Clear Sky Science · de
APMSR: ein intelligentes QA‑System für die synthetische Biologie, gestützt durch adaptive Prompting-Strategien und mehrquellenbasierte Wissensrecherche
Klügere Antworten für eine neue Art von Biologie
Die synthetische Biologie verspricht sauberere Kraftstoffe, umweltfreundlichere Produktionsstätten und neue medizinische Behandlungen, doch die Forschung schreitet so rasch voran, dass selbst Fachleute schwer Schritt halten können. Diese Studie stellt APMSR vor, ein intelligentes Frage‑Antwort‑System, das Forschern helfen soll, schnell verlässliche Antworten zu einer wichtigen Biofuel‑Mikrobe, Zymomonas mobilis, zu finden. Durch die Kombination großer Sprachmodelle mit sorgfältig ausgewählten Online‑ und Offline‑Quellen zielt das System darauf ab, präzise und aktuelle Antworten zu liefern, statt selbstbewusste, aber falsche Vermutungen zu erzeugen.
Die Herausforderung, gute Fragen zu stellen
Wissenschaftler verlassen sich bereits auf Suchmaschinen und Online‑Datenbanken, doch diese Werkzeuge liefern oft lange Listen von Artikeln statt direkte Antworten. Große Sprachmodelle (LLMs) können zu vielen Themen flüssig Auskunft geben, in schnelllebigen Bereichen wie der synthetischen Biologie können sie jedoch neuere Erkenntnisse verpassen oder schlichtweg Fehler erfinden. Die Autoren konzentrieren sich auf das praktische Problem, Expertenfragen zu Z. mobilis zu beantworten — ein Bakterium, das dafür geschätzt wird, Zucker effizient in Ethanol umzuwandeln. In diesem Kontext sind falsche Antworten nicht nur ärgerlich, sondern können Experimente und Investitionen in die falsche Richtung lenken.
Die KI mit den richtigen Anweisungen lenken
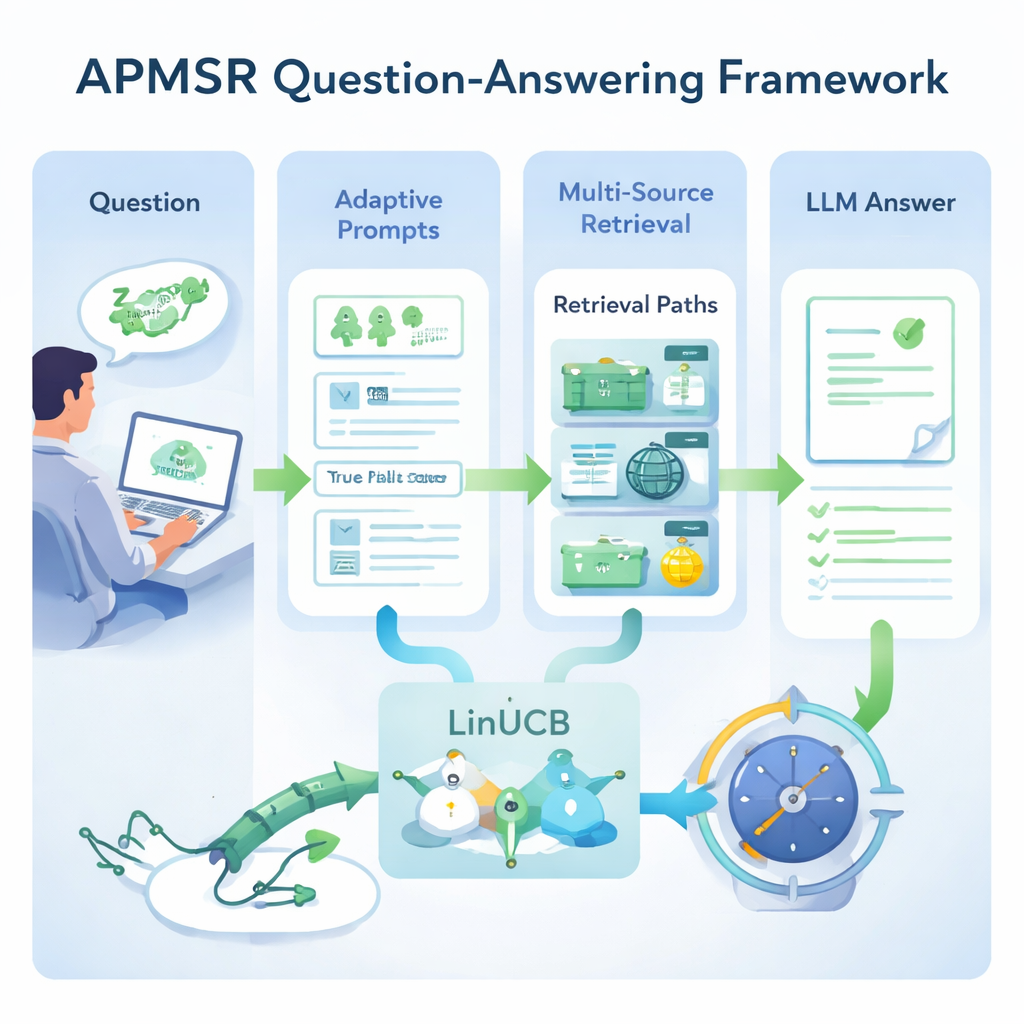
