Clear Sky Science · de
Luftqualitätsprognosemodell auf Grundlage eines hybriden Deep‑Learning‑Rahmens
Warum sauberere Luftprognosen für Sie wichtig sind
Wenn Smog eine Stadt einhüllt, müssen Menschen plötzlich praktische Entscheidungen treffen: Ist es sicher, draußen zu joggen, Kinder zur Schule zu schicken oder Fabriken weiterlaufen zu lassen? Diese Entscheidungen hängen davon ab, wie gut wir winzige Schadstoffpartikel namens PM2.5 vorhersagen können, die klein genug sind, um tief in die Lungen einzudringen. Diese Studie stellt ein neues Computermodell vor, das aktuelle Fortschritte in der künstlichen Intelligenz nutzt, um PM2.5‑Werte in chinesischen Städten genauer und schneller vorherzusagen als viele bestehende Werkzeuge und so der Öffentlichkeit und politischen Entscheidungsträgern früher und verlässlicher Warnungen liefern könnte.
Von verrauchten Himmeln zu intelligenten Daten
Luftverschmutzung ist in vielen urbanen Gebieten zu einer anhaltenden Bedrohung für die Gesundheit geworden, besonders in Nordchina, wo hohe PM2.5‑Werte mit Atemwegs‑ und Herz-Kreislauf‑Erkrankungen in Verbindung stehen. Städte betreiben heute dichte Netzwerke von Messstationen, die stündlich PM2.5, andere Schadstoffe und das lokale Wetter erfassen. Traditionelle Vorhersagemethoden stützen sich auf vereinfachte Mathematik oder manuell entwickelte physikalische Modelle, die mit der chaotischen, nichtlinearen Realität von wirbelnden Winden, Temperaturwechseln und menschlicher Aktivität schwer zurechtkommen. Im Gegensatz dazu lässt der neue Ansatz, CBLA genannt, die Daten „für sich sprechen“, indem moderne neuronale Netze mit mehreren Jahren an Beobachtungsdaten aus Peking und Guangzhou trainiert werden.
Wie die neue Vorhersage‑Engine funktioniert
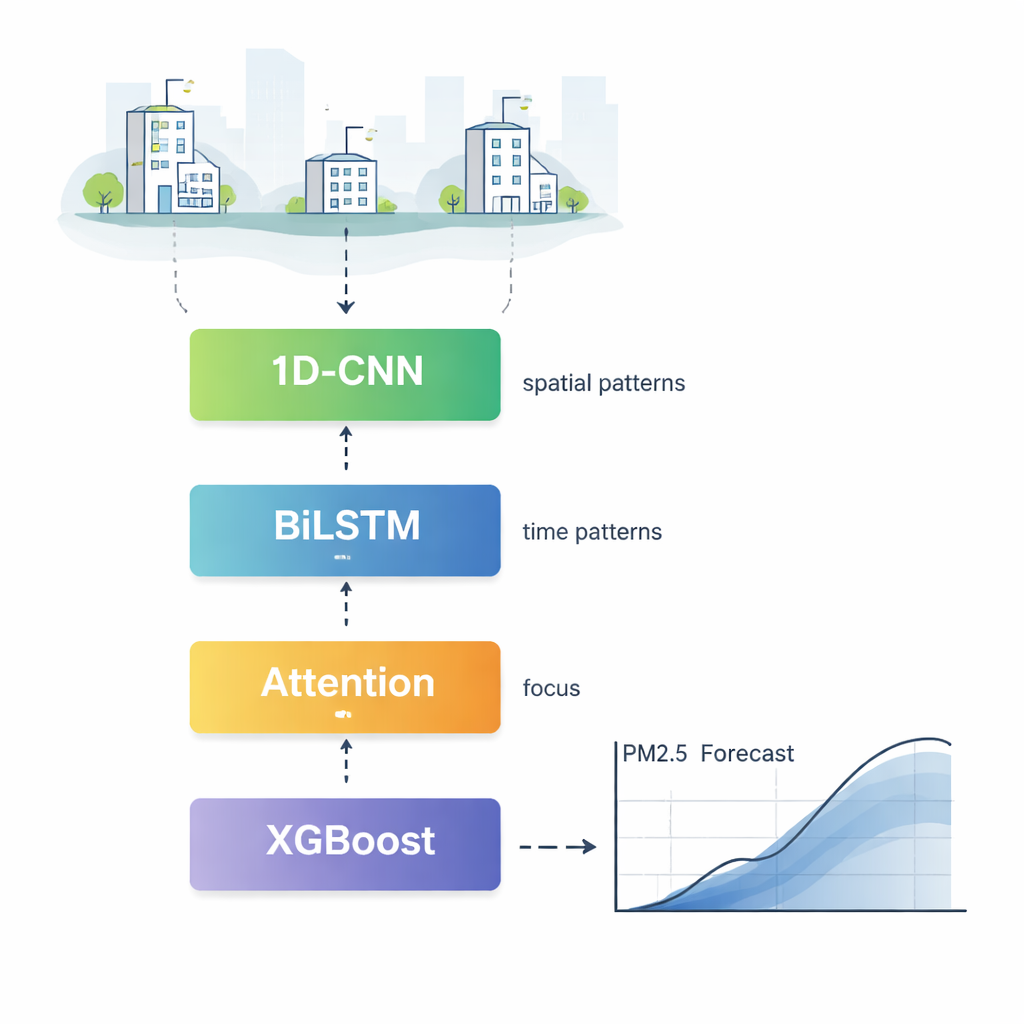
