Clear Sky Science · de
Erzeugung von grenzwertigen Testmustern für Zufallstester mittels intelligenter Optimierung und evolutionärer Algorithmen
Warum fast‑zufällig für die alltägliche Sicherheit wichtig ist
Jedes Mal, wenn Sie online einkaufen, Ihr Telefon entsperren oder eine private Nachricht senden, werden unsichtbare mathematische Würfel geworfen, um Ihre Daten zu schützen. Diese Würfel erscheinen als lange Folgen angeblich zufälliger Bits, die als kryptographische Schlüssel dienen. Sind diese Bits auch nur geringfügig weniger zufällig als nötig, können entschlossene Angreifer mitunter Muster finden und ausnutzen. Dieses Papier untersucht eine neue Methode zur Herstellung von „fast‑zufälligen“ Testsequenzen — Daten, die extrem zufällig wirken, aber winzige Schwächen verbergen — damit Ingenieure die Geräte, die unser digitales Leben schützen, ernsthaft Belastungstests unterziehen können.
Wenn Zufallszahlen nicht ganz zufällig genug sind
Moderne Sicherheitssysteme verlassen sich auf zwei Arten von Zufallszahlengeneratoren. Echte Zufallszahlengeneratoren nutzen unvorhersehbare physikalische Effekte wie elektronisches Rauschen oder Quantenschwankungen, während Pseudozufallsgeneratoren Algorithmen sind, die kurze, zufällige Samen in lange Folgen verwandeln. In der Praxis hängt die Qualität beider letztlich von der physikalischen Quelle der Unvorhersehbarkeit ab, der sogenannten Entropiequelle. Leider sind reale Entropiequellen anfällig: Temperaturschwankungen, Alterung der Hardware oder Konstruktionsfehler können ihre Zufälligkeit heimlich reduzieren. Um solche Probleme zu erkennen, definieren Normungsorganisationen wie NIST Batteries von statistischen Tests, die prüfen, ob Ausgabebits zufällig genug erscheinen. Geräte integrieren zunehmend „Echtzeit‑Zufallstestgeräte“, die ihre eigene Ausgabe während des Betriebs überwachen. Bislang gab es jedoch keine gute Methode, realistische, schwer zu entdeckende Fehlerfälle zu erzeugen, um zu testen, ob diese eingebetteten Prüfer tatsächlich funktionieren.
Sequenzen entwerfen, die zufällige Tests knapp nicht bestehen
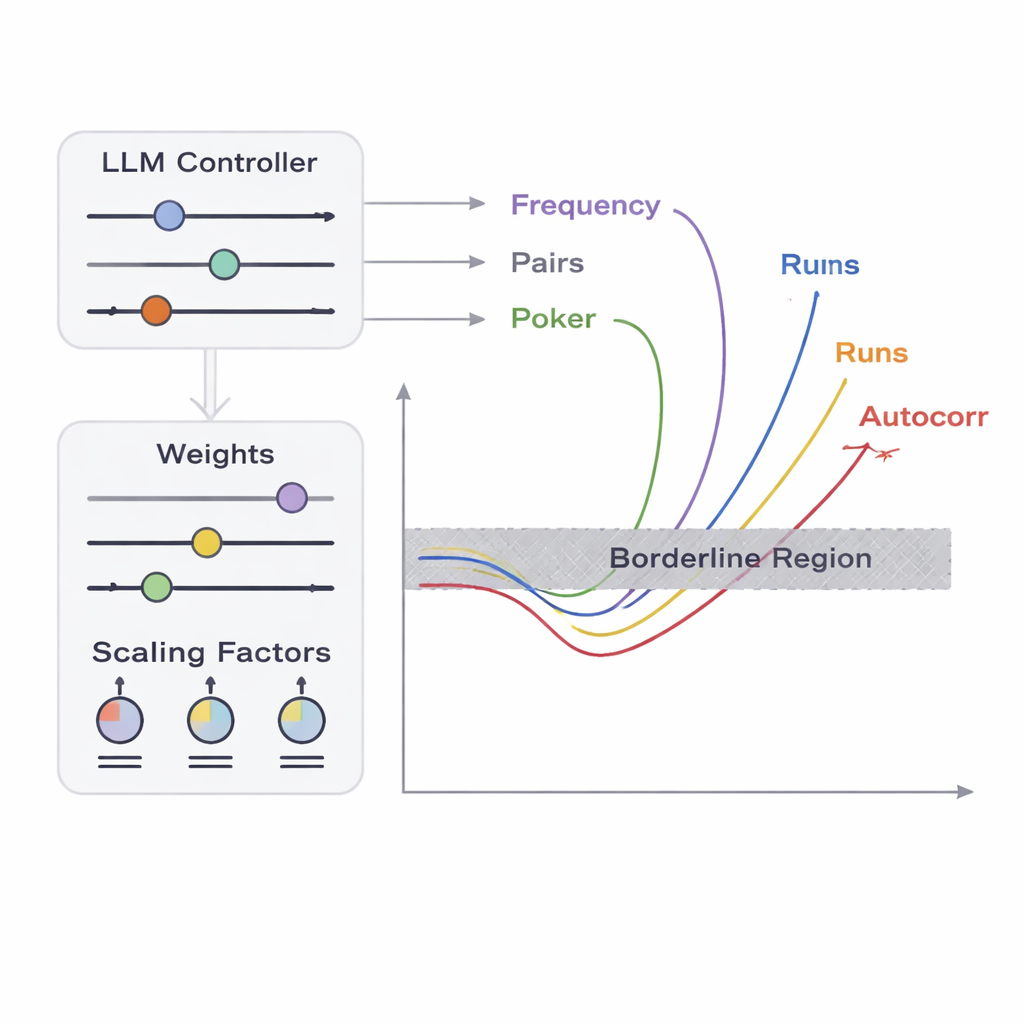
