Clear Sky Science · de
Modellierung und Anwendung der Vorhersage komplexer Alzheimer-Krankheitsmerkmale basierend auf Multi-Task-Learning
Warum diese Forschung für Familien und Patient:innen wichtig ist
Die Alzheimer-Krankheit gehört zu den gefürchtetsten Diagnosen unserer Zeit, dennoch tun sich Ärztinnen und Ärzte weiterhin schwer damit, vorherzusagen, wer rasch verschlechtert, wer über Jahre stabil bleibt und welche frühen Anzeichen wirklich relevant sind. Diese Studie stellt eine einfache, aber wirkungsvolle Frage: Wenn wir mehrere Alzheimer-bezogene Testergebnisse und Hirnscans gemeinsam betrachten und sie mit den genetischen Daten einer Person kombinieren, kann moderne künstliche Intelligenz dann Muster lernen, die uns helfen, den Verlauf der Erkrankung genauer vorherzusagen?
Viele Gesichter derselben Krankheit
Alzheimer bedeutet nicht nur Gedächtnisverlust. Patient:innen unterscheiden sich darin, wie sie bei kognitiven Tests abschneiden, wie gut sie Alltagsaufgaben bewältigen und wie ihre Hirnscans aussehen. Diese verschiedenen Messwerte – etwa gängige Gedächtnis- und Denkskalen, Fragebögen zur Alltagsfunktion und PET-Scans des Gehirnstoffwechsels oder der Amyloid-Ablagerung – werden teilweise genetisch beeinflusst. Wichtig ist: Sie teilen auch zum Teil dieselben genetischen Grundlagen. Traditionelle Vorhersagemethoden betrachten meist ein Merkmal nach dem anderen und verschenken damit die nützliche Information, dass diese Merkmale zusammenhängen. Die Autor:innen argumentieren, dass Modelle, ähnlich einer Ärztin, die das Gesamtbild sieht statt nur einen Einzelwert, von mehreren Merkmalen gleichzeitig lernen sollten.
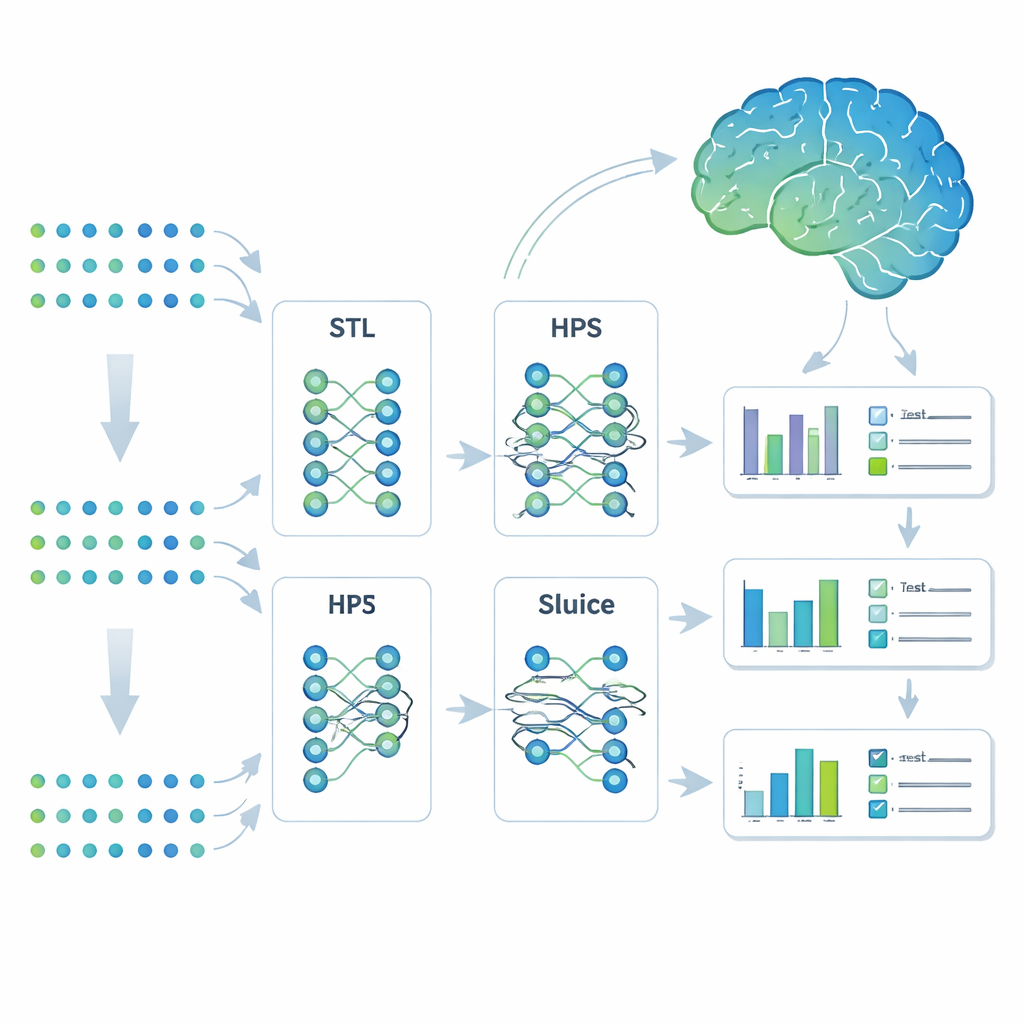
Einem Modell beibringen, viele verwandte Aufgaben zu lernen
Die Forscher:innen griffen auf eine maschinelle Lernstrategie namens Multi-Task-Learning zurück. Statt für jedes Ergebnis separate Modelle zu bauen, trainierten sie ein einziges System, um sieben Alzheimer-bezogene Merkmale gleichzeitig vorherzusagen. Sie verglichen vier Ansätze: vollständig getrennte Modelle (Single-Task-Learning), ein einfaches geteiltes Modell, das erst am Ende auftrennt (Hard Parameter Sharing), ein flexibleres verzweigtes Design, das Aufgaben in Untergruppen aufteilen kann, und ein hoch anpassbares Design namens Sluice Network, das feinjustieren kann, wie viel Information auf jeder Netzwerkschicht geteilt wird. Allen vier Modellen wurden dieselben genetischen Eingaben präsentiert; der Unterschied lag darin, wie sie das Gelernte über die Merkmale hinweg teilten.
