Clear Sky Science · de
Sprachübergreifende SMS-Spam-Erkennung mit GAN-basierter Augmentierung für unausgewogene Datensätze
Warum Ihre Textnachrichten weiterhin Schutz benötigen
Die meisten von uns gehen davon aus, dass unerwünschte Nachrichten leise in einem Spam-Ordner landen, doch hinter den Kulissen ist das ein sehr schwieriges Problem. Echte Spam-Nachrichten sind im Vergleich zu Alltagsnachrichten selten und treten zunehmend gleichzeitig in mehreren Sprachen auf. Dieses Papier stellt eine neue Methode vor, gefährlichen SMS-Spam zu erkennen, indem leistungsfähige Sprachmodelle mit einem cleveren „Fake-Daten“-Generator kombiniert werden, sodass Filter aus deutlich mehr Beispielen schädlicher Nachrichten lernen können, ohne Ihre Privatsphäre zu gefährden.
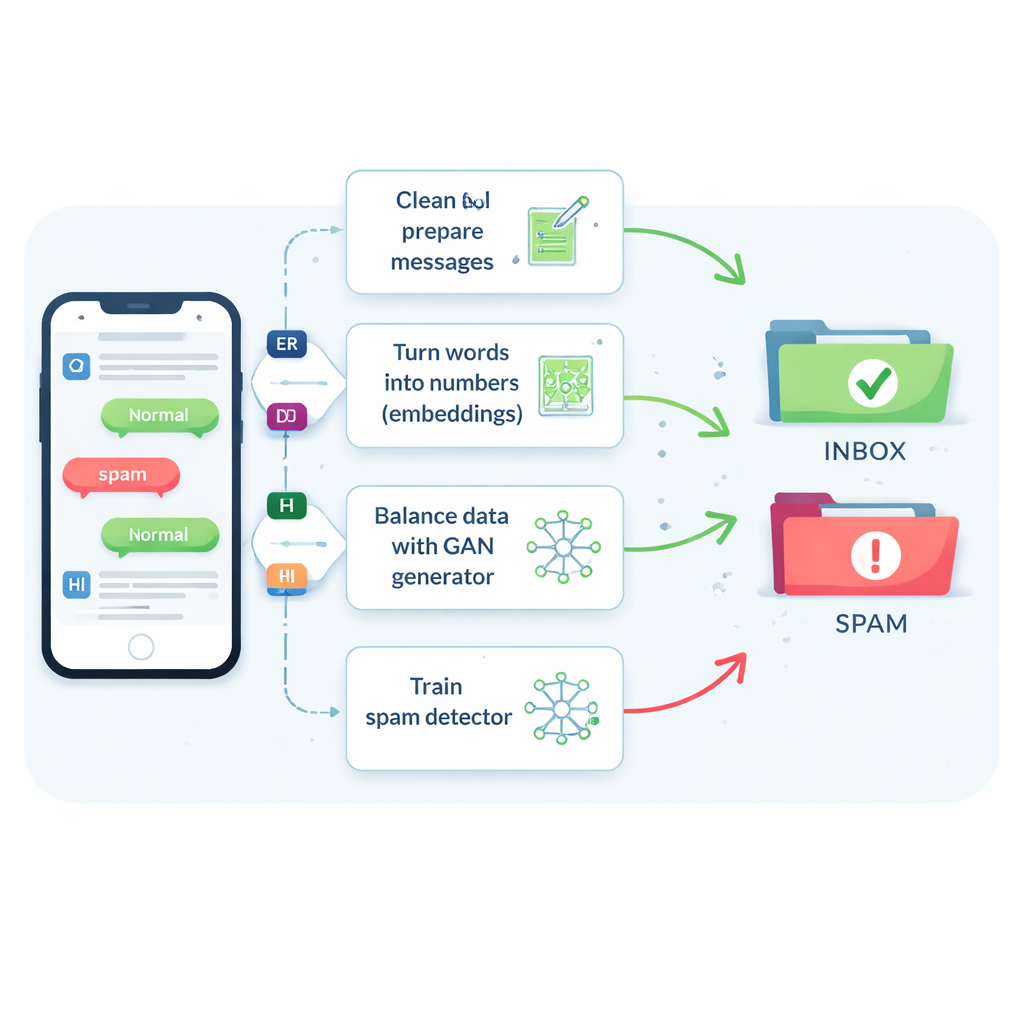
Das Problem seltener und formwandelnder Spam-Nachrichten
Spam-SMS machen nur etwa eine von sieben Nachrichten aus, doch schon das Verpassen eines kleinen Anteils kann Menschen Betrugsmaschen, Malware und Identitätsdiebstahl aussetzen. Traditionelle Filter haben Schwierigkeiten, weil SMS kurz sind, voller Umgangssprache und Abkürzungen stecken und in Echtzeit mit wenig zusätzlichem Kontext eintreffen. Deshalb tendieren viele Systeme dazu, Nachrichten als sicher einzustufen, was die Nutzer zufriedenstellt, aber schädliche Nachrichten durchlässt. Ältere Tricks, die Spam-Nachrichten einfach duplizieren oder neue durch Wortveränderungen erfinden, helfen zwar etwas, verwirren den Filter jedoch oft oder erzeugen unrealistische Beispiele, die nicht dem entsprechen, was Kriminelle tatsächlich verschicken.
