Clear Sky Science · de
Der Aufbau und verfeinerte Extraktionstechniken von Wissensgraphen basierend auf großen Sprachmodellen
Schlauere Karten für komplexe Entscheidungen
Moderne Entscheidungen in Bereichen mit hohen Einsätzen — etwa groß angelegte Operationen, Infrastrukturmanagement oder Katastrophenhilfe — hängen davon ab, sehr schnell große Mengen verstreuter Informationen zu überblicken. Handbücher, Sensordaten, Berichte und Simulationen erzählen jeweils einen Teil der Geschichte, sind aber selten so organisiert, dass Menschen oder Computer sie leicht nutzen können. Diese Arbeit stellt eine Methode vor, fragmentierte Informationen in lebendige „Wissenskarten“ zu verwandeln, die von großen Sprachmodellen angetrieben werden, sodass Planer und Analysten bessere Fragen stellen und schnellere, verlässlichere Antworten erhalten können.
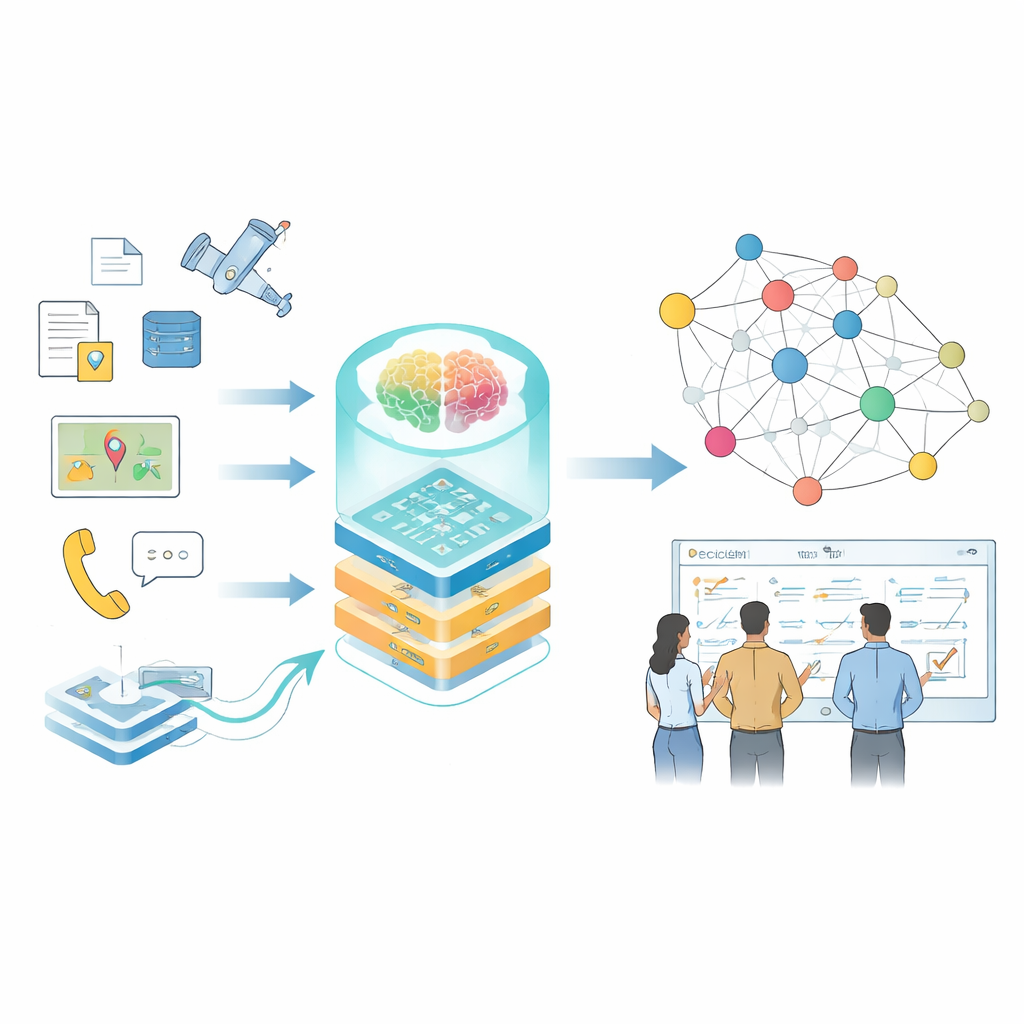
Von verstreuten Fakten zu vernetztem Wissen
Die Autoren konzentrieren sich auf Wissensgraphen, eine Art der Informationsdarstellung als Netz verbundener Fakten — wer was getan hat, mit welchem System, unter welchen Bedingungen. Im Alltag treiben solche Graphen bereits Suchmaschinen und Empfehlungssysteme an, aber spezialisierte Domänen stellen härtere Herausforderungen: Daten sind sensibel, die Terminologie ist dicht, Formate reichen von Freitextberichten bis zu Sensornprotokollen, und die Bedingungen ändern sich schnell. Traditionelle Werkzeuge, die auf handgeschriebenen Regeln oder kleinen Modellen beruhen, haben Mühe mitzuhalten, und allgemeine Sprachmodelle lesen technische Begriffe oft falsch oder übersehen subtile Beziehungen, die für reale Entscheidungen wichtig sind.