CBLA arbeitet wie ein geschichtetes Team von Spezialisten, das Verschmutzungsdaten aus verschiedenen Blickwinkeln analysiert, bevor es über eine endgültige Prognose abstimmt. Zuerst durchsucht eine Komponente, bekannt als eindimensionales Faltungsnetzwerk, Messungen von vielen Stationen, um räumlich wiederkehrende Muster zu erkennen — etwa wie Rauch sich tendenziell von einem Stadtteil zum nächsten ausbreitet. Danach liest ein bidirektionales Gedächtnisnetzwerk die Verschmutzungshistorie vorwärts und rückwärts in der Zeit und lernt, wie die heutigen Werte sowohl von kürzeren als auch etwas älteren Bedingungen abhängen. Ein Aufmerksamkeitsmechanismus hebt anschließend die einflussreichsten Stunden und Merkmale hervor, sodass das Modell sich stärker auf etwa den starken Anstieg gestern und heftigen Wind konzentriert statt auf weit zurückliegende, weniger relevante Messwerte.
Wetterdaten einbeziehen, um das Bild zu schärfen
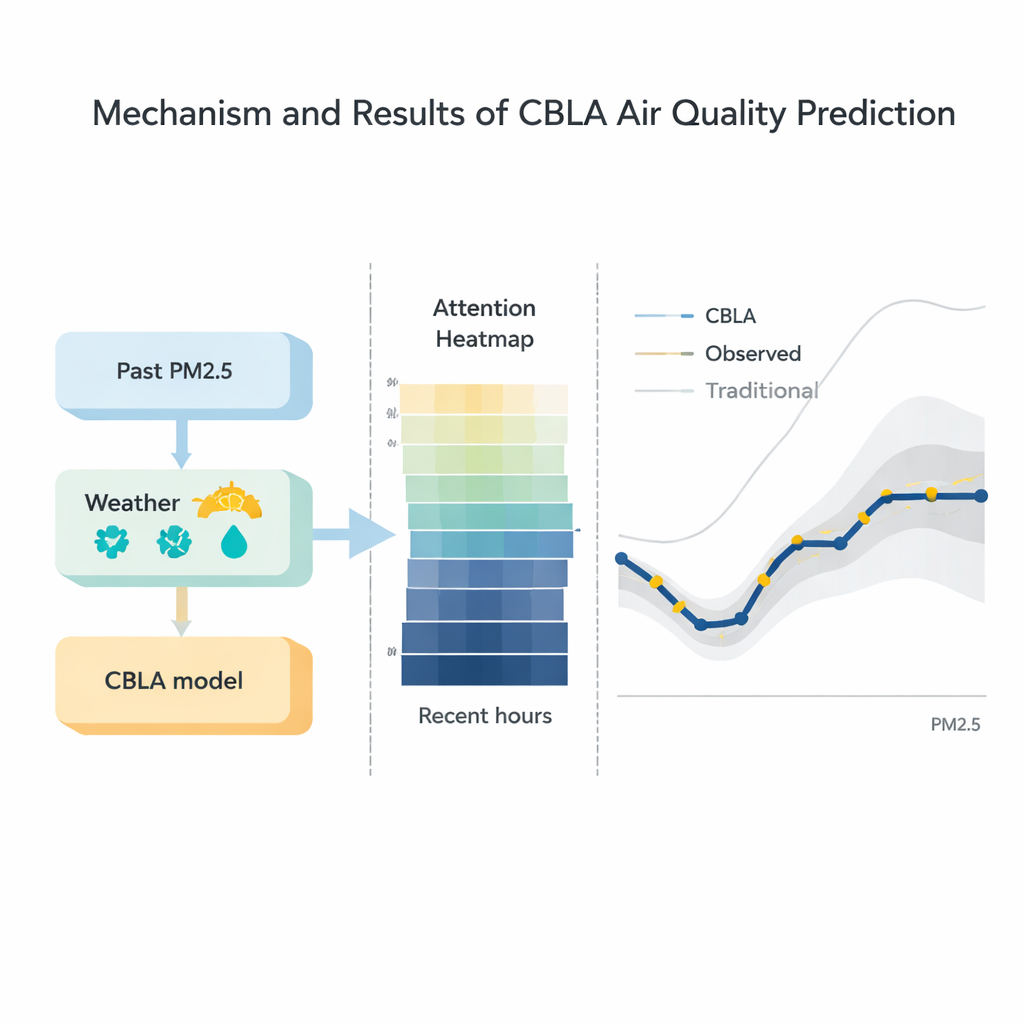
Verschmutzung bewegt sich nicht isoliert; sie wird vom wechselnden Wetter getragen. Um diese Information sauber einzubeziehen, fügen die Autorinnen und Autoren eine zweite Stufe hinzu, die sowohl die vorläufige neuronale Netzvorhersage als auch detaillierte meteorologische Daten — wie Windgeschwindigkeit, Luftfeuchtigkeit und Temperatur — in einen leistungsfähigen baumbasierten Algorithmus namens XGBoost einspeist. Diese Stufe wirkt wie ein erfahrener Meteorologe, der die erste Schätzung gegen das aktuelle Wetter abgleicht und die Prognose nach oben oder unten korrigiert. Tests zeigen, dass diese Kombination typische Vorhersagefehler reduziert und die Übereinstimmung der Modellwerte mit realen Messungen verbessert, besonders während plötzlicher Belastungsanstiege und Reinigungsereignisse.
Test gegen konkurrierende Modelle
