Clear Sky Science · de
Korrigieren verrauschter Labels durch vergleichende Distillation: ein Domain‑Adaptation‑Ansatz
Warum unordentliche Daten ein wachsendes Problem sind
Moderne künstliche Intelligenz lebt von Daten, doch diese Daten sind oft fehlerhaft, unvollständig oder inkonsistent beschriftet. Wenn Labels verrauscht sind – etwa ein Katzenfoto fälschlich als Hund markiert – können Lernsysteme in die Irre geführt werden und an Genauigkeit und Zuverlässigkeit verlieren. Dieses Paper adressiert genau dieses Problem aus der Praxis: wie man Bilderkennungssysteme so trainiert, dass sie auch dann gut funktionieren, wenn die Trainingslabels fehlerhaft sind und die Bilder aus unterschiedlichen Umgebungen stammen, etwa Onlineshops versus Fotos aus der realen Welt.
Lernen über unterschiedliche Welten hinweg
In der Praxis lernen KI‑Modelle oft in einer „Quell“-Welt mit sauber geprüften Labels und müssen dann in einer „Ziel“-Welt bestehen, in der Labels knapp und fehleranfällig sind. Beispielsweise sind Bürogegenstände, die im Studio fotografiert wurden, ordentlich und korrekt gelabelt, während Webcam‑ oder Alltagsfotos derselben Objekte unordentlich und inkonsistent getaggt sind. Traditionelle Domain‑Adaptation‑Methoden versuchen, diese Lücke durch Angleichung der statistischen Gesamteigenschaften der beiden Welten zu überbrücken. Sie gehen dabei jedoch meist davon aus, dass Ziel‑Labels, sofern vorhanden, korrekt sind – eine riskante Annahme, die in realen Anwendungen mit Crowd‑Sourcing, minderwertigen Sensoren oder automatischen Annotationstools versagt.
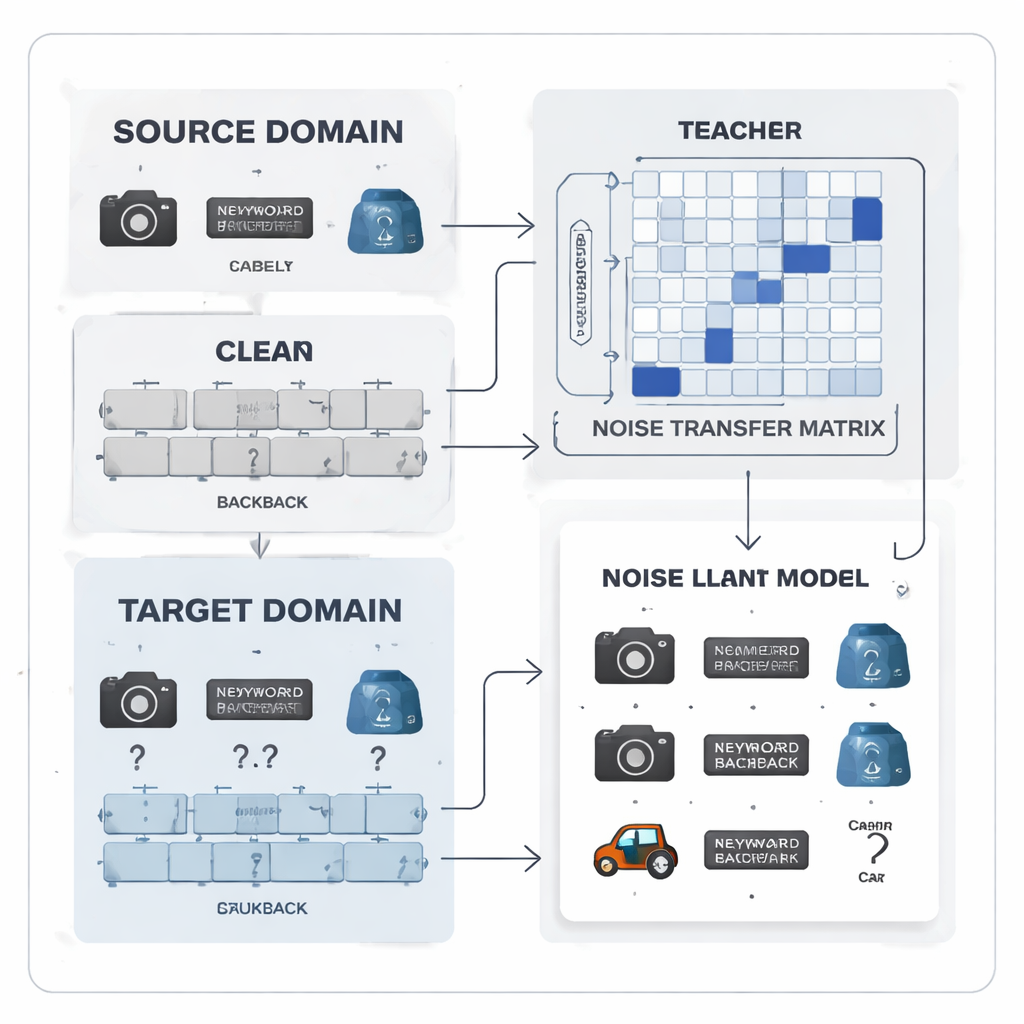
Label‑Fehler als lernbares Muster behandeln
Die Autoren schlagen vor, Label‑Rauschen nicht als zufälliges Chaos, sondern als ein lernbares Muster zu behandeln. Sie führen eine „Noise‑Transfer‑Matrix“ ein, eine Tabelle, die erfasst, wie wahrscheinlich es ist, dass eine wahre Klasse als eine andere fehlbeschriftet wird. Anstatt diese Matrix aus wenigen perfekten „Anchor“-Beispielen zu schätzen – was unrealistisch ist, wenn Labels verrauscht und Klassen unausgewogen sind – wird die Matrix direkt während des Trainings gelernt. Um das Lernen zu initialisieren, baut die Methode Kategorien‑„Prototypen“ auf, durchschnittliche Merkmalsprofile jeder Klasse, die von einem leistungsfähigen vortrainierten Modell extrahiert werden. Die Ähnlichkeit dieser Prototypen wird zur Initialisierung der Matrix genutzt, sodass von Anfang an stärker verwechselbare Kategorien, etwa ähnliche Bürowerkzeuge, enger verknüpft sind und das System frühzeitig befähigt wird, Labels zu korrigieren.