Aus Sicht eines Testers sind triviale Fehler — etwa Ausgaben, die nur Nullen enthalten — leicht zu erkennen. Die eigentliche Herausforderung besteht darin, Randfälle zu entdecken: Sequenzen, die nahezu ununterscheidbar von idealer Zufälligkeit sind, aber gerade so ein oder mehrere statistische Tests nicht bestehen. Die Autoren konzentrieren sich auf fünf klassische Tests, die unterschiedliche Aspekte von Bitmustern untersuchen, darunter wie oft Nullen und Einsen erscheinen, wie Bitpaare sich verhalten, wie bestimmte kurze Muster verteilt sind, wie Bits mit verschobenen Kopien von sich selbst korrelieren und wie die Längen von Läufen identischer Bits angeordnet sind. Für jeden Test definieren sie eine „Grenzzone“: ein schmales Band, in dem die Daten die üblichen Akzeptanzschwellen nur geringfügig verletzen. Eine lange Sequenz zu erzeugen, die gleichzeitig in allen diesen schmalen Zonen liegt, ist rein zufällig extrem unwahrscheinlich, weil die Tests auf komplizierte, nichtlineare Weise interagieren. Hier kommen Optimierung und KI ins Spiel.
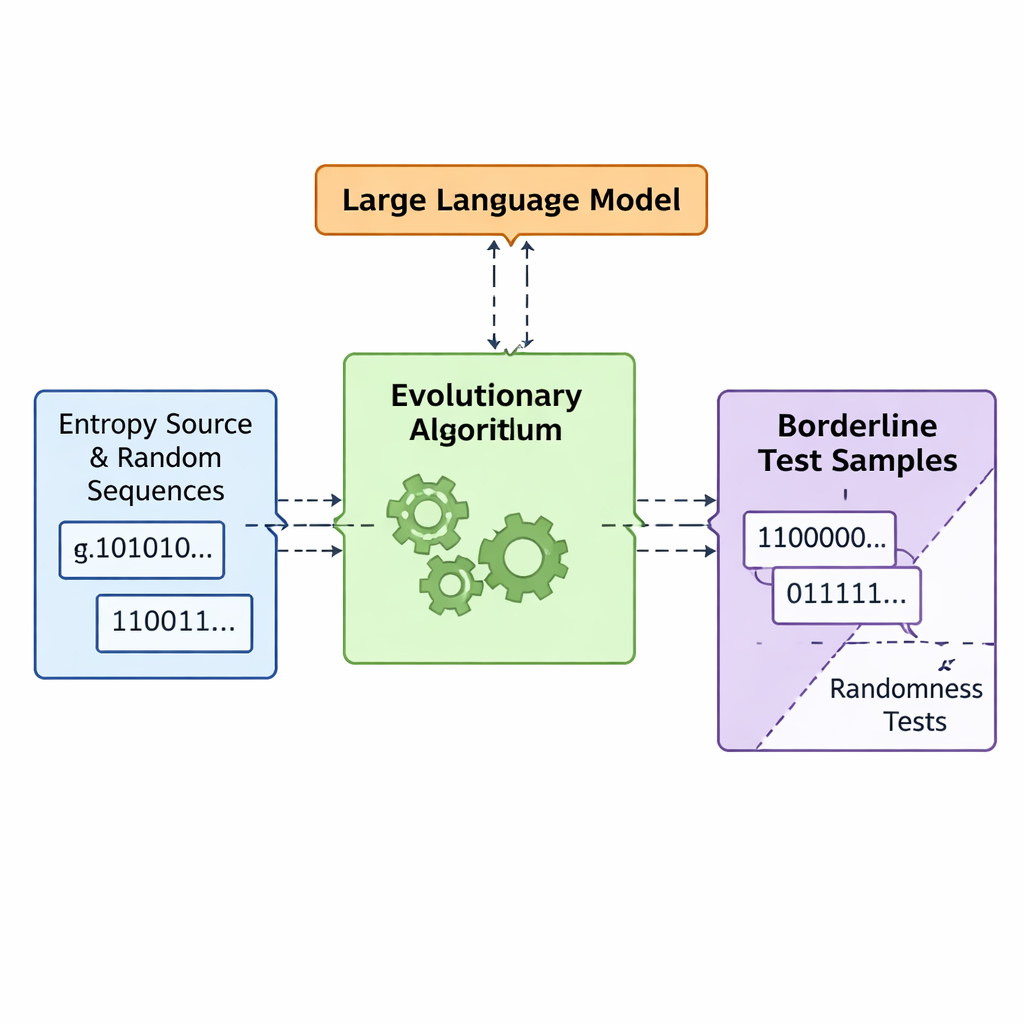
Evolution und Sprachmodelle entwerfen zusammen schlechte Zufälligkeit
Das Team stellt ein Framework namens APAM‑IGLLM vor, das die Sequenzgenerierung als hochdimensionales Optimierungsproblem behandelt. Jede Kandidatensequenz ist eine Bitfolge, und ihre „Fitness“ misst, wie nahe sie den Grenzbereichen der fünf Tests kommt. Ein genetischer Algorithmus mutiert und rekombiniert diese Sequenzen wiederholt und behält diejenigen, die sich der Zielregion nähern. Darüber hinaus fungiert ein großes Sprachmodell (LLM) als eine Art Strategie‑Coach. In jeder Generation untersucht es zusammenfassende Statistiken der Population und die kurzfristige Historie und schlägt dann vor, wie interne Drehregler — Gewichte und Skalierungsfaktoren, die bestimmen, wie stark jeder Test die Fitness beeinflusst — angepasst werden sollten. Das erzeugt eine Rückkopplungsschleife: Der genetische Algorithmus erkundet den Raum möglicher Sequenzen, während das LLM die Suche so steuert, dass alle fünf Testwerte auf die winzige Schnittmenge konvergieren, in der Sequenzen gerade noch als nicht‑zufällig gelten.
Wie sehr können fehlerhafte Daten wie perfekte Zufälligkeit aussehen?