Maschinen beibringen, die Bedeutung von Nachrichten zu erfassen
Die Autoren beginnen mit dem Vergleich von acht Lernalgorithmen, von bekannten Werkzeugen wie Support Vector Machines und Entscheidungsbäumen bis hin zu fortgeschritteneren neuronalen Netzen, die Text als Sequenz lesen, etwa Long Short-Term Memory (LSTM)-Netzwerke. Sie testen außerdem fünf Methoden, Wörter in für Computer nutzbare Zahlen zu verwandeln. Einfache Zählungen, wie oft jedes Wort vorkommt (bekannt als Bag-of-Words oder TF–IDF), sind schnell, aber blind gegenüber Bedeutung. Neuere „Embeddings“ wie Word2Vec und GloVe platzieren Wörter mit ähnlicher Bedeutung nahe beieinander in einem numerischen Raum. Am ausgefeiltesten sind transformerbasierte Modelle wie BERT, die die Darstellung eines Wortes abhängig vom umgebenden Satz anpassen und dem System helfen, zum Beispiel eine freundliche Erinnerung von einem überzeugenden Betrug zu unterscheiden.
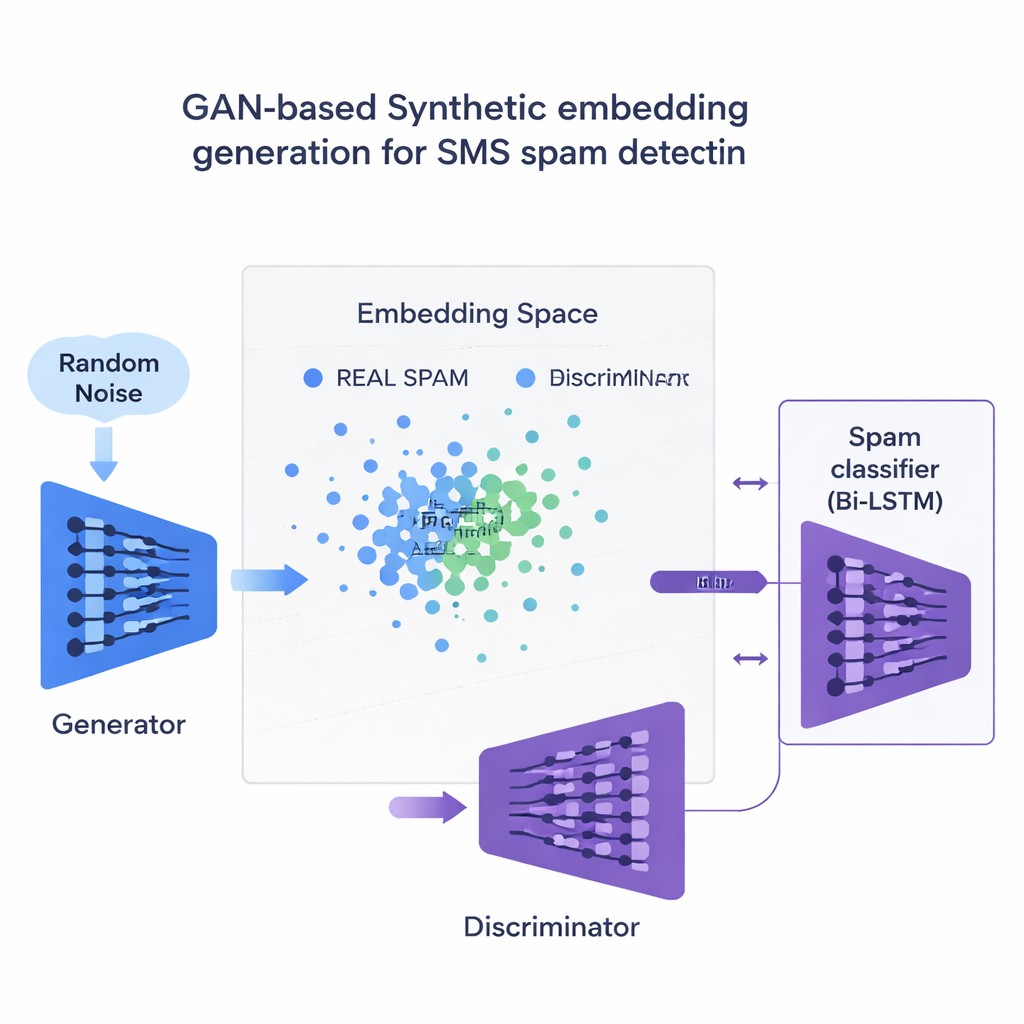
Mit intelligentem „Fake“-Spam ein unausgewogenes Dataset korrigieren
Die zentrale Innovation ist, wie die Studie den Mangel an Spam-Beispielen angeht. Anstatt vollständige gefälschte Sätze zu erzeugen, trainiert das Team eine Art neuronales Netz, ein Generative Adversarial Network (GAN), direkt auf den numerischen Embeddings von Spam-Nachrichten. Ein Teil des GAN, der Generator, lernt, synthetische spamähnliche Punkte in diesem hochdimensionalen Raum zu erzeugen, während ein anderer Teil, der Diskriminator, lernt, sie von echten zu unterscheiden. Durch diesen Wettstreit produziert der Generator realistische neue Spam-Embeddings, die den Trainingssatz erweitern. Eine Qualitätsprüfung auf Basis von Ähnlichkeit stellt sicher, dass nur synthetische Beispiele, die echten Spam eng ähneln, behalten werden, wodurch das Risiko unsinniger Daten, die den Klassifikator in die Irre führen könnten, reduziert wird.
Ergebnisse über Sprachen und Geräte hinweg
