Clear Sky Science · de
Eine vergleichende Analyse der Leistung großer Sprachmodelle bei der Fachprüfung Zahnmedizin
Warum intelligente Chatbots für angehende Zahnärzte wichtig sind
Künstliche Intelligenz verändert rasch, wie Ärztinnen, Ärzte und Zahnärztinnen lernen und arbeiten. Eines der sichtbarsten Werkzeuge sind konversationsfähige Chatbots, die von großen Sprachmodellen angetrieben werden — dieselbe Technologie, die vielen populären KI-Assistenten zugrunde liegt. Diese Studie stellte eine einfache, aber wichtige Frage: Wenn Zahnmedizinstudierende diese Werkzeuge zur Vorbereitung auf eine hochkompetitive Fachprüfung in der oralen und kraniofazialen Radiologie nutzten, wie gut würden die Maschinen in der Praxis tatsächlich abschneiden?
KI im realen Prüfungstest
Um das zu untersuchen, nutzten die Forschenden die Facharztaufnahmeprüfung für Zahnmedizin (DUS) in der Türkei, die mitbestimmt, wer in weiterführende Ausbildungsprogramme aufgenommen wird. Aus früheren Jahren dieses landesweiten Tests wählten sie 208 Multiple-Choice-Fragen aus, die Themen abdecken, die Radiologie-Spezialistinnen und -Spezialisten beherrschen müssen — von Strahlungsphysik und Bildgebungstechniken bis hin zu Kiefertumoren und Nasennebenhöhlenerkrankungen. Die meisten Fragen waren nur Text, doch ein kleinerer Teil erforderte die Interpretation radiographischer Bilder, was die diagnostische Praxis realistisch widerspiegelt.
Sieben Chatbots stellen sich der gleichen Herausforderung
Das Team stellte anschließend jede Frage auf Türkisch sieben weit verbreiteten KI-Chatbots, die auf unterschiedlichen großen Sprachmodellen basieren: zwei Versionen von ChatGPT sowie Gemini, Copilot, DeepSeek, Claude und Grok. Jede Frage wurde sorgfältig und getrennt eingegeben, um Überträge zwischen den Konversationen zu vermeiden. Ein zweiter Forscher verglich jede KI-Antwort mit dem offiziellen Antwortschlüssel und bewertete sie als richtig oder falsch. Abschließend nutzten die Autorinnen und Autoren gängige statistische Tests, um die Modelle insgesamt und innerhalb spezifischer Themenbereiche zu vergleichen.
Wer am höchsten punktete — und wo sie strauchelten
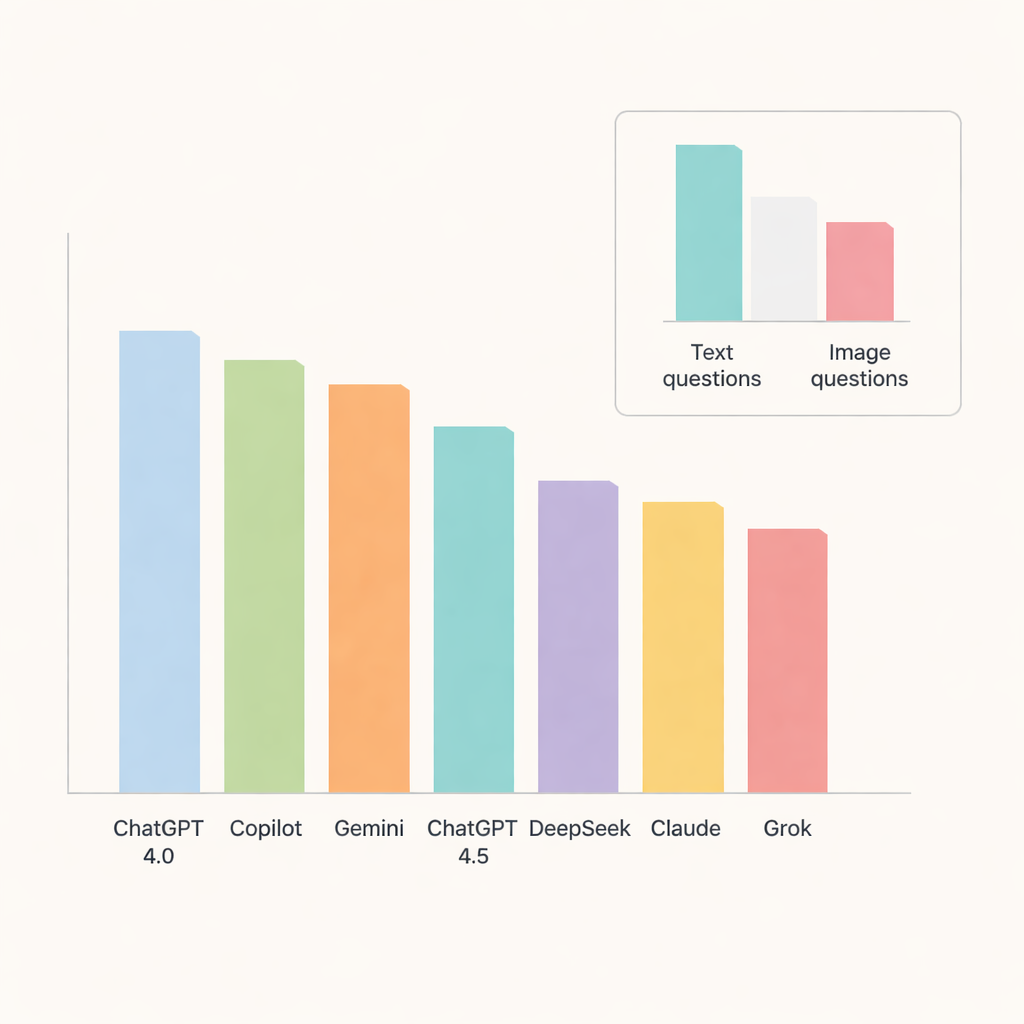
