Clear Sky Science · de
Risikoempfindliche doppelte distributionale Kritiker mit einem Lambda-Unterevertrauensintervall für kontinuierliche Steuerungs‑Reinforcement‑Learning
Robotern Vorsicht beibringen
Viele der heute eindrücklichsten Roboter und Spielprogramme basieren auf Reinforcement Learning, einem Trial‑and‑Error‑Trainingsprozess, bei dem Software‑Agenten durch das Sammeln von Belohnungen lernen. Diese Agenten jagen jedoch häufig dem höchstmöglichen Score hinterher und ignorieren dabei, wie riskant ihre Entscheidungen sind. Das führt zu instabilem Lernen und gelegentlichen Abstürzen. Dieses Papier stellt eine Methode namens TDC-λ (Twin Distributional Critics with a Lambda Lower Confidence Bound) vor, die Agenten nicht nur auf hohe Belohnungen, sondern auch auf verlässlichere Sicherheit während des Lernens ausrichtet.
Warum Stabilität bei lernenden Maschinen wichtig ist
Standardverfahren für kontinuierliche Steuerung, etwa das weit verbreitete TD3 und Soft Actor–Critic (SAC), haben Robotern beigebracht zu laufen, zu hüpfen und in komplexen Simulatoren das Gleichgewicht zu halten. Diese Methoden beurteilen jedoch Aktionen meist anhand einer einzigen Zahl: einer Schätzung des langfristigen erwarteten Ertrags. Dieser einfache Wert kann irreführend sein, wenn der Lernprozess verrauscht ist; das System überschätzt dann leicht, wie gut bestimmte Aktionen tatsächlich sind. Das Ergebnis sind Lernkurven, die im Mittel vielversprechend aussehen, aber von Lauf zu Lauf stark schwanken — ein Problem, wenn dasselbe Verfahren physische Maschinen oder sicherheitskritische Systeme steuern soll.
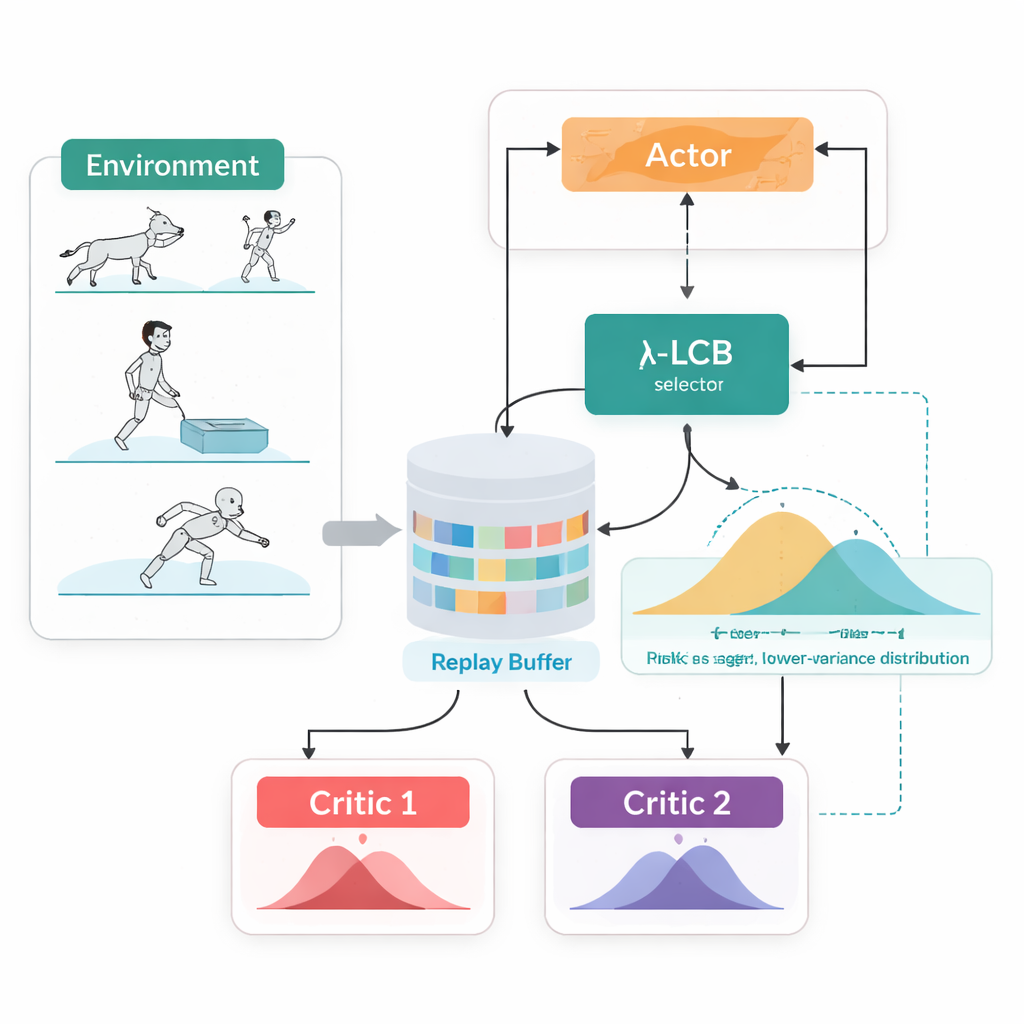
Die komplette Zukunft betrachten, nicht nur einzelne Zahlen
TDC-λ begegnet diesem Problem, indem es die Bewertung der Zukunft durch den Agenten verändert. Anstatt für jede Aktion nur eine erwartete Belohnung vorherzusagen, lernt es zwei getrennte „Kritiker“, die jeweils eine vollständige Verteilung möglicher zukünftiger Rückflüsse ausgeben. Aus diesen Verteilungen berechnet der Algorithmus nicht nur den Mittelwert, sondern auch die Streuung der möglichen Ergebnisse. Diese Streuung spiegelt Unsicherheit oder Risiko wider. Mit einer