Ideen in simulierten Genomen testen
Bevor man einem Modell bei echten Patient:innen vertraut, baute das Team detaillierte Simulationen unter Verwendung realer genetischer Muster aus der Alzheimer’s Disease Neuroimaging Initiative (ADNI), allerdings mit vollständig kontrollierbaren Ausgängen. Sie erstellten Szenarien, in denen alle Merkmale dieselben genetischen Ursachen teilten, in denen Merkmale überlappende Gruppen bildeten, und in denen jedes Merkmal eigene Ursachen hatte. Sie variierten außerdem die Stärke der genetischen Signale und den hinzugefügten Rauschanteil, um die unordentliche Realität menschlicher Daten nachzuahmen. Unter nahezu allen Bedingungen lieferte das Sluice Network die genauesten Vorhersagen und blieb stabil, selbst wenn die Merkmale nur schwach verwandt waren. Einfachere geteilte Modelle funktionierten gut, wenn Merkmale viele genetische Faktoren gemeinsam hatten, brachen jedoch ein, wenn diese gemeinsame Grundlage gering war, während vollständig getrennte Modelle zwar robust, insgesamt aber weniger genau waren.
Echtdaten und die Kraft der Gruppierung von Genen
Die Autor:innen wandten die Modelle anschließend auf reale ADNI-Daten von 463 Personen an und verwendeten fast 3.800 genetische Marker aus 56 Genen, die zuvor mit Alzheimer in Verbindung gebracht worden waren. Hier ergänzten sie den Ansatz um eine biologisch inspirierte Idee: Statt Tausende einzelner genetischer Marker direkt einzuspeisen, gruppierten sie zunächst Marker nach Genen und ließen das Netzwerk ein kompaktes "Zusammenfassungs"-Signal für jedes Gen lernen, bevor es die sieben Ergebnisse vorhersagte. Diese Aggregation auf Genebene steigerte die Leistung für die meisten Modelle, besonders für das Sluice Network, das seine durchschnittliche Korrelation mit den realen Ergebnissen etwa verdoppelte. Die Zuwächse zeigten sich am deutlichsten bei PET-Bildgebungsmaßen und bestimmten kognitiven sowie funktionellen Scores, was darauf hindeutet, dass subtile genetische Effekte besser erkennbar werden, wenn sie auf Genebene zusammengefasst statt als isolierte Marker behandelt werden.