Eine zentrale Idee von APMSR ist, dass die Art, wie man das Modell anspricht, ebenso wichtig ist wie die Frage selbst. Statt eine einzige, fixe Anweisung zu verwenden, bittet das System das LLM zunächst zu erkennen, um welche Frageart es sich handelt — etwa eine Multiple‑Choice‑Aufgabe oder eine Wahr/Falsch‑Aussage. Sobald der Typ identifiziert ist, wählt APMSR automatisch eine passende „Prompt‑Vorlage“, die dem Modell vorgibt, wie es zu argumentieren und wie es seine Antwort zu formatieren hat. Multiple‑Choice‑Fragen werden beispielsweise dazu angeleitet, Optionen sorgfältig zu vergleichen, während Wahr/Falsch‑Fragen dazu gelenkt werden, die Richtigkeit einer Aussage zu prüfen und zu erklären, warum. Dieses adaptive Prompting hilft, das Modell fokussiert zu halten und abschweifende, themenfremde Antworten zu reduzieren.
Den besten Ort zur Faktenrecherche wählen
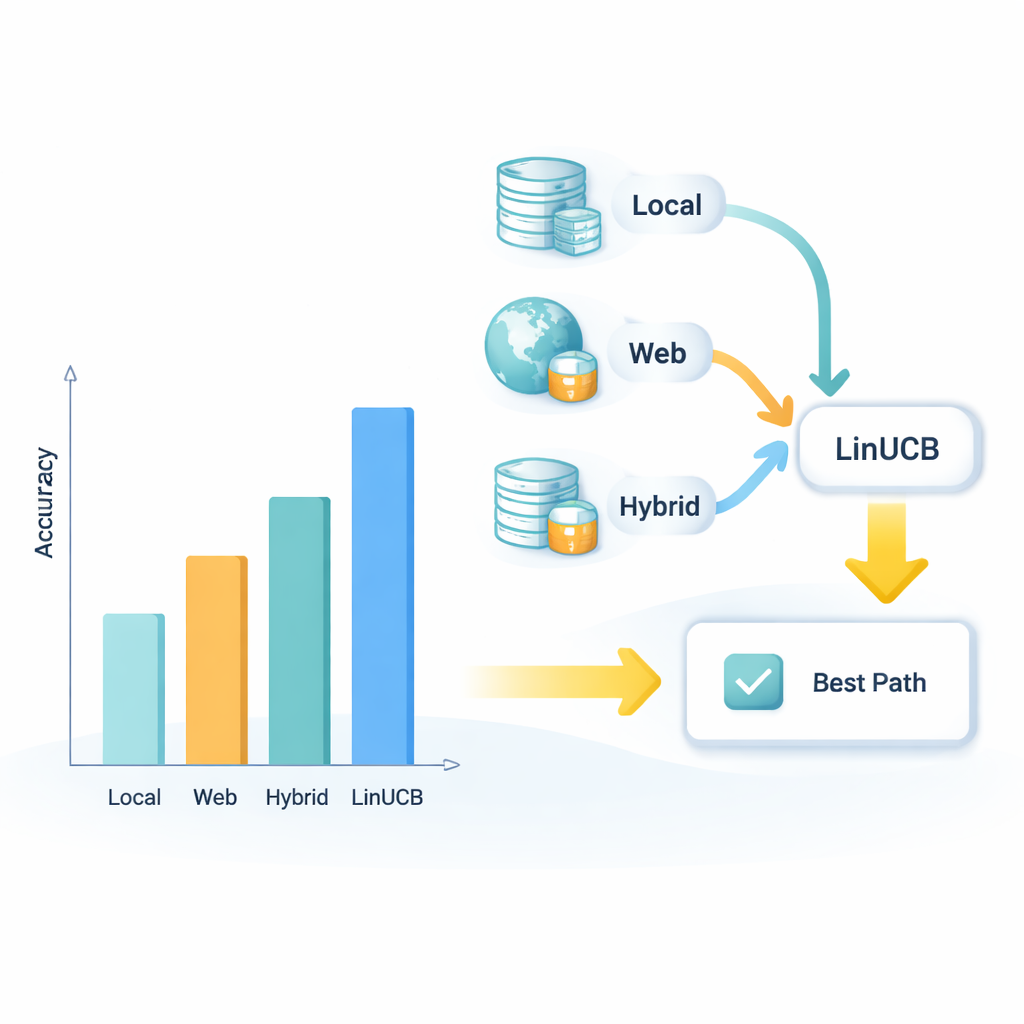
Gute Anweisungen allein genügen nicht; das System muss auch an den richtigen Stellen nachschauen. APMSR verbindet sich mit drei Arten von Informationsquellen: einer lokalen Bibliothek kuratierter Fachartikel, aktuellen Webressourcen und einer Hybridquelle, die beide vereint. Für jede Nutzeranfrage behandelt das System diese drei Optionen als konkurrierende „Pfade“ und nutzt eine mathematische Strategie namens LinUCB, die ursprünglich zur Abwägung von Risiko und Ertrag in Entscheidungsproblemen entwickelt wurde. LinUCB bewertet, wie gut jeder Pfad auf Basis früherer Fragen und ihrer Ergebnisse zu funktionieren scheint, und wählt dann den Pfad aus, der am wahrscheinlichsten eine korrekte Antwort liefert, während gelegentlich Alternativen ausprobiert werden. Im Laufe der Zeit lehrt diese Rückkopplungsschleife das System, welche Kombinationen von Quellen sich für verschiedene Fragearten als besonders vertrauenswürdig erweisen.
Das System auf die Probe stellen
