Clear Sky Science · de
Effiziente Erkennung von Eindringlingen im TON-IoT-Datensatz mittels hybridem Feature-Selection-Ansatz
Warum der Schutz intelligenter Geräte wichtig ist
Milliarden alltäglicher Geräte – von Überwachungskameras zu Hause bis zu Sensoren in Fabriken – kommunizieren inzwischen über das Internet und bilden das, was wir Internet der Dinge (IoT) nennen. Diese Vernetzung bringt zwar Komfort und Effizienz, öffnet aber auch neue Türen für Angreifer. Die hier zusammengefasste Studie behandelt eine einfache, aber zentrale Frage: Wie lassen sich Angriffe in diesen weitreichenden Gerät-Netzwerken zuverlässig erkennen, ohne auf schwerfällige, energieintensive Sicherheitssoftware angewiesen zu sein?
Die Herausforderung, digitale Einbrüche zu erkennen
Um Angriffe auf IoT-Systeme zu untersuchen, greifen Forscher häufig auf große, öffentliche Datensätze zurück, die den Netzwerkverkehr während normaler Operation und während Cyberangriffen aufzeichnen. Einer der am weitesten verbreiteten ist der ToN-IoT-Datensatz, der realen Verkehr aus einem realistischen industriellen Testfeld erfasst und viele Angriffsarten wie Denial-of-Service, Ransomware, Passwortknacken und Man-in-the-Middle-Spionage enthält. Die Autoren zeigen jedoch, dass dieser Datensatz eine versteckte Falle hat: Viele Angriffe wurden von festen IP-Adress- und Portbereichen aus gestartet. Das bedeutet, ein Modell kann „schummeln“, indem es lernt, wer der Angreifer ist, statt welches Verhalten bösartig ist. Solche Modelle erzielen im Labor hohe Werte, versagen jedoch, wenn ein Angreifer von einer neuen Adresse kommt.
Vom umfangreichen Datensatz zu einer schlanken Verhaltenssicht
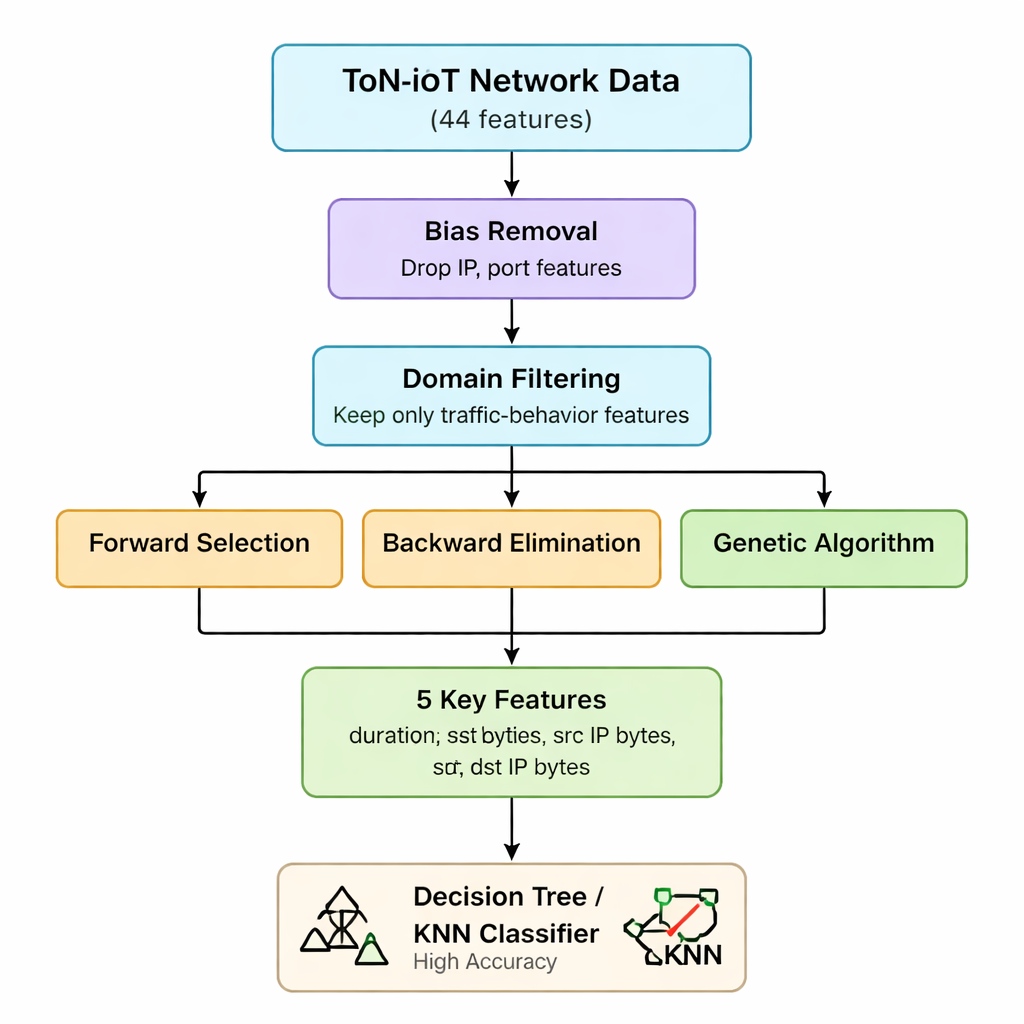
Die ursprünglichen ToN-IoT-Netzdaten enthalten 44 verschiedene Messgrößen für jede Verbindung, von IP-Informationen bis hin zu Details zu Web- und verschlüsseltem Verkehr. Alle zu verarbeiten erhöht Rechenzeit und Speicherbedarf, was für kleine IoT-Gateways und Edge-Geräte problematisch ist. Die Autoren nutzen zunächst ihr Verständnis der Angriffsmuster, um Merkmale zu entfernen, die verzerrt sind (wie IP-Adressen und Portnummern) oder wenig zur Unterscheidung von Angriffen beitragen. Ihrer Argumentation nach zeigen sich die meisten IoT-Bedrohungen letztlich als ungewöhnliche Muster in der Anzahl der gesendeten und empfangenen Pakete und Bytes sowie in der Verbindungsdauer – unabhängig davon, wer mit wem kommuniziert. Diese erste Stufe reduziert die Merkmalsmenge von 44 auf sieben Kernstatistiken des Verkehrs, die Volumen und Dauer betreffen.