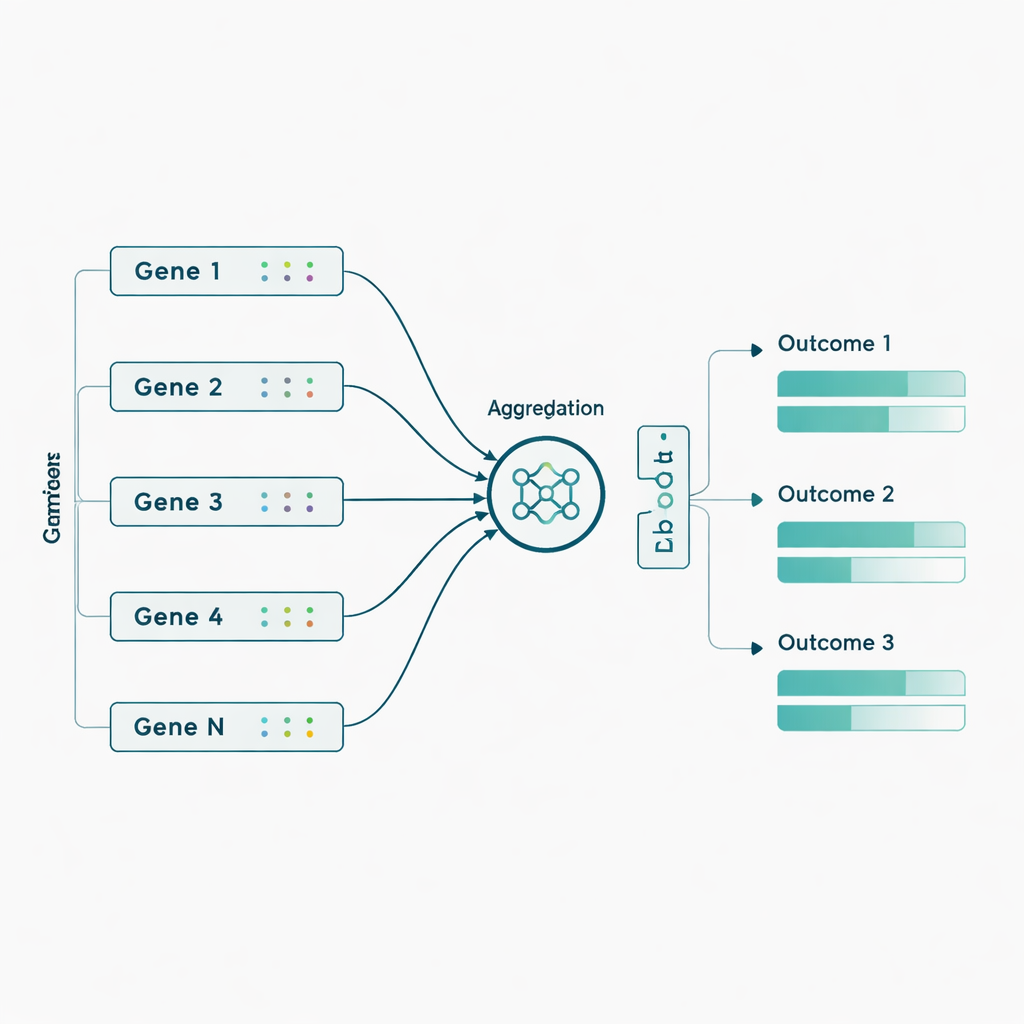
Was das für künftige Vorhersage und Versorgung bedeutet
Für Nicht-Spezialist:innen lautet die Botschaft: Intelligentere, flexiblere KI-Modelle können aus denselben genetischen und klinischen Daten mehr Erkenntnis gewinnen, indem sie aus mehreren verwandten Ergebnissen zugleich lernen und die biologische Organisation in Genen berücksichtigen. Zwar sind die aktuellen Verbesserungen moderat und noch weit von einem klinischen Test entfernt, doch weist der Ansatz in Richtung zuverlässigerer Instrumente zur Abschätzung eines individuellen Risikoprofils, zur Nachverfolgung wahrscheinlicher Verläufe und möglicherweise zur Anpassung von Monitoring oder Interventionen. Bei komplexen Erkrankungen wie Alzheimer, in denen viele kleine genetische Effekte interagieren, könnten Methoden, die Informationen über Merkmale teilen und schwache Signale aggregieren, ein klareres, informativeres Bild liefern als traditionelle Einzelmerkmal-Ansätze.
Zitation: Zhou, W., Xue, Z., Liang, J. et al. Modeling and application of alzheimer’s disease complex trait prediction based on multi-task learning. Sci Rep 16, 7749 (2026). https://doi.org/10.1038/s41598-026-37820-4
Schlüsselwörter: Genetik der Alzheimer-Krankheit, Multi-Task-Learning, Tiefenlernvorhersage, neuroimaging-Biomarker, Aggregation auf Genebene