Unter allen Chatbots stach ChatGPT 4.0 hervor und beantwortete etwa 91 Prozent der Fragen korrekt. Copilot und Gemini folgten dichtauf mit Genauigkeitswerten im mittleren bis hohen 80-Prozent-Bereich, während ChatGPT 4.5, DeepSeek, Claude und Grok etwas zurückblieben. Bei der thematischen Analyse schnitten die Modelle besonders gut in oraler Pathologie und Erkrankungen der Speicheldrüsen ab, wo die Genauigkeit etwa 90 Prozent erreichte oder übertraf. Im Gegensatz dazu erwiesen sich radiographische Anatomie und Weichteilverkalkungen als deutlich schwieriger, was die Werte in mehreren Bereichen nach unten zog und darauf hindeutet, dass KI bei feinen Detailfragen noch Schwächen hat.
Bilder bleiben schwerer als Worte
Ein zentraler Test war, ob die Chatbots Bilder genauso gut verarbeiten können wie Text. Hier traten ihre Einschränkungen deutlich zutage. Die Genauigkeit sank bei bildbasierten Fragen deutlich, selbst bei den bestleistenden Modellen. ChatGPT 4.0, Gemini und Copilot führten in dieser Kategorie, beantworteten jedoch nur etwa zwei Drittel der visuellen Fragen korrekt. DeepSeek erzielte bei Bildern das schlechteste Ergebnis mit etwas über einem Drittel richtiger Antworten. Bei den meisten Modellen war der Unterschied zwischen Text- und Bildleistung groß genug, um statistisch bedeutsam zu sein, was unterstreicht, dass die Interpretation medizinischer Bilder für heutige breit einsetzbare KI weiterhin eine Herausforderung darstellt.
Was das für Studierende und Patientinnen bedeutet
Die Quintessenz der Studie ist, dass moderne Chatbots mächtige Helfer in der zahnmedizinischen Ausbildung sein können, besonders beim Wiederholen von Fakten und beim Üben prüfungsartiger Fragen in der Radiologie. Dennoch machen selbst die stärksten Systeme genügend Fehler — insbesondere in visuell anspruchsvollen oder sehr spezifischen Themengebieten — als dass sie die Expertise von Fachleuten sicher ersetzen könnten. Für Studierende und Klinikerinnen sind diese Werkzeuge am ehesten als kluge Lernpartner oder Entscheidungsunterstützer zu sehen, nicht als unabhängige Autoritäten. Bei angemessener Vorsicht und Aufsicht können sie das Lernen beschleunigen und den Zugang zu hochwertigen Erklärungen erweitern, während die letzte Verantwortung für Diagnose und Behandlung fest bei den ausgebildeten Fachkräften bleibt.
Zitation: Geduk, G., Hasırcı, U.C., Kusay, D.D. et al. A comparative analysis of the performance of large Language models in the dentistry specialty examination. Sci Rep 16, 6739 (2026). https://doi.org/10.1038/s41598-026-37800-8
Schlüsselwörter: zahnmedizinische Ausbildung, künstliche Intelligenz, große Sprachmodelle, orale und kraniofaziale Radiologie, medizinische Prüfungen