Clear Sky Science · de
Eine leichtgewichtige Convolutional‑Neural‑Network‑Architektur zur Gewalterkennung in Videosequenzen
Menschen müssen nicht mehr pausenlos zuschauen
Von Konzerten und Sportarenen bis zu U‑Bahn‑Stationen und Einkaufszentren beobachten Kameras inzwischen fast jeden belebten Ort. Dennoch werden die meisten Videostreams weiterhin von müden Menschenaugen überwacht, die leicht die ersten Anzeichen einer Prügelei oder Panik übersehen können. Dieses Paper untersucht, wie eine schlanke, schnelle Form künstlicher Intelligenz Live‑Video in Echtzeit auf gewalttätiges Verhalten scannen kann, selbst auf kostengünstiger Hardware, und so Sicherheitspersonal ermöglicht, rasch zu reagieren, bevor sich Situationen verselbständigen.
Warum Gewalt in Videos so schwer zu erkennen ist
Auf den ersten Blick klingt die Aufgabe, einem Computer „Prügel“ von „keine Prügel“ unterscheiden zu lassen, einfach: Man muss nur erkennen, dass Menschen sich schlagen. In Wirklichkeit ist das Problem komplex. Die Beleuchtung kann schlecht sein oder sich plötzlich ändern, Menschenmengen verdecken die Sicht, und Kameras hängen in vielen unterschiedlichen Winkeln. Ein überfülltes Rockkonzert wirkt chaotisch, auch wenn nichts Gefährliches passiert, während ein Boxkampf gewalttätig aussieht, im Ring aber völlig normal ist. Traditionelle Systeme analysierten handgefertigte Bewegungsmuster und Kanten Frame für Frame; im Labor funktionierten sie zwar, waren aber im realen Überwachungsbetrieb oft zu langsam oder zu ungenau.
Ein schlaueres, sparsameres Modell für Kamerabilder
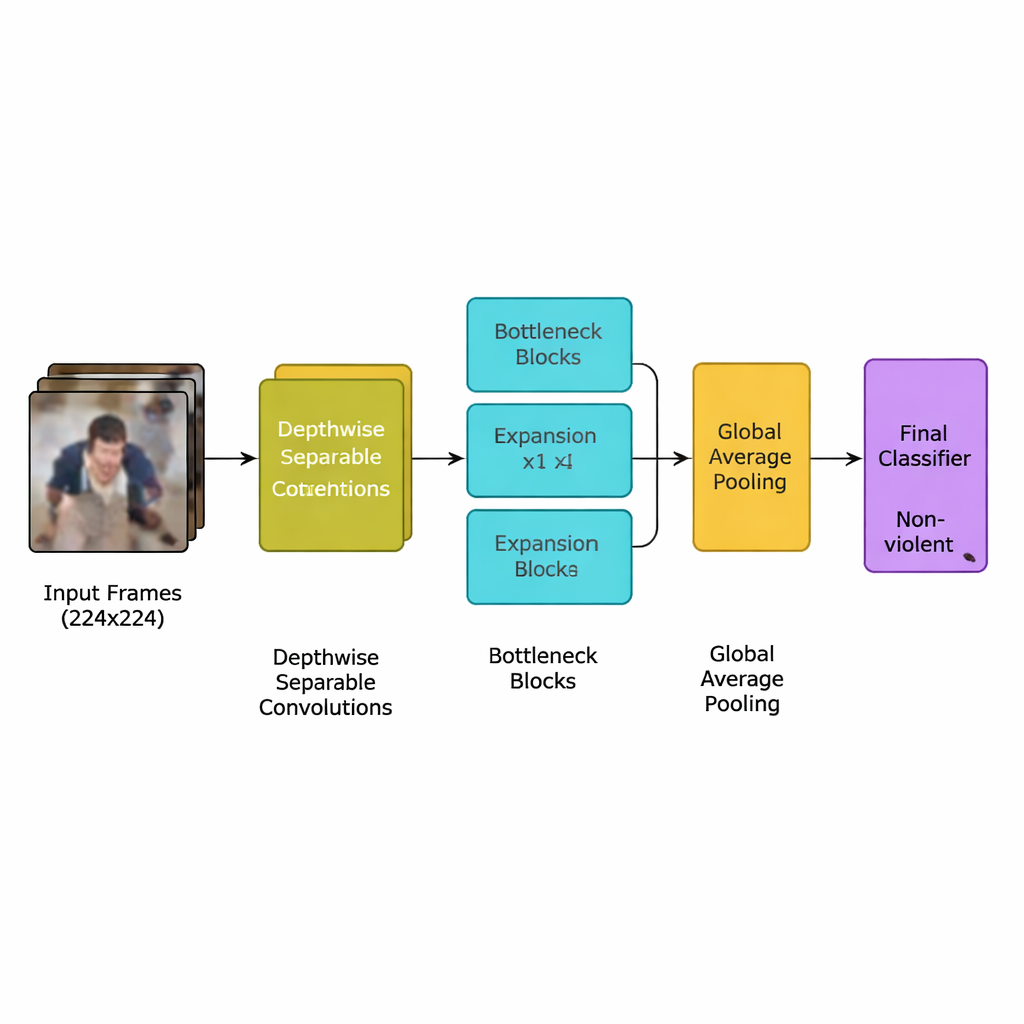
Die Autoren stellen ein neues Deep‑Learning‑Modell vor, das speziell für diese Aufgabe entwickelt wurde: ein leichtgewichtiges Convolutional Neural Network (CNN), abgeleitet von einer effizienten Modellfamilie, die als MobileNetV2 bekannt ist. Anstelle vieler schwerer Schichten, die leistungsstarke Grafikprozessoren erfordern, setzt das Netzwerk auf depthwise separable Convolutions — kleine, gezielte Berechnungen, die die Anzahl der Operationen drastisch reduzieren. Zudem verwendet es sogenannte „inverted bottleneck“‑Blöcke, die Informationen kurzzeitig erweitern und dann komprimieren, um wichtige Bewegungsmerkmale zu erhalten und Redundanz zu reduzieren. Darüber hinaus integriert das Team einen Aufmerksamkeitsmechanismus namens squeeze‑and‑excitation, der dem Netzwerk hilft, räumlich‑zeitliche Bewegungsmuster in den Vordergrund zu stellen, die für gewalttätige Vorfälle typisch sind, und ablenkende Hintergrunddetails zu ignorieren.