einfachen Regel, zusammengefasst als ein unteres Vertrauensintervall, bevorzugt TDC-λ den Kritiker, der ein sichereres Ergebnis vorhersagt: eines, das zwar etwas weniger optimistisch sein kann, aber durch konsistentere Evidenz gestützt wird. Eine einzelne Einstellung, der Risikoparameter λ, justiert dabei stufenlos, wie vorsichtig diese Auswahl ist — von einem konventionellen TD3‑ähnlichen Verhalten bei λ = 0 bis zu wachsender Vorsicht mit steigenden λ‑Werten.
Eine Trainingsschleife, zwei Aktionsmodi
Ein weiterer praktischer Aspekt von TDC-λ ist, dass es innerhalb eines einheitlichen Rahmens sowohl deterministische als auch stochastische Aktionswahl unterstützt. Während des Trainings kann man sich für eine klassische deterministische Policy oder für eine tanh‑squashte Gaußsche Policy entscheiden, die Aktionen sampelt und so die Exploration fördert. Unabhängig von dieser Wahl werden die doppelten distributionalen Kritiker auf die gleiche Weise trainiert, und die Evaluation verwendet immer die deterministische Mittelaktion. Dieses Design nutzt frühere Erkenntnisse, wonach deterministisches Verhalten zur Testzeit oft genauso gut oder besser abschneidet als Sampling, während während des Lernens dennoch explorationsfreundliche Policies möglich bleiben.
Das Verfahren auf die Probe gestellt
Die Autoren evaluieren TDC-λ an fünf gängigen MuJoCo‑Benchmarkaufgaben, in denen simulierte Roboter wie HalfCheetah, Hopper, Ant, Walker2d und Humanoid effizientes Vorwärtskommen lernen müssen. Über diese Aufgaben hinweg erreichte die neue Methode mindestens die Endleistung starker Baselines wie TD3, DDPG, SAC und einem fortgeschrittenen flow‑basierten Ansatz namens MEOW oder übertraf sie, und zeigte dabei konsistent geringere Variabilität über wiederholte Läufe. In schwierigeren, hochdimensionaleren Aufgaben wie Humanoid führten etwas höhere λ‑Werte — also konservativere Zielschätzungen — zu den besten langfristigen Erträgen und den engsten Leistungsbändern. Zusätzliche Experimente in anderen Simulatoren (PyBullet und NVIDIA Isaac) sowie Diagnosen, die die Variabilität des Lernsignals verfolgen, bestätigten, dass TDC-λ das Lernen stabilisiert, ohne es zu verlangsamen.
