Clear Sky Science · de
MSRCTNet: ein neuartiges Multi‑Scale Capsule Triplet Network zur effizienten Entfernung redundanter Frames in Videos der drahtlosen Kapselendoskopie
Eine Kamera schlucken, in Bildern ertrinken
Stellen Sie sich vor, Magen‑Darm‑Erkrankungen zu diagnostizieren, indem man eine vitamin‑große Kamera schluckt, die lautlos den gesamten Verdauungstrakt fotografiert. Die drahtlose Kapselendoskopie macht das bereits möglich, doch jede Untersuchung liefert rund 55.000 Bilder, von denen die meisten fast gleich aussehen. Ärztinnen und Ärzte müssen dieses visuelle Meer durchforsten, um winzige Stellen mit Blutungen, Entzündungen oder Tumoren zu finden. Die Studie hinter MSRCTNet stellt eine einfache, aber entscheidende Frage: Kann ein intelligentes System die sich ähnelnden Frames sicher entfernen, sodass Ärztinnen und Ärzte nur das sehen, was wirklich wichtig ist?
Warum zu viele Bilder ein Problem sein können
Konventionelle Endoskopie erfordert einen flexiblen Schlauch, der durch Mund oder After eingeführt wird — ein Eingriff, den viele Patienten als unangenehm empfinden und mit dem nicht immer der gesamte Dünndarm erreicht werden kann. Die Kapselendoskopie löst das, indem eine Pillen‑Kamera durch den Darm treiben darf und jede Sekunde ein Bild macht. Der Nachteil ist die Datenflut: Nur etwa 1 % der Frames enthalten eindeutig nützliche Informationen, der Rest zeigt meist wiederkehrende Falten des Gewebes. Das Durchsehen solcher Mengen ist langsam und ermüdend, wodurch die Gefahr steigt, dass eine erschöpfte Untersuchungsperson eine subtile Läsion übersieht. Frühere Computerverfahren versuchten zu helfen, indem sie ähnliche Frames gruppierten, Daten komprimierten oder auf einfache Farb‑ und Texturmerkmale setzten, scheiterten jedoch oft, wenn sich die Beleuchtung änderte, der Darm sich komplex bewegte oder seltene Abnormalitäten nur in wenigen Beispielen auftraten.
Eine intelligentere Methode, Wiederholungen zu erkennen
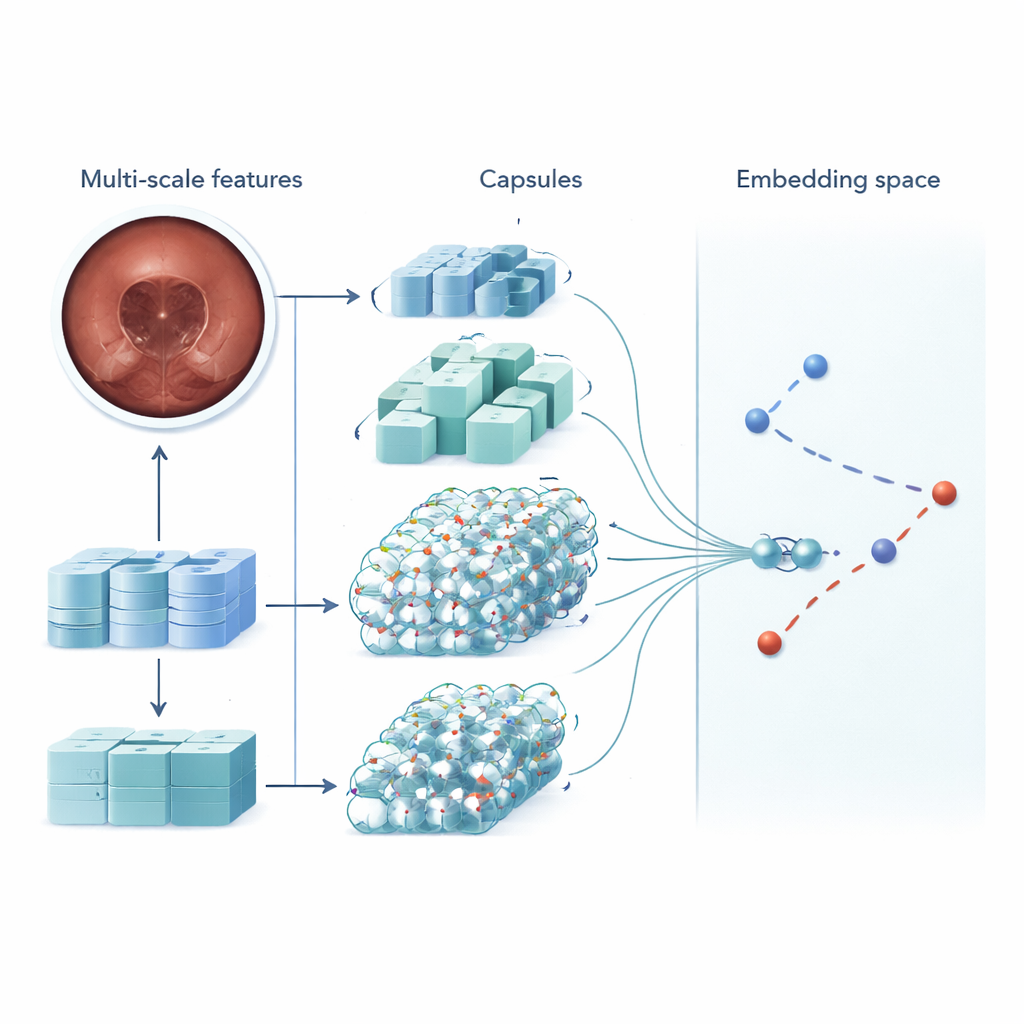