Hybride Merkmalsauswahl: drei Blickwinkel auf dieselben Daten
Als Nächstes wendet das Team drei verschiedene „Wrapper“-Methoden an, die wiederholt ein Modell trainieren, während sie Merkmale hinzufügen, entfernen oder neu kombinieren, um zu sehen, welches Teilsatz wirklich am wichtigsten ist. Forward Selection baut aus einer leeren Menge auf und behält ein Merkmal nur, wenn es die Genauigkeit steigert. Backward Elimination beginnt mit allen sieben Merkmalen und entfernt solche, deren Wegfall die Genauigkeit nicht verschlechtert. Ein genetischer Algorithmus untersucht viele Kombinationen parallel und entwickelt über Generationen bessere Teilmengen. Alle drei Methoden werden mit einem einfachen Entscheidungsbaum-Klassifikator getestet, wobei Genauigkeit als Maßstab dient. Durch die Schnittmenge der Ergebnisse gelangen die Autoren zu einem stabilen Kern von fünf Merkmalen: Verbindungsdauer, gesendete Bytes, empfangene Bytes und die entsprechenden IP-Ebene-Byte-Zählungen. Diese fünf Variablen erfassen effektiv anomale Spitzen oder Ungleichgewichte im Verkehr, die viele Angriffstypen signalisieren.
Leichte Modelle mit starker Leistung
Mit diesem geschlankten, verhaltensorientierten Datensatz bewerten die Forscher, wie gut einfache Modelle des maschinellen Lernens sicheren Verkehr von Angriffen unterscheiden können. Mit nur den fünf ausgewählten Merkmalen erreicht ein Entscheidungsbaum 98,6 % Genauigkeit bei der einfachen Klassifikation „Angriff vs. normal“ und 97,2 % Genauigkeit bei der Unterscheidung mehrerer Angriffskategorien. Ein k-Nearest-Neighbor-Modell schneidet ähnlich ab, und komplexere Ensemble-Methoden wie Random Forests oder Gradient Boosting bringen nur geringe Verbesserungen, verlangen dafür aber mehr Rechenleistung und Speicher. Wichtig ist, dass die Autoren durch statistische Tests bestätigen, dass ihre gewählten Merkmale tatsächlich informativ sind und nicht bloße Artefakte der Datenerhebung. Sie vermerken jedoch, dass subtile Man-in-the-Middle-Angriffe – die darauf ausgelegt sind, sich in normale Datenströme einzufügen – weiterhin schwerer zu erkennen sind, was darauf hindeutet, dass künftige Arbeiten reichere Protokoll- oder Timing-Informationen benötigen könnten.
Was das für die Praxis bedeutet
Für Nicht-Expertinnen und Nicht-Experten ist die Kernbotschaft: Man braucht nicht immer riesige Modelle oder Dutzende technischer Messgrößen, um IoT-Systeme zu schützen. Indem man Hinweise entfernt, die nur in einem bestimmten Labor-Setup funktionieren, und stattdessen auf wenige Verkehrsverhaltensweisen fokussiert, zeigen die Autoren, dass einfache, schnelle Algorithmen die meisten Angriffe mit hoher Zuverlässigkeit erkennen können. Ihre fünfmerkmalige Version des ToN-IoT-Datensatzes ist auf ressourcenbeschränkten Edge-Geräten leichter zu verarbeiten, was sie praktikabel für Router, Gateways und kleine Hubs macht, die in Echtzeit auf Bedrohungen reagieren müssen. Kurz gesagt schlägt die Studie einen Weg zu vertrauenswürdigeren und einsatzfähigeren Systemen zur Eindringungserkennung für die alltäglichen Smart-Geräte vor, die uns zunehmend umgeben.
Zitation: Dharini, N., Janani, V.S. & Katiravan, J. Efficient detection of intrusions in TON-IoT dataset using hybrid feature selection approach. Sci Rep 16, 7763 (2026). https://doi.org/10.1038/s41598-026-37834-y
Schlüsselwörter: IoT-Sicherheit, Eindringungserkennung, maschinelles Lernen, Merkmalsauswahl, Netzwerkverkehr