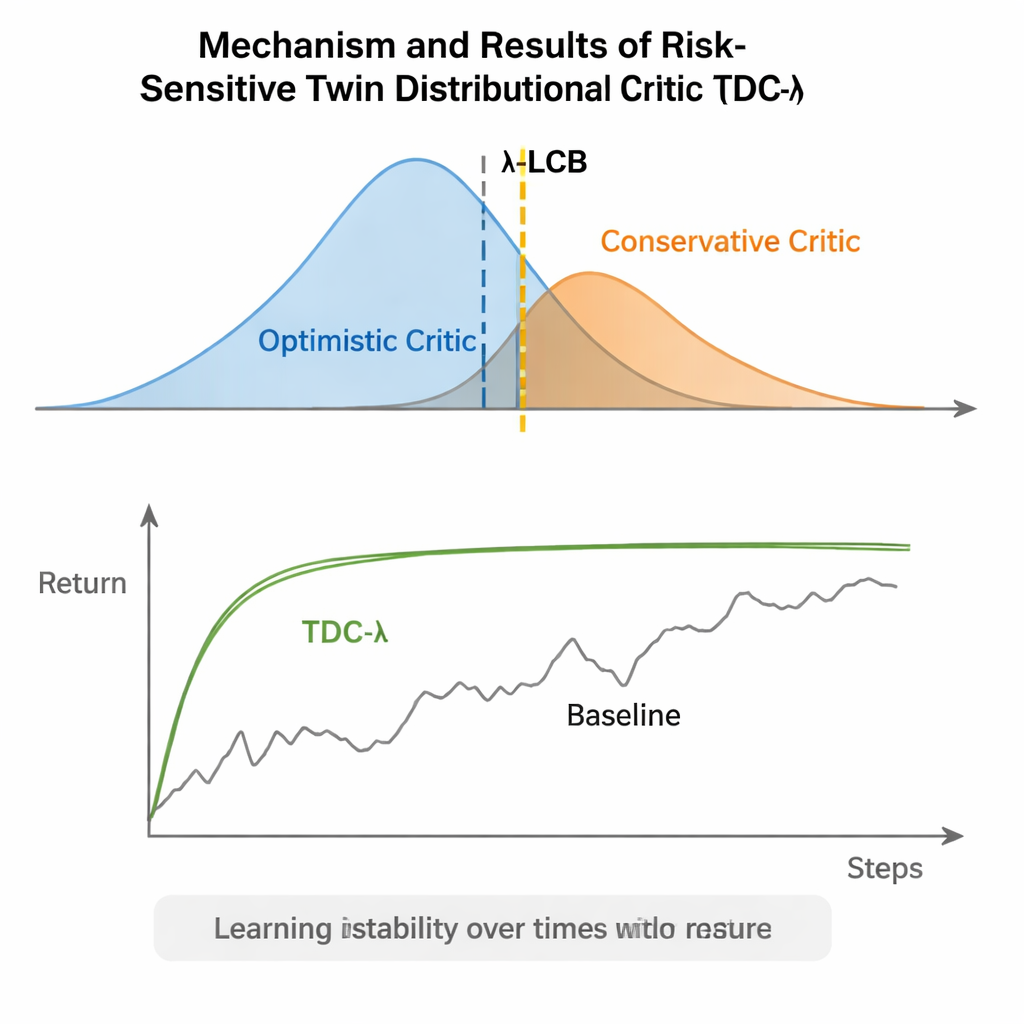
Ein einfacher Drehknopf für sicheres Lernen
Alltäglich formuliert gibt TDC-λ Reinforcement‑Learning‑Systemen eine „Sicherheitsmarge“, wenn es darum geht, wie sehr sie ihrem eigenen Optimismus vertrauen. Indem es vollständige Verteilungen möglicher Ergebnisse lernt und dann mit dem λ‑Regler den sichereren Kritiker bevorzugt, reduziert der Algorithmus starke Schwankungen im Training und bewahrt zugleich hohe Endleistung. Für Anwender bietet das einen praktischen Weg, zuverlässigere Steuerungen für Roboter und andere Systeme mit kontinuierlicher Steuerung zu bauen: Man beginnt mit einem moderat konservativen λ und passt ihn je nach Volatilität des Lernprozesses an. Die übergeordnete Botschaft lautet, dass die sorgfältige Gestaltung dessen, woraus der Agent lernt — seine Trainingsziele — viel der Robustheit liefern kann, die sonst komplexeren Architekturen zugeschrieben wird, und damit fortgeschrittenes Reinforcement Learning stabiler und zugänglicher macht.
Zitation: Osman, O., Yalcin Kavus, B., Karaca, T.K. et al. Risk sensitive twin distributional critics with a lambda lower confidence bound for continuous control reinforcement learning. Sci Rep 16, 6699 (2026). https://doi.org/10.1038/s41598-026-37910-3
Schlüsselwörter: reinforcement learning, kontinuierliche Steuerung, risikoempfindliches Lernen, distributionale Kritiker, Robotik