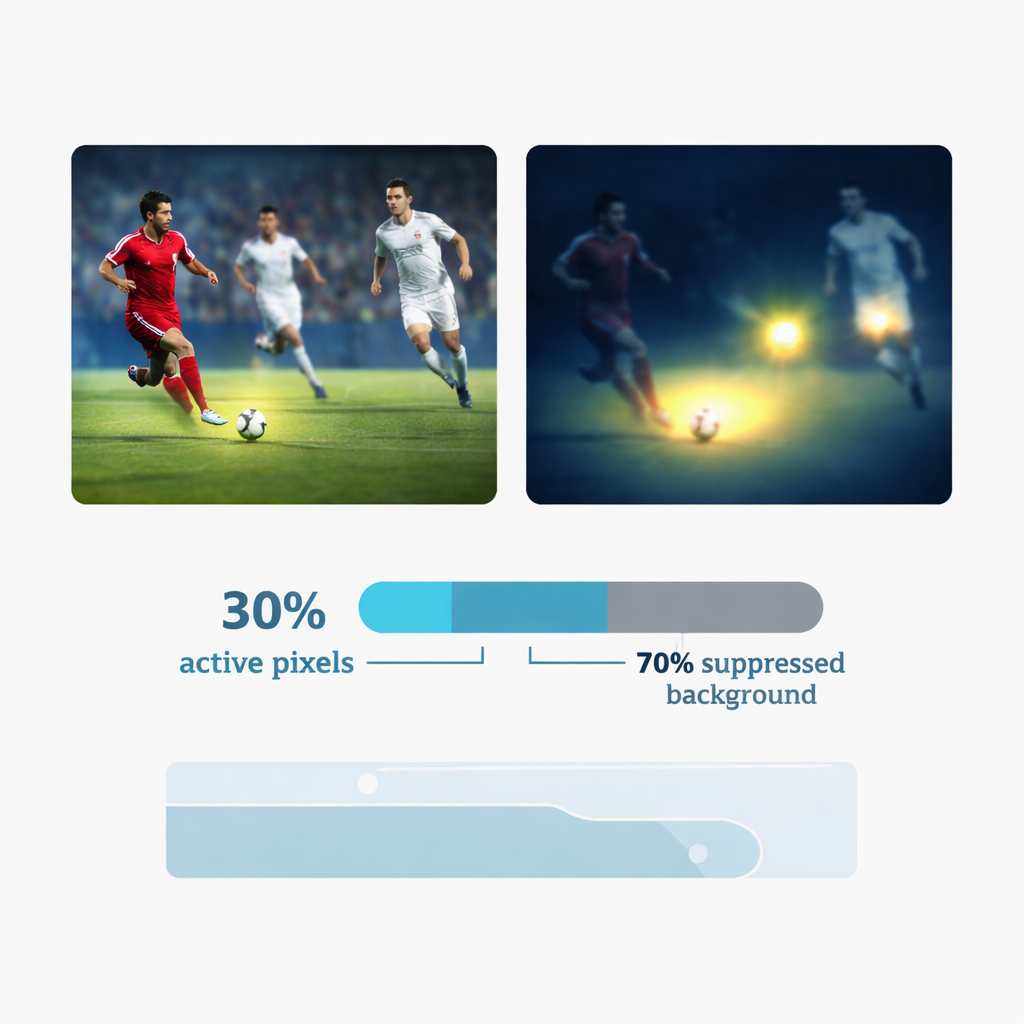
Das Netz nur dort schauen lassen, wo es zählt
Eine zentrale Innovation ist ein Mechanismus der „dynamischen sparsamen Aufmerksamkeit“, der nachahmt, wie ein Mensch nur die informativsten Bereiche einer Szene anschauen würde. Statt jeden Pixel gleich zu verarbeiten, misst YOLC, wie stark sich das Bild lokal ändert – etwa an Kanten, Ecken oder der Kontur eines sich bewegenden Balls – und erstellt eine Karte der texturreichsten Stellen. Anschließend behält es nur etwa die oberen 30 Prozent dieser hochreaktiven Positionen für die weitere Verarbeitung und schaltet damit Rauschhintergründe wie Wände, Tribünen oder Himmel effektiv aus. Ein spezieller Trainingstrick stellt sicher, dass das Modell trotz dieses harten Abschneidens vollständig trainierbar bleibt. Diese selektive Fokussierung verbessert nicht nur die Genauigkeit durch Ausblendung von Ablenkungen, sie reduziert auch erheblich die benötigte Rechenarbeit – ein entscheidender Vorteil auf batteriebetriebenen Wearables.