MSRCTNet (Multi‑Scale Capsule Triplet Network) ist ein Deep‑Learning‑System, das als intelligenter Filter für Kapselvideos konzipiert wurde. Anstatt jedes Bild als flache Abbildung zu behandeln, betrachtet das System Muster auf mehreren Skalen gleichzeitig — feine Texturen der Darmschleimhaut und größere Formen der Darmwand — und setzt dabei einen Aufmerksamkeitsmechanismus ein, um die informativsten Details zu betonen. Diese angereicherten Merkmale werden dann an eine kapselartige Schicht weitergegeben, die bewahrt, wie Bildteile räumlich zueinander stehen, etwa Orientierung und Anordnung von Falten oder Läsionen. Schließlich vergleicht ein spezielles Ähnlichkeitsmodul Triplets von Frames — ein Referenzbild, eins, das ähnlich sein sollte, und eins, das unterschiedlich sein sollte —, um eine Repräsentation zu lernen, in der wirklich redundante Frames eng zusammenclustern und unterscheidbare Frames auseinanderstehen.
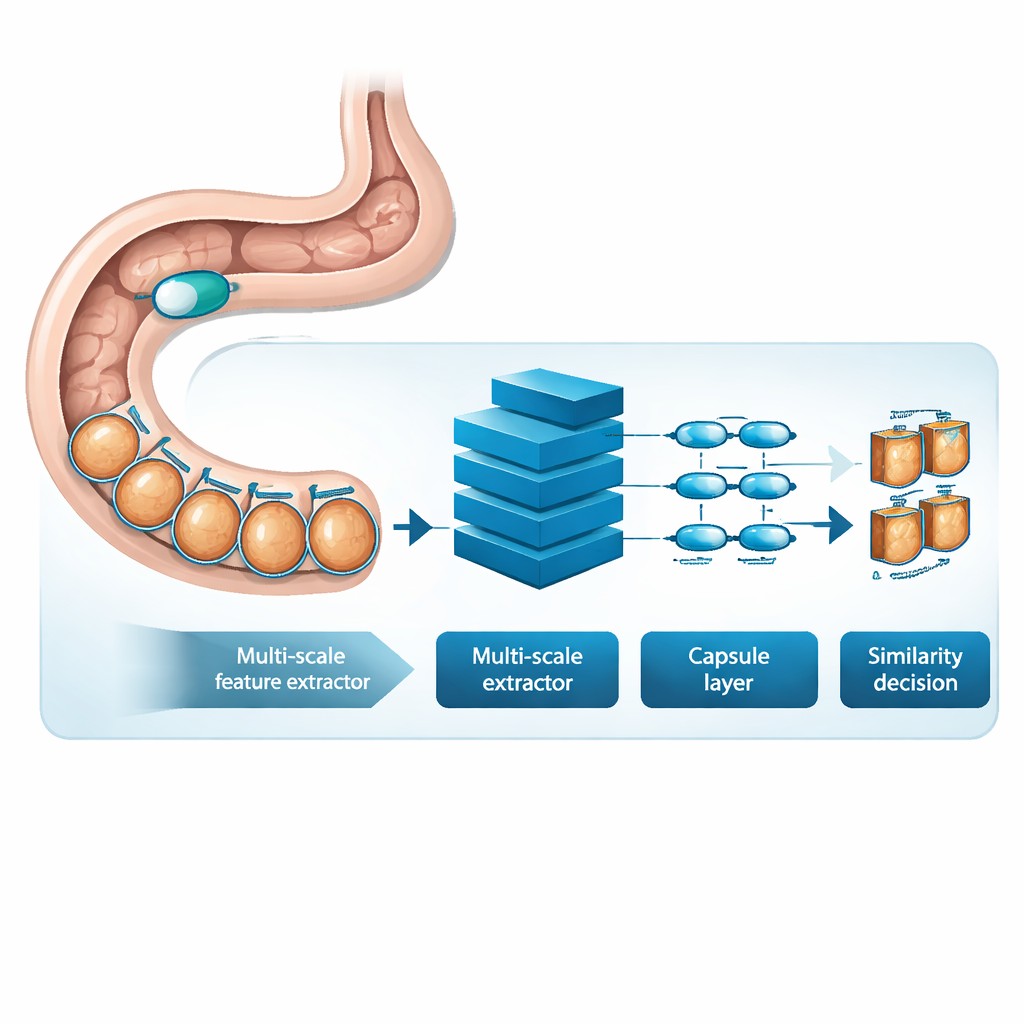
Aus echten Patientenuntersuchungen lernen
Zur Evaluierung von MSRCTNet stellten die Forscher ein großes Datenset mit 257.362 Bildern aus 60 Kapseluntersuchungen zusammen, die in einem Krankenhaus in China durchgeführt wurden. Die Bilder enthielten normales Gewebe, durch Blasen verdeckte Bereiche und klare Auffälligkeiten wie Blutungen und Entzündungen, alle von erfahrenen Klinikern etikettiert. Das System wurde darauf trainiert, zu beurteilen, ob Paare von Frames ähnlich sind oder nicht, und nutzte dabei eine Kombination aus zwei Lernzielen: eines, das Frames derselben Kategorie zusammenzieht und solche unterschiedlicher Kategorien auseinanderdrückt, und ein anderes, das dem Netzwerk beibringt, direkt zu sagen, ob ein Paar ähnlich ist. Nach dem Training überprüft das Modell ein Video jeweils drei Frames gleichzeitig und entscheidet, welche der Nachbarbilder wirklich redundant sind. Durch einfache Regeln, angewandt auf diese Ähnlichkeitsentscheidungen, verwirft es wiederholte Ansichten und behält repräsentative Keyframes bei.
Geschwindigkeit, Genauigkeit und weniger übersehene Probleme
Auf den Testdaten behandelte MSRCTNet die Frame‑Redundanz in etwa 96 % der Fälle korrekt, mit einer Fehlalarmrate unter 3 % und einer verpassten‑Frame‑Rate unter 0,2 %. In der Praxis heißt das bei einer Untersuchung mit 50.000 Frames, dass weniger als 100 potenziell relevante Frames übersehen würden — so wenige, dass die umgebenden Bilder bei sechs Bildern pro Sekunde noch Kontext liefern. Im Vergleich zu mehreren früheren Verfahren, die auf Clustering, Bewegungsanalyse oder einfacheren neuronalen Netzen basieren, war MSRCTNet sowohl genauer als auch robuster, wenn die Daten unausgewogen waren, also normale Bilder seltenen Läsionen bei weitem überwogen. Das System lief außerdem schnell: etwa 0,02 Sekunden pro Frame, also rund 15 Minuten, um eine komplette Untersuchung auf etwa 2.500 Keyframes zu reduzieren — ein Volumen, das für die menschliche Nachsicht deutlich handhabbarer ist.
Was das für Patienten und Ärztinnen bedeutet
Für Patienten verändert der hier beschriebene Fortschritt die geschluckte Kapsel nicht, könnte aber ihre Untersuchung effektiver machen. Indem nahe Duplikate automatisch entfernt werden, ohne handabgestimmte Schwellenwerte oder fragile Heuristiken, ermöglicht MSRCTNet Klinikern, sich auf eine prägnante, informationsreiche Zusammenfassung der Reise durch den Darm zu konzentrieren. Der Ansatz bewahrt klinisch wichtige Befunde, reduziert Ermüdung und Lesezeit am Monitor und könnte nichtinvasive Kapseluntersuchungen attraktiver und weiter verbreitet machen. Im Kern verwandelt die Methode einen Bildersturm in ein sorgfältig kuratiertes Highlight‑Reel und rückt das Versprechen künstlicher Intelligenz einen Schritt näher an die alltägliche Versorgung bei Erkrankungen des Verdauungstrakts.
Zitation: Li, Q., Wang, S., Cheng, Z. et al. MSRCTNet: a novel multi-scale capsule triplet network for efficient redundant frame removal in wireless capsule endoscopy videos. Sci Rep 16, 6902 (2026). https://doi.org/10.1038/s41598-026-37669-7
Schlüsselwörter: drahtlose Kapselendoskopie, medizinische Videozusammenfassung, Deep Learning, Entfernung redundanter Frames, gastrointestinale Bildgebung