Clear Sky Science · de
DNS-Fingerabdruck basierend auf Nutzeraktivität
Warum Ihre Webbesuche eine verborgene Spur hinterlassen
Jedes Mal, wenn Sie im Web surfen, fragt Ihr Computer stillschweigend ein besonderes Adressbuch, das Domain Name System (DNS), wie er jede Seite erreichen kann. Diese Anfragen verschwinden nicht einfach. Über Tage und Wochen bilden sie ein Muster daraus, welche Arten von Seiten Sie besuchen, wann und wie oft. Diese Arbeit zeigt, dass diese Muster markant genug sind, um wie ein Verhaltens‑Fingerprint zu wirken und leistungsstarken Algorithmen zu erlauben, Nutzer voneinander zu unterscheiden — selbst wenn sich ihre sichtbare IP‑Adresse ändert. Das eröffnet zwar Chancen für die Sicherheit, wirft aber auch ernste Fragen zum Datenschutz auf.
Das Telefonbuch des Internets und Ihre Gewohnheiten
DNS übersetzt menschenlesbare Webadressen wie www.google.com in die numerischen IP‑Adressen, die Computer zur Kommunikation verwenden. Die meisten Menschen denken nie darüber nach, doch jede Suche, jeder Videostream, jeder E‑Mail‑Check oder App‑Update löst eine oder mehrere DNS‑Anfragen aus. Diese Anfragen werden typischerweise von lokalen oder öffentlichen DNS‑Servern bearbeitet und als einfache Einträge protokolliert: welche IP‑Adresse welche Domain abgefragt hat und wann. Sammelt man genug dieser Einträge, erhält man ein detailliertes Bild davon, welche Arten von Online‑Diensten ein Nutzer nutzt — von Business‑Tools und Cloud‑Speichern bis zu sozialen Netzwerken und Streaming‑Plattformen. Während frühere Forschung solche Spuren nutzte, um Malware zu entdecken oder Gerätetypen zu identifizieren, stellt diese Studie eine direktere Frage: Lassen sich allein aus wiederkehrendem DNS‑Verhalten einzelne Nutzer oder Geräte eindeutig bestimmen?
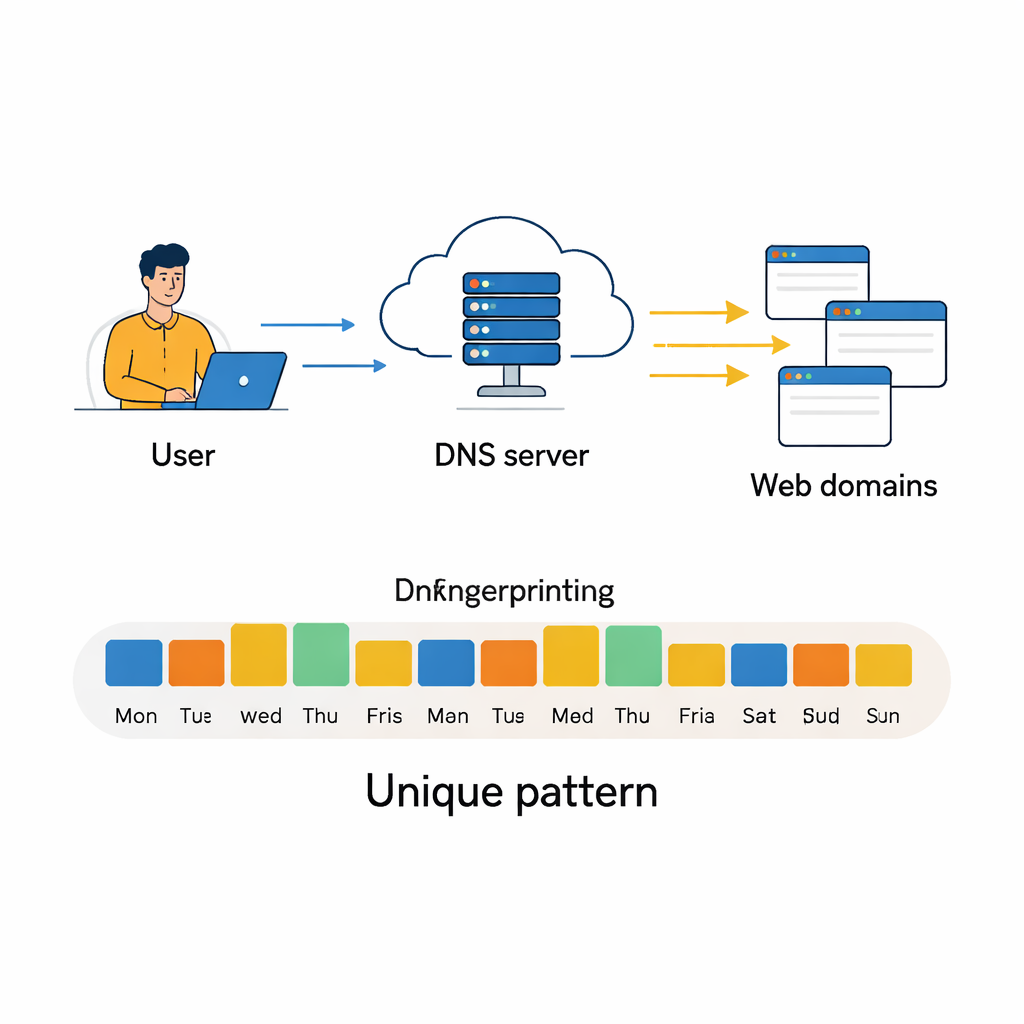
Tägliche Klicks in einen Verhaltens‑Fingerprint verwandeln
Die Autoren bauen auf einem großen, öffentlich verfügbaren DNS‑Datensatz auf, der über drei Monate von einem lokalen Internetanbieter gesammelt wurde. Täglich fassen sie die DNS‑Aktivität für jede aktive IP‑Adresse in einer kompakten Zusammenfassung zusammen: Anzahl der Gesamtanfragen, wie viele verschiedene Domains kontaktiert wurden und vor allem, wie diese Domains in 75 Inhaltskategorien fallen, etwa „Allgemeines Geschäft“, „Software / Hardware“ oder „Soziale Netzwerke“. Sie behalten nur IP‑Adressen, die an mindestens 80 Prozent der Tage erscheinen, um genügend Historie pro Nutzer zu gewährleisten, und entfernen sorgfältig redundante oder nahezu leere Merkmale. Zusätzlich wenden sie statistische Werkzeuge an, um stark korrelierte Felder zu erkennen, extreme Ausreißer im Anfragevolumen zu filtern und komprimieren die Daten dann mit Hauptkomponentenanalyse, sodass die nützliche Variation in deutlich weniger Dimensionen erhalten bleibt. Bei der Visualisierung der bereinigten Daten mit einer Technik namens t‑SNE finden sie, dass viele IP‑Adressen enge, gut getrennte Cluster bilden — ein frühes Zeichen dafür, dass automatische Klassifikation möglich sein könnte.
Maschinelles Lernen auf die Probe stellen
Mit diesem verarbeiteten Datensatz behandeln die Forscher die Nutzeridentifikation als ein massives Klassifikationsproblem: Gegeben sind DNS‑Statistiken eines Tages — bestimmen Sie, zu welcher der 1.727 IP‑Adressen sie gehören. Sie vergleichen eine Reihe von Modellen, von klassischen Methoden wie Naive Bayes und Random Forests bis zu fortgeschritteneren Werkzeugen wie XGBoost und tiefen neuronalen Netzen. Jedes Modell wird auf unterschiedlichen Versionen der Daten trainiert und validiert (roh, skaliert, standardisiert oder dimensional reduziert) und anhand der Häufigkeit bewertet, mit der es die richtige Klasse korrekt zuweist, sowie anhand von Präzision und Recall. Traditionelle Modelle schneiden ordentlich ab — Random Forests erreichen etwa 73 Prozent Genauigkeit, XGBoost übertrifft 81 Prozent und unterscheidet korrekt mehr als 99 Prozent aller Klassen. Herausragend sind jedoch die neuronalen Netze, insbesondere ein maßgeschneidertes Convolutional Neural Network (CNN), das den Merkmalsvektor wie ein eindimensionales Bild täglichen Verhaltens behandelt.
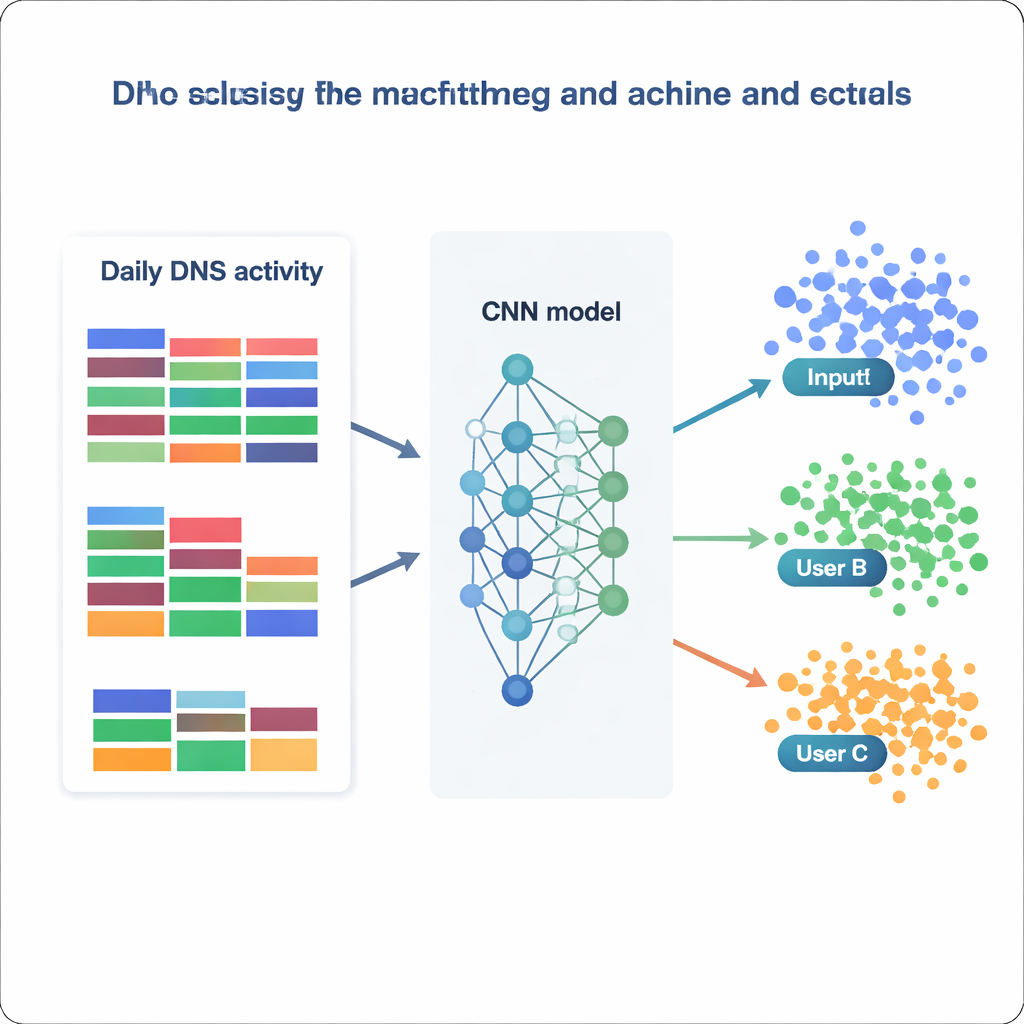
Wie gut kann ein Modell wissen, „wer“ Sie sind?
Das beste CNN, auf normalisierten Daten trainiert, identifiziert die Quell‑IP an nahezu 87 Prozent der zurückgehaltenen Tage korrekt und sagt erfolgreich 1.694 der 1.727 unterschiedlichen IP‑Adressen voraus. Praktisch bedeutet das, dass die meisten Nutzer — oder kleine Gruppen, die sich hinter einer gemeinsamen IP verbergen — über die Zeit stabile, wiedererkennbare DNS‑Muster zeigen. Betrachtet man, auf welche Merkmale die Modelle am stärksten setzen, finden die Autoren zwei komplementäre Strategien. Einige Modelle stützen sich stark auf sehr häufige Kategorien wie allgemeine Geschäftsdienste oder Software, die breite Gewohnheiten erfassen. Andere, etwa XGBoost, gewinnen zusätzliche Aussagekraft aus seltenen, aber aussagekräftigen Kategorien, die mit Sicherheit, Politik oder Nischeninteressen zu tun haben. Zusammengenommen zeigen diese Ergebnisse, dass bereits einfache, aggregierte Statistiken — ohne die vollständige Liste der Domainnamen zu betrachten — genug Struktur kodieren können, um Nutzer mit bemerkenswerter Zuverlässigkeit wiederzuerkennen.
Versprechen, Grenzen und Datenschutzfragen
Für Strafverfolger und Netzverteidiger könnten DNS‑Fingerabdrücke ein wertvolles Werkzeug werden, um Wiederholungstäter zu verfolgen, kompromittierte Maschinen zu erkennen oder Botnets aufzuspüren, die wechselnde IP‑Adressen nutzen, um Sperren zu umgehen. Gleichzeitig hebt die Studie klare Grenzen hervor: DNS‑Fingerabdrücke sind am stabilsten, wenn eine öffentliche IP einer einzelnen Person zugeordnet ist, was in modernen IPv6‑Netzen realistischer ist als in der heutigen IPv4‑Welt, in der viele Nutzer eine Adresse via NAT teilen. Häufiges Wechseln von DNS‑Servern oder öffentliche WLAN‑Nutzung schwächt das Signal ebenfalls. Am wichtigsten ist, dass die Arbeit ein Datenschutzrisiko betont, das für normale Nutzer schwer zu erkennen ist. Da DNS‑Protokollierung weitgehend unsichtbar und passiv erfolgt, kann Verhaltensverfolgung stattfinden, ohne Cookies zu installieren oder aufdringliche Skripte auszuführen. Die Autoren veröffentlichen ihren Datensatz und ihre Modelle offen und argumentieren, dass transparente Forschung notwendig ist, damit die Gesellschaft die Sicherheitsvorteile von DNS‑basiertem Fingerprinting gegen dessen Potenzial für stille Überwachung abwägen und entscheiden kann, welche Schutzmaßnahmen und Richtlinien diese neue, potente Form der Online‑Identifikation regeln sollten.
Zitation: Morozovič, D., Konopa, M. & Fesl, J. DNS fingerprint based on user activity. Sci Rep 16, 7314 (2026). https://doi.org/10.1038/s41598-026-37631-7
Schlüsselwörter: DNS-Fingerprinting, Verfolgung von Nutzern, Internet‑Privatsphäre, Netzwerksicherheit, Maschinelles Lernen