Von Rohvideo zu Gewalt‑Alarmen
Das vollständige System folgt einer klaren Pipeline. Zuerst werden Videostreams in Frames zerlegt, wobei nur jedes fünfte Frame beibehalten wird, um Nahezu‑Duplikate zu entfernen und gleichzeitig plötzliche Bewegungen zu bewahren, die oft auf eine Auseinandersetzung hinweisen. Die Frames werden auf standardmäßige 224×224 Pixel skaliert, leicht unscharf gemacht, um Hintergrundrauschen zu reduzieren, und während des Trainings zufällig gespiegelt oder rotiert, damit das Modell mit verschiedenen Kameraperspektiven zurechtkommt. Diese aufbereiteten Bilder werden dem leichtgewichtigen CNN zugeführt, das rohe Pixel schrittweise in höherwertige Muster kollektiven Verhaltens umwandelt. Nach einer abschließenden Pooling‑Phase, die jedes Frame zusammenfasst, gibt ein kleiner Klassifizierer eine einfache Entscheidung aus: gewalttätig oder nicht‑gewalttätig. Da das Modell nur etwa 1,94 Millionen Parameter verwendet — weniger als seine Vorgänger MobileNet und MobileNetV2 — kann es in Echtzeit auf bescheidener Hardware nahe den Kameras laufen, statt in einem entfernten Rechenzentrum.
Das System auf dem Prüfstand
Um zu prüfen, ob dieses kompakte Design mit größeren Netzwerken konkurrieren kann, trainierten und evaluierten die Forscher es an zwei weit verbreiteten Benchmarks. Das Real‑Life Violence Situations Dataset enthält 2.000 kurze Clips, von YouTube gesammelt, die sowohl Alltagsszenen als auch reale Prügeleien an unterschiedlichen Orten zeigen. Das Hockey Fight Dataset bietet 1.000 Clips aus professionellen Hockeyspielen, aufgeteilt in normales Spiel und Prügeleien auf dem Eis. In diesen Datensätzen klassifizierte das vorgeschlagene Modell etwa 97 Prozent der Clips in realen Szenarien und 94 Prozent im Hockeymaterial korrekt und erreichte damit Ergebnisse, die mit größeren CNNs wie InceptionV3 und VGG‑19 mithalten bzw. diese übertreffen, während es deutlich weniger Rechenaufwand benötigt. Cross‑Tests zwischen den beiden Datensätzen — Training auf dem einen, Test auf dem anderen — zeigten, dass das System immer noch zufriedenstellend performt, was darauf hindeutet, dass es allgemeine Bewegungsmuster erfasst und nicht nur ein einzelnes Umfeld auswendig lernt.
Was das für die öffentliche Sicherheit bedeutet
Für Nicht‑Fachleute ist die wichtigste Erkenntnis, dass es nun möglich ist, Kamerasysteme zu bauen, die wahrscheinliche Gewalttaten schnell und kostengünstig automatisch markieren, ohne riesige Server oder ständige menschliche Überwachung zu benötigen. Die Studie zeigt, dass ein sorgfältig beschnittenes und abgestimmtes neuronales Netzwerk viele Streams gleichzeitig überwachen, Warnmeldungen senden, wenn gefährliches Verhalten erkannt wird, und dennoch auf energieeffizienter Hardware laufen kann, die sich für Verkehrsknotenpunkte, Schulen, Krankenhäuser und Straßen eignet. Herausforderungen bleiben — etwa sehr dunkle Szenen, extreme Überfüllung oder die Ergänzung durch akustische Hinweise — doch die Arbeit weist in Richtung einer Zukunft, in der intelligente Kameras als unermüdliche Frühwarnsensoren dienen, Sicherheitsteams effektiver unterstützen und die Belastung für menschliche Beobachter verringern.
Zitation: Tyagi, B., Jain, R., Jain, P. et al. A lightweight convolutional neural network architecture for violence detection in video sequences. Sci Rep 16, 7557 (2026). https://doi.org/10.1038/s41598-026-37743-0
Schlüsselwörter: Gewalterkennung, Videoüberwachung, leichtgewichtige CNN, MobileNetV2, öffentliche Sicherheit