Die Forschenden verglichen CBLA mit einer breiten Palette von Alternativen, von klassischen Techniken wie Regression und ARIMA‑Zeitreihenmodellen bis hin zu ausgefeilten Deep‑Learning‑Hybriden, die Graph‑Netzwerke und Transformer kombinieren. Über drei reale Datensätze hinweg erzielte CBLA durchgängig den niedrigsten durchschnittlichen Fehler und die engste Anpassung an beobachtete PM2.5‑Werte. Wichtig ist, dass es eine Genauigkeit erreichte, die mit einigen der fortschrittlichsten modernen Modelle vergleichbar ist, dabei aber nur etwa ein Drittel ihrer Trainingszeit auf Standardhardware benötigt. Visualisierungen des Aufmerksamkeitsmechanismus zeigten, dass das Modell natürlicherweise den jüngsten Stunden und physikalisch sinnvollen Faktoren wie Windgeschwindigkeit und vergangenen PM2.5‑Werten das größte Gewicht gibt, was Einblicke darin bietet, wie seine Entscheidungen mit meteorologischer Intuition übereinstimmen.
Was das für den Alltag bedeutet
Praktisch zeigt die Studie, dass die sorgfältige Kombination mehrerer KI‑Techniken ein Prognosewerkzeug für Luftverschmutzung hervorbringen kann, das nicht nur genauer, sondern auch schneller und leichter interpretierbar ist. Stadtverwaltungen könnten ein solches Modell nutzen, um Gesundheitswarnungen auszulösen, Verkehrsregelungen anzupassen oder industrielle Aktivitätszeiten präventiv zu reduzieren, noch bevor gefährliche Smogspitzen auftreten. Für Bewohnerinnen und Bewohner bedeuten bessere Prognosen klarere Hinweise darauf, wann Masken getragen, Luftreiniger betrieben oder Kinder drinnen behalten werden sollten. Obwohl die Arbeit auf chinesische Städte und PM2.5 fokussiert ist, könnte derselbe Rahmen an andere Regionen und Schadstoffe angepasst werden und weist auf eine Zukunft hin, in der datengetriebene Vorhersagen Millionen Menschen helfen, etwas leichter zu atmen.
Zitation: Yin, C., Li, W., Li, T. et al. Air quality prediction model based on deep learning hybrid framework. Sci Rep 16, 7084 (2026). https://doi.org/10.1038/s41598-026-37896-y
Schlüsselwörter: Luftqualitätsprognose, PM2.5, Deep Learning, städtische Verschmutzung, Meteorologie