Um zu prüfen, ob diese Ideen tatsächlich helfen, erstellte das Team einen spezialisierten Testdatensatz von 220 Expertenfragen zu Z. mobilis, gleichmäßig aufgeteilt in Multiple‑Choice‑ und Wahr/Falsch‑Formate, alle entnommen aus peer‑reviewten Studien. Sie verglichen drei Konfigurationen: ein nacktes LLM ohne externe Dokumente, ein standardmäßiges retrieval‑augmented System, das nur eine lokale Datenbank nutzt, und ihr vollständiges APMSR‑Design. Die Genauigkeit stieg von 54 % beim nackten Modell auf 80 % mit standardisierter Retrieval‑Unterstützung und weiter auf 93 %, nachdem adaptive Prompts und der LinUCB‑basierte Pfadselektor hinzugefügt wurden. Das optimierte System übertraf außerdem ein existierendes, auf synthetische Biologie spezialisiertes Modell namens SynBioGPT um etwa 19 Prozentpunkte, was darauf hindeutet, dass clevere Orchestrierung von Prompts und Retrieval wichtiger sein kann als allein ein größeres Modell zu trainieren.
Was das für zukünftige Laborarbeit bedeutet
Für Nicht‑Spezialisten ist die wichtigste Erkenntnis, dass die Autoren eine Art „Forschungs‑Co‑Pilot“ gebaut haben, der nicht nur flüssig formuliert, sondern auch weiß, wann er mehrere Quellen prüfen und wie er sein eigenes Denken strukturieren muss. Indem sowohl die Formulierung von Fragen als auch die Art der Informationsbeschaffung feinabgestimmt werden, verringert APMSR irreführende Antworten in einem komplexen, sich schnell entwickelnden Feld deutlich. Während das aktuelle System auf eine einzelne Mikrobe und auf Quiz‑artige Fragen fokussiert ist, ließe sich derselbe Ansatz auf breitere Bereiche der Biologie und darüber hinaus ausweiten und Wissenschaftlern, Ingenieuren und möglicherweise eines Tages auch Klinikern helfen, bessere Fragen zu stellen und vertrauenswürdigere Antworten von KI‑Werkzeugen zu erhalten.
Zitation: Wang, J., Cao, Z., Tian, Z. et al. APMSR: an intelligent QA system for synthetic biology empowered by adaptive prompting and multi-source knowledge retrieval. Sci Rep 16, 7331 (2026). https://doi.org/10.1038/s41598-026-38006-8
Schlüsselwörter: synthetische Biologie, Fragebeantwortung, große Sprachmodelle, retrieval augmented generation, Zymomonas mobilis