Großen Sprachmodellen ein neues Fachgebiet beibringen
Um dem zu begegnen, feinjustiert die Studie ein leistungsfähiges Basissprachenmodell mit einem sorgfältig gestalteten, domänenspezifischen Datensatz. Der Datensatz stützt sich auf Befehlskommunikation, Gerätehandbücher, simulierte Szenarien und Fachliteratur. Bevor dieses Material das Modell erreicht, wird es stark entsensibilisiert: konkrete Koordinaten werden zu relativen Orten, Einheitennamen zu generischen Codes und sensible Logik wird teilweise maskiert, während allgemeine Muster erhalten bleiben. Die Daten werden in einem strukturierten Format gespeichert, das die Gesamtsituation, die spezifischen Aufgaben (wie Planung, Gefährdungsbewertung oder Fragebeantwortung) und die Verknüpfungen zwischen ihnen beschreibt. Diese Struktur lässt das Modell nicht nur isolierte Fakten lernen, sondern auch, wie verschiedene Aufgaben Kontext teilen.
Schichten der Anpassung für unterschiedliche Aufgaben
Statt alle Parameter des Sprachmodells neu zu trainieren — ein kosten- und risikoreicher Prozess — nutzen die Autoren eine Technik namens Low‑Rank‑Adaptation, organisiert in mehrere Schichten, die sich jeweils auf einen anderen Aspekt des Problems konzentrieren. Eine Schicht erfasst grundlegende Terminologie und Konzepte, eine andere bettet operationelle Regeln und Beschränkungen ein, und eine dritte spezialisiert sich auf die Anpassung an konkrete Aufgaben wie Planung oder Gefährdungsbewertung. Eine separate Steuerkomponente, das „Routing“-Netzwerk, betrachtet jede Eingabe und entscheidet, welche Kombination dieser leichten Adapter das Modell verwenden soll. Dieses Design erlaubt dem System, effizient zwischen Aufgaben zu wechseln und dabei sowohl allgemeine Sprachfähigkeiten als auch domänenspezifische Expertise zu bewahren.
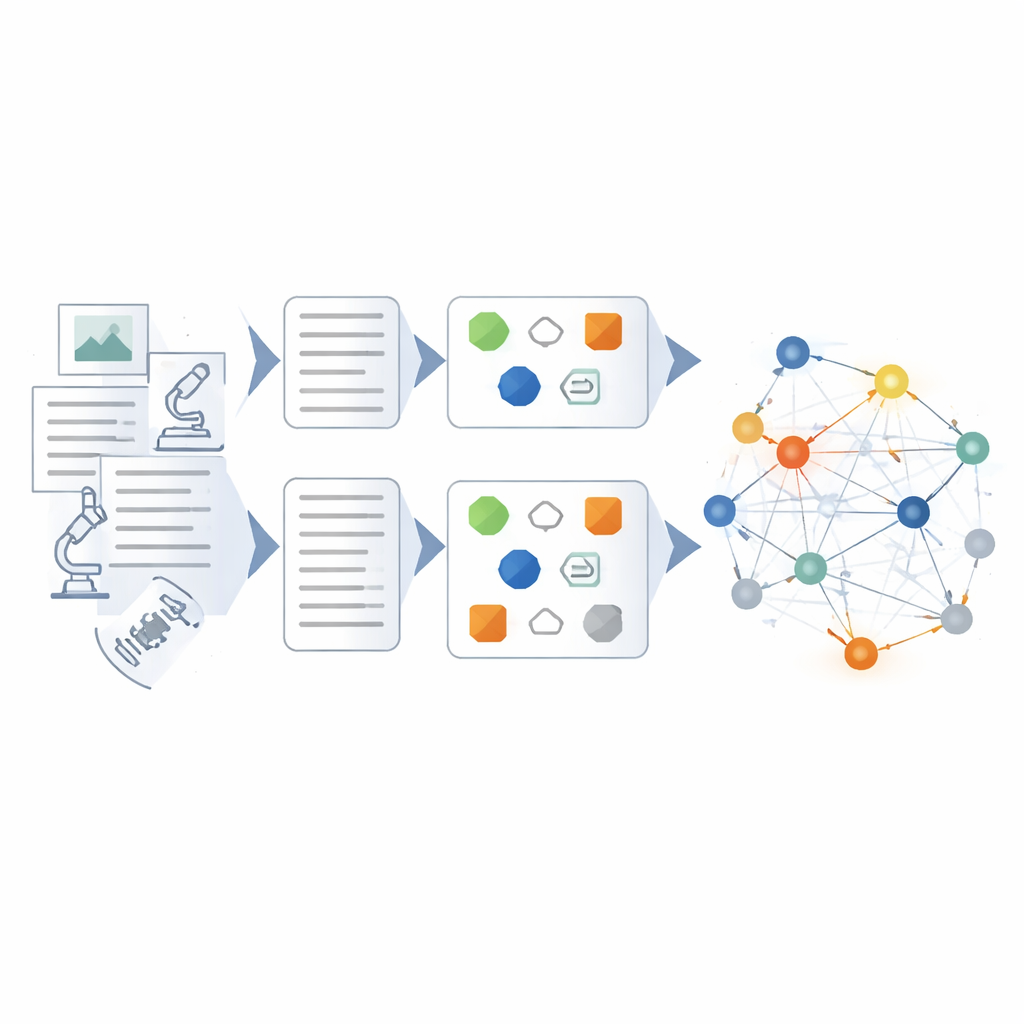
Aufbau und Überprüfung des Wissensnetzwerks
Auf dem feinjustierten Modell bauen die Autoren eine hybride Pipeline zum eigentlichen Aufbau des Wissensgraphen. Zuerst werden Rohdaten bereinigt und standardisiert, sodass Begriffe und Formate konsistent sind. Danach extrahieren regelbasierte Methoden und von Experten erstellte Vorlagen offensichtliche Entitäten und Ereignisse. Das feinjustierte Sprachmodell tritt ein, um komplexere Aufgaben zu übernehmen: Unübersichtliche Berichte zu prägnanten Zusammenfassungen zu kürzen, Schlüsselakteure