Um zu prüfen, ob ihre künstlichen Fehler realistisch wirken, vergleichen die Autoren ihre erzeugten Sequenzen mit weit verbreiteten Referenzwerten. Sie berechnen sowohl Shannon‑Entropie als auch Min‑Entropie, Maße dafür, wie unvorhersehbar jedes Byte erscheint, und finden Werte um 7,6–8 Bit pro Byte — sehr nahe am theoretischen Maximum von 8 und vergleichbar mit kommerziellen Hardware‑Zufallsquellen und dem öffentlichen Zufalls‑Beacon des NIST. Sie führen außerdem die vollständige NIST SP 800‑22 Testreihe durch und beobachten, dass ihre Grenzsequenzen in nahezu demselben Muster bestehen und fallen wie echte, hochwertige Zufallsdaten. Mit anderen Worten: Für standardisierte Werkzeuge sehen diese Proben im Wesentlichen normal aus, obwohl sie bewusst so konstruiert wurden, dass sie nahe an mehreren Versagensschwellen liegen. Damit sind sie ideale „adversarielle“ Eingaben, um zu prüfen, wie robust eingebettete Zufallstester wirklich sind.
Was das für die reale Sicherheit bedeutet
Aus Sicht eines Laien bietet diese Arbeit eine neue Methode, die Zufallszahl‑Mechanik, die Verschlüsselung untermauert, sicherheitsüberprüfbar zu machen. Anstatt Geräte nur mit eindeutig kaputter oder eindeutig gesunder Zufälligkeit zu testen, können Ingenieure sie nun mit sorgfältig gestalteten, fast‑einwandfreien Sequenzen bombardieren, die subtile Hardwarefehler oder Umwelteinflüsse nachahmen. Wenn ein Echtzeit‑Zufallstester diese Grenzfälle übersieht, deutet das auf eine potenzielle blinde Stelle hin, die behoben werden sollte, bevor das Gerät im Bankwesen, in der sicheren Kommunikation oder in Blockchain‑Systemen eingesetzt wird. Durch die Verwendung einer von einem Sprachmodell geleiteten evolutionären Suche liefern die Autoren ein praktisches Werkzeug zur Erzeugung solcher anspruchsvollen Testdaten und tragen so dazu bei, die verborgenen Grundlagen der digitalen Sicherheit auf höhere Zuverlässigkeitsniveaus zu heben.
Zitation: Gao, P., Zhang, B., Wang, Z. et al. Generating borderline test samples for randomness testers via intelligent optimization and evolutionary algorithms. Sci Rep 16, 7268 (2026). https://doi.org/10.1038/s41598-026-38020-w
Schlüsselwörter: Zufallszahlengeneratoren, Entropiequellen, evolutionäre Algorithmen, große Sprachmodelle, kryptographische Tests