Von scharfen Merkmalen zu stabilen Bahnen
Nach der Fokussierung auf Schlüsselregionen kombiniert YOLC Informationen über die Skalen hinweg mithilfe einer bidirektionalen Feature‑Pyramide, die Signale sowohl von grob nach fein als auch von fein nach grob weitergibt. Die Stärke dieser Verbindungen wird von derselben Aufmerksamkeitskarte gesteuert, sodass wichtige kleine Objekte in jeder Stufe verstärkt werden. Im letzten Erkennungsschritt hilft eine zusätzliche „Koordinatenaufmerksamkeit“-Einheit dem System, besser zu verstehen, wo sich Objekte im Bild befinden, indem Signale entlang horizontaler und vertikaler Richtungen verknüpft werden. Um Frame‑für‑Frame-Detektionen in glatte Zeitbahnen zu verwandeln, ergänzt die Methode ein leichtes optisches Flussmodul – ein Werkzeug zur Schätzung der Pixelbewegung zwischen aufeinanderfolgenden Frames – sowie ein zweistufiges Matching‑Schema, das zunächst hochkonfidente Detektionen mit bestehenden Tracks paarweise verknüpft und anschließend vorsichtig niedrigere Konfidenz‑Boxen wiederverwendet, die der erwarteten Bewegung entsprechen. Zusammengenommen reduzieren diese Bausteine Identitätswechsel und Lücken, selbst wenn Objekte sich kreuzen oder kurzzeitig verdeckt sind.
Leistung in der realen Welt
Das Team testete YOLC auf einem maßgeschneiderten Sport‑Datensatz mit Badminton, Basketball, Tennis, Sprint und Tischtennis, aufgenommen mit einer Kopf‑montierten Kamera in realen Trainingsumgebungen. Auf diesem herausfordernden Material läuft das System mit 53,5 Bildern pro Sekunde und nur 1,78 Millionen Parametern – deutlich weniger als viele verbreitete Objektdetektoren. Es erreicht einen Erkennungswert (mAP@0.5) von 75,3 Prozent und eine Rückruffrate für kleine Objekte von über 80 Prozent und übertrifft damit mehrere bekannte leichte Modelle. In Tracking‑Benchmarks hält YOLC längere, zuverlässigere Trajektorien und reduziert Identitätswechsel drastisch. Es erweist sich zudem als robust gegenüber Bewegungsunschärfe und Kamerawackeln und halbiert grob die Fehlalarmrate im Vergleich zu konkurrierenden Methoden.
Was das für den Sport und darüber hinaus bedeutet
Für Trainer, Analysten und Hersteller ist die Botschaft klar: Eine präzise, Echtzeit‑Erfassung schneller Sportaktionen muss nicht von sperrigen Servern oder makellosem TV‑Material abhängen. Indem es gezielt entscheidet, wo und wann Rechenleistung eingesetzt wird, verwandelt YOLC rauschige Ich‑Perspektiven von Wearables in detaillierte Aufzeichnungen darüber, wie kleine, schnelle Objekte sich bewegen und mit Athlet:innen interagieren. Das ermöglicht reichhaltigeres Feedback im Training, sichereres Monitoring bei intensiven Sportarten und allgemein intelligentere Vision‑Systeme auf jedem kleinen Gerät, das unter engen Hardware‑Beschränkungen klar sehen muss.
Zitation: Chen, H., Song, Y., Liu, W. et al. YOLC with dynamic sparse attention for high-speed small target detection in wearable sports images. Sci Rep 16, 6858 (2026). https://doi.org/10.1038/s41598-026-38079-5
Schlüsselwörter: tragbare Sport-Vision, Erkennung kleiner Objekte, Echtzeit-Tracking, Edge-AI, Aufmerksamkeitsmechanismen