und Ausrüstung zu identifizieren und Beziehungen wie Ursache‑Wirkungs‑Ketten oder Koordination zwischen Einheiten zu erschließen. Jede extrahierte Tatsache wird aus mehreren Blickwinkeln bewertet — wie gut sie zu bekannten Mustern passt, wie stark sie mit anderen Fakten verbunden ist und ob sie mit mehrstufigen Schlusswegem durch den Graphen übereinstimmt. Nur Ergebnisse mit hoher Konfidenz werden ergänzt, niedrig bewertete Einträge werden zur Überprüfung markiert.
Nachgewiesene Verbesserungen bei Genauigkeit und Verlässlichkeit
Das Team bewertet seinen Ansatz anhand von drei Kernaufgaben, die reale Bedürfnisse widerspiegeln: komplexe Fragen zu Vorschriften und Ausrüstung beantworten, Aktionspläne für gegebene Situationen vorschlagen und verschiedene Bedrohungsszenarien nach Schwere ordnen. In allen diesen Aufgaben übertrifft das angepasste Modell beständige, bekannte allgemeine Systeme, einschließlich fortgeschrittener Modelle mit deutlich generischerem Training. Es beantwortet mehr Fragen korrekt, erzeugt realistischere Pläne und bewertet Bedrohungen genauer. Der resultierende Wissensgraph ist sowohl groß als auch eng vernetzt, wobei über 90 Prozent der gespeicherten Fakten strenge Konfidenzprüfungen bestehen und Planern helfen, schneller fundierte Entscheidungen zu treffen.
Warum das künftig wichtig ist
Für eine fachfremde Leserschaft ist die Kernbotschaft: Sprachmodelle lassen sich von geschliffenen Rednern in sorgfältige, spezialisierte Analysten verwandeln — wenn sie mit den richtigen Daten trainiert, durch klare Regeln eingegrenzt und kontinuierlich auf Qualität geprüft werden. Diese Arbeit zeigt, wie das in einer sensiblen, sich schnell verändernden Domäne gelingt und dabei private Informationen schützt. Das Rahmenwerk organisiert nicht nur verstreutes Wissen in ein nutzbares Netz, sondern hält dieses Netz auch aktuell und vertrauenswürdig und bietet damit eine Blaupause für künftige Entscheidungsunterstützungssysteme in jedem Bereich, in dem komplexe Entscheidungen wirklich zählen.
Zitation: Peng, L., Yang, P., Juexiang, Y. et al. The construction and refined extraction techniques of knowledge graph based on large language models. Sci Rep 16, 8104 (2026). https://doi.org/10.1038/s41598-026-38066-w
Schlüsselwörter: Wissensgraph, großes Sprachmodell, Entscheidungsunterstützung, Domänenanpassung, Datenentsensibilisierung