Die Forscher testen 120 verschiedene Kombinationen aus Modellen, Embeddings und Methoden zur Datenbalancierung, sowohl an einem englischen SMS-Datensatz als auch an einer mehrsprachigen Version, die ins Französische, Deutsche und Hindi übersetzt wurde. Insgesamt schneiden kontextuelle Embeddings wie BERT besser ab als ältere Wortzählansätze. Die beste Konfiguration — ein bidirektionales LSTM, gespeist mit BERT-Embeddings und trainiert mit GAN-generierten Spam-Beispielen — erreicht eine F1-Score von rund 97,6 % bei englischen Nachrichten und 94,4 % beim mehrsprachigen Datensatz und übertrifft damit bestehende Spitzenlösungen. Entscheidender Vorteil: Dies gelingt bei sehr niedriger Fehlalarmrate, was wichtig ist, damit etwa Einmalpasswörter und Bankbenachrichtigungen nicht fälschlich verborgen werden. Die Studie vergleicht diese GAN-Strategie auch mit gängigen Balancierungstools wie SMOTE und ADASYN und stellt fest, dass das GAN sauberere, realistischere Trainingsdaten erzeugt und insgesamt leicht bessere Leistung liefert.
Was das für Alltagsnutzer bedeutet
Für Nicht-Fachleute lautet die Botschaft: Spam-Filter beginnen, die Bedeutung und den Kontext Ihrer Nachrichten zu verstehen und nicht nur Einzelwörter, und sie können mit sorgfältig erzeugten synthetischen Daten „geschult“ werden, statt mehr Ihrer echten Nachrichten zu benötigen. Indem direkt in dem Raum gearbeitet wird, in dem die Nachrichtbedeutung kodiert ist, liefert die vorgeschlagene Methode Sicherheitsystemen ein reichhaltigeres Bild davon, wie Spam in vielen Sprachen aussieht, ohne sie mit plumpen Fälschungen zu überschwemmen. Das erhöht die Wahrscheinlichkeit, dass gefährliche Nachrichten abgefangen und echte zugestellt werden — ein stärkerer, anpassungsfähiger Schutz für Mobilnutzer, während Betrüger ihre Taktiken weiter verändern.
Zitation: Filali, A., Shorfuzzaman, M., Abdellaoui Alaoui, E. et al. Cross-lingual SMS spam detection using GAN-based augmentation for imbalanced datasets. Sci Rep 16, 7128 (2026). https://doi.org/10.1038/s41598-026-37769-4
Schlüsselwörter: SMS-Spam-Erkennung, GAN-Datenaugmentierung, BERT-Text-Embeddings, mehrsprachige Cybersicherheit, Mobile Phishing