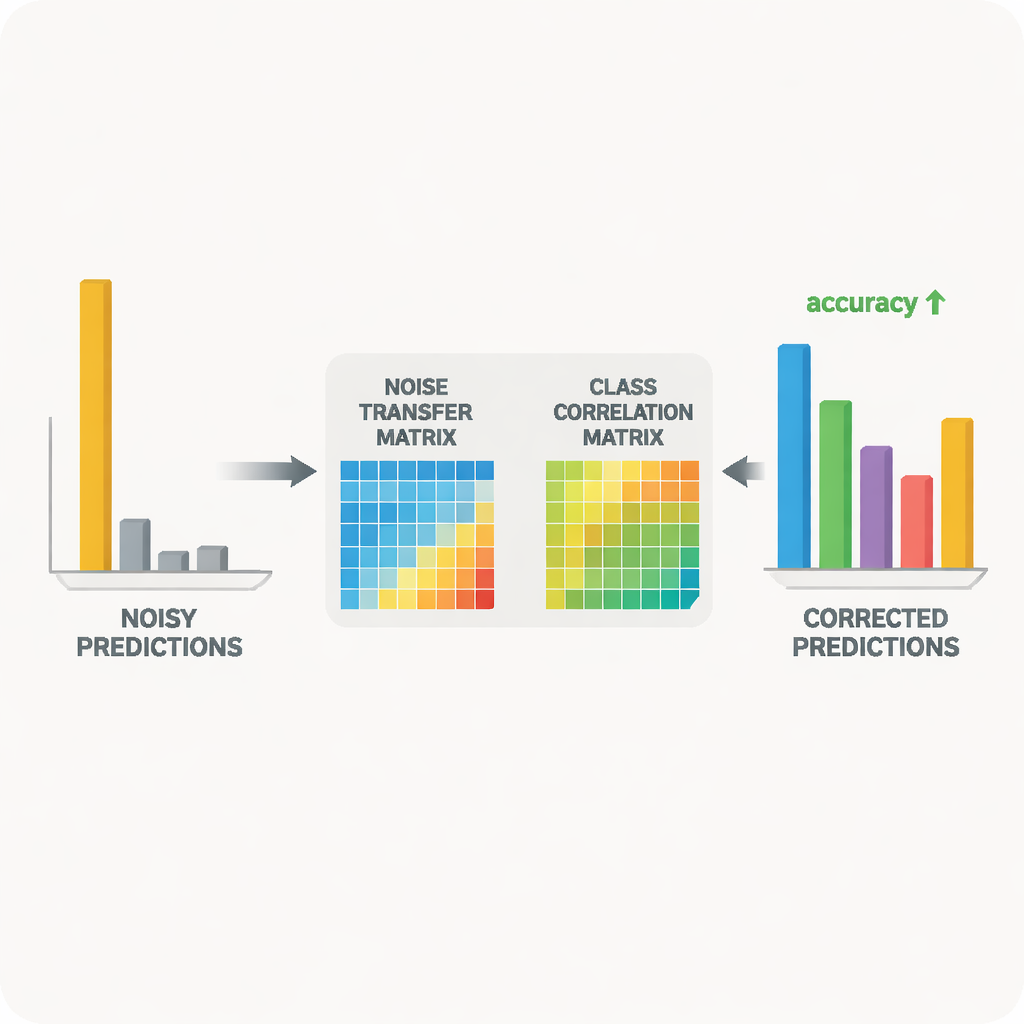
Lehrer‑Schüler‑Zusammenarbeit für sauberere Signale
Im Kern des Systems steht ein Lehrer‑Schüler‑Paar von neuronalen Netzen. Der Lehrer basiert auf einem großen selbstüberwachten Vision‑Modell, das aus massiven unbeschrifteten Daten reiche visuelle Merkmale gelernt hat. Der Schüler ist ein leichteres Netzwerk, das auf den verrauschten Ziel‑Daten gut funktionieren muss. Der Lehrer erzeugt weiche Vorhersagewerte, die aufzeigen, wie Klassen zueinander in Beziehung stehen; aus diesen Werten konstruiert die Methode eine Klassenkorrelationsmatrix, die zusammenfasst, welche Labels tendenziell zusammen auftreten. Diese Matrix dient als Leitfaden und lenkt die Noise‑Transfer‑Matrix in Richtung realistischer Korrekturen. Gleichzeitig wird der Schüler durch Distillation dazu gebracht, das Verhalten des Lehrers nachzuahmen, während kontrastives Lernen beide Netzwerke dazu ermutigt, ähnlichen internen Repräsentationen für unterschiedliche augmentierte Ansichten desselben Bildes und unterscheidbare Repräsentationen für unterschiedliche Objekte zu genügen.
Korrekturen stabil halten und Überconfidence vermeiden
Die unbegrenzte Anpassung der Noise‑Transfer‑Matrix könnte sie instabil oder überempfindlich gegenüber Ausreißern machen. Um dem vorzubeugen, nutzen die Autoren einen mathematischen Trick auf Basis der Singulärwertzerlegung, die die Matrix in grundlegende Dehnungsrichtungen zerlegt. Indem sie das implizite „Volumen“ dieser Richtungen bestrafen, verhindert die Methode extreme Verzerrungen, die Rauschen verstärken würden. Ein weiteres Problem entsteht, wenn das Modell zu sicher wird und nahezu die gesamte Wahrscheinlichkeit einer Klasse zuweist; bei solchen scharfen Vorhersagen wird es schwierig, falsche Labels zu korrigieren. Zur Abhilfe ergänzt die Methode eine Form der Entropieregulierung, basierend auf Tsallis‑Entropie, die die Vorhersagewahrscheinlichkeiten glättet. Dadurch lässt sich Wahrscheinlichkeitsteilmasse leichter von einer falschen Klasse auf plausiblere Alternativen umverteilen.
Die Idee an realen Bildsammlungen belegen
Die Forschenden testeten ihren Ansatz an zwei weit verbreiteten Benchmarks für domänenübergreifende Objekterkennung: Office‑31 und Office‑Home, die Bilder alltäglicher Bürogegenstände in verschiedenen Stilen wie Produktfotos, Clip‑Art und realen Schnappschüssen enthalten. Bei einer Reihe von „auf einem Stil trainieren, auf einem anderen testen“-Aufgaben erreichte ihre Methode gleichwertige oder bessere Ergebnisse als führende Algorithmen, insbesondere in den schwierigsten Fällen mit der größten Domänenverschiebung. Detaillierte Untersuchungen zeigten, dass jede Komponente – die Volumenregulierung der Rauschmatrix, die Führung durch Klassenkorrelationen und die Entropieglättung – messbare Verbesserungen beitrug. Visualisierungen der gelernten Matrix und des Merkmalsraums bestätigten, dass sich im Verlauf des Trainings fehlbeschriftete Beispiele allmählich in Richtung ihrer richtigen Kategorien verschoben und dass die Verteilungen von Quell‑ und Zielbildern besser angeglichen wurden.
Was das für alltägliche KI‑Systeme bedeutet
Für Nichtfachleute ist die wichtigste Erkenntnis, dass diese Arbeit KI‑Modelle nachsichtiger gegenüber menschlichen und maschinellen Fehlern bei der Datenbeschriftung macht, insbesondere wenn die Modelle von sauberen Laborbedingungen in unordentlichere reale Umgebungen wechseln müssen. Indem explizit gelernt wird, wie Labels typischerweise falsch gehen, und ein leistungsfähiges Lehrermodell zur Steuerung der Korrekturen eingesetzt wird, kann die Methode verrauschte Trainingssignale bereinigen und genauere, robustere Klassifikatoren liefern. Obwohl der Ansatz zusätzlichen Rechenaufwand erfordert, weist er in eine Zukunft, in der große, unvollkommene Datensätze, die „in freier Wildbahn“ gesammelt wurden, sicherer und effektiver nutzbar gemacht werden können, wodurch die Abhängigkeit von mühsamer manueller Annotation reduziert wird.
Zitation: Feng, Y., Liu, J. & Zhong, H. Correcting noisy labels via comparative distillation: a domain adaptation approach. Sci Rep 16, 7422 (2026). https://doi.org/10.1038/s41598-026-37935-8
Schlüsselwörter: verrauschte Labels, Domain‑Anpassung, Knowledge Distillation, Bildklassifikation, semi‑überwachtes Lernen