Clear Sky Science · de
Echtwelt-Gesichts-Superauflösung basierend auf generativen gegnerischen und Gesichts-Ausrichtungsnetzwerken
Scharfere Gesichter aus verschwommenen Fotos
Wer schon versucht hat, in ein Gesicht in einer alten Überwachungskameraaufnahme oder einem winzigen Social-Media-Foto hineinzuzoomen, kennt die Frustration: Je mehr man vergrößert, desto mehr verwandelt sich das Gesicht in einen blockigen Schleier. Dieses Paper stellt einen neuen KI-Ansatz vor, der solche niedrigqualitativen Echtwelt-Gesichtsbilder deutlich klarer machen kann und dabei Identität und Ausdruck einer Person besser bewahrt. Das hat offensichtliche Folgen für Überwachungskameras, Foto-Forensik und sogar Alltags-Apps zur Bildverbesserung.
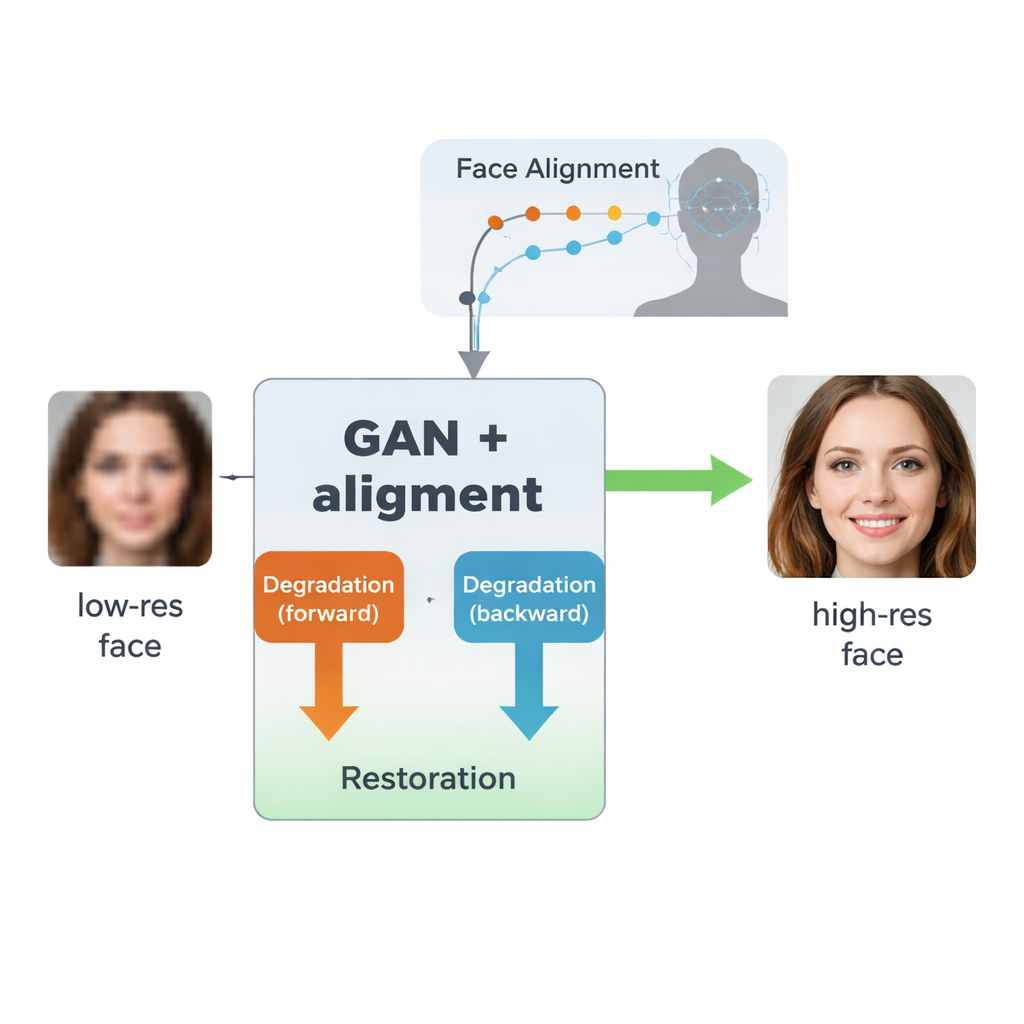
Warum verschwommene Gesichter so schwer zu reparieren sind
Ein kleines, unscharfes Gesichtsbild schärfer aussehen zu lassen ist nicht einfach nur eine Frage des „Pixel-Hinzufügens“. Traditionelle Methoden nutzten handgefertigte Regeln oder einfache Muster, und neuere Deep-Learning-Techniken lernten oft an künstlich degradieren Bildern: Man nimmt ein sauberes hochauflösendes Gesicht, verwischt und verkleinert es und bringt dann einem Netzwerk bei, den Prozess umzukehren. Das Problem ist, dass Echtweltbilder – etwa von Überwachungskameras oder komprimierten Videos – auf unordentliche, unvorhersehbare Weise beschädigt sind. Unschärfe, Rauschen und Kompressionsartefakte stimmen selten mit den sauberen synthetischen Beispielen überein, die im Training verwendet werden; daher versagen Modelle, die im Labor gut aussehen, oft bei realem Filmmaterial. Schlimmer noch: Sie können Gesichter erzeugen, die zwar plausibel wirken, aber nicht mehr der ursprünglichen Person ähneln.
Eine zweiseitige Lernschleife für Echtweltbilder
Die Autoren bauen auf einer KI-Klasse namens generative gegnerische Netzwerke (GAN) auf, die realistische Bilder erzeugen, indem zwei neuronale Netzwerke gegeneinander antreten: eins erzeugt Bilder, das andere bewertet, wie echt sie wirken. Ihr Design, inspiriert von einem früheren Modell namens SCGAN, nutzt eine „Semi-Zyklus“-Struktur mit zwei komplementären Schleifen. In der Vorwärts-Schleife werden echte hochauflösende Gesichter von einem Zweig absichtlich degradiert, um synthetische niedrigauflösende Versionen zu erzeugen, die dann von einem gemeinsamen Restaurationszweig wiederhergestellt werden. In der Rückwärts-Schleife werden tatsächlich niedrigqualitative Echtweltgesichter von demselben Restaurationszweig verbessert und anschließend von einem anderen Zweig wieder degradiert, sodass sie echten niedrigauflösenden Bildern ähneln. Indem Konsistenz in beiden Richtungen erzwungen wird – degradieren dann wiederherstellen oder wiederherstellen dann degradieren – lernt das System ein realistisches Modell dafür, wie Gesichter in der Praxis ruiniert werden und wie man diesen Prozess umkehrt, ohne jemals perfekt passende Paare aus niedriger und hoher Qualität von echten Bildern zu benötigen.
Dem Netzwerk beibringen, wie ein Gesicht wirklich aussieht
Eine Schlüsselinnovation dieser Arbeit besteht darin, dem System nicht nur beizubringen, Bilder schärfer erscheinen zu lassen, sondern die zugrunde liegende Geometrie eines menschlichen Gesichts zu respektieren. Dafür integrieren die Autoren ein separates Gesichts-Ausrichtungsnetzwerk, das ursprünglich dafür entwickelt wurde, Landmarken wie Augenwinkel, Nasenspitze und Kontur des Mundes zu lokalisieren. Dieses Ausrichtungsnetzwerk sagt "Heatmaps" voraus, die zeigen, wo jede Landmarke liegen sollte. Während des Trainings vergleicht das Modell die Heatmaps des wiederhergestellten Bildes mit denen eines echten hochauflösenden Gesichts derselben Person und bestraft Abweichungen. Entscheidend ist, dass hierfür ein vortrainiertes Ausrichtungsmodell verwendet wird und nicht für jedes Trainingsbild manuelle Landmarkenbeschriftungen erforderlich sind. Das Ergebnis ist eine Art geometrische Leitlinie: Das Enhancement-Netzwerk wird dazu gebracht, Augen, Nase und Mund an den richtigen Positionen und in der richtigen Form zu platzieren, statt die Unschärfe einfach mit generischen gesichtsähnlichen Texturen zu übermalen.
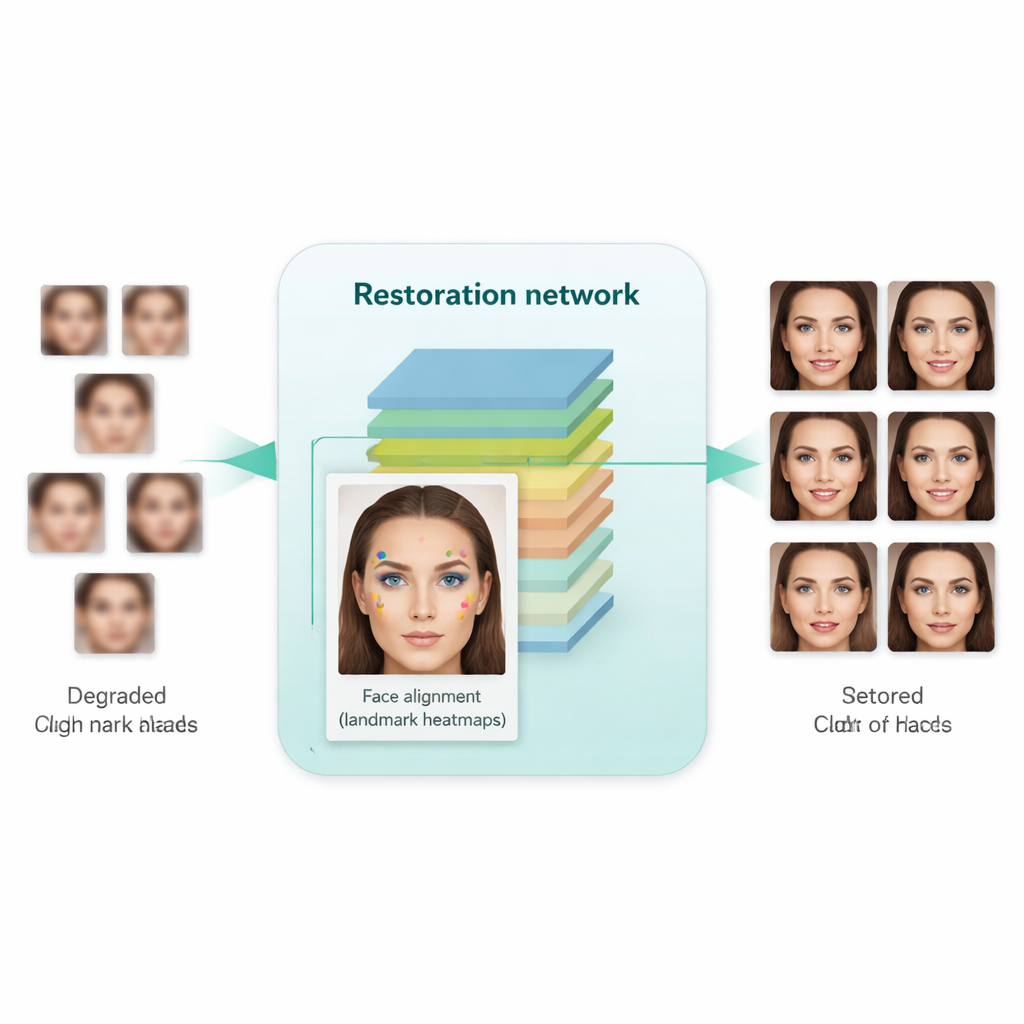
Wie gut funktioniert es in der Praxis?
Die Forscher trainierten ihr System auf einer großen Sammlung hochqualitativer Gesichter und einem separaten Satz wirklich niedrigqualitativer Gesichter aus Echtwelt-Datensätzen. Sie testeten es anschließend sowohl an synthetischen Benchmarks (wo saubere Ground-Truth-Bilder verfügbar sind) als auch an Echtweltbildern (wo nur visuelle Glaubwürdigkeit und statistische Maße angewendet werden können). Im Vergleich zu früheren Methoden – einschließlich bekannter Werkzeuge wie Real-ESRGAN, GFPGAN und dem ursprünglichen SCGAN – erzeugte der neue Ansatz Bilder, die nicht nur natürlicher und weniger verzerrt wirkten, sondern auch bei praktischen Aufgaben bessere Ergebnisse lieferten. Wenn die verbesserten Bilder in Standard-Gesichtserkennungsalgorithmen und ein verbreitetes Gesichtserkennungsmodell (FaceNet) eingespeist wurden, verbesserten sich Erkennungs- und Verifikationsgenauigkeit spürbar, was darauf hindeutet, dass identitätsrelevante Details besser erhalten blieben. Gleichzeitig deuteten automatisierte Qualitätsmetriken darauf hin, dass die erzeugten Gesichter in ihrer Verteilung näher an echten hochauflösenden Fotos lagen.
Was das für den Alltag bedeutet
Einfach gesagt zeigt diese Arbeit, dass man aus schlechten Bildern schärfere, vertrauenswürdigere Gesichter gewinnen kann, indem man zwei Ideen kombiniert: ein realistisches Modell dafür lernt, wie Bilder in der echten Welt ruiniert werden, und Informationen über Gesichtslandmarken nutzt, um die Gesichtsstruktur intakt zu halten. Anstatt lediglich ein schön aussehendes Gesicht „zu erraten“, wird das System geleitet, die richtige Person mit klareren Augen, Mund und Gesamtform zu rekonstruieren. Das macht die Methode besonders vielversprechend für Anwendungen wie Sicherheit, Forensik und Archivrestauration, wo sowohl visuelle Klarheit als auch korrekte Identität entscheidend sind und originale hochqualitative Versionen der Bilder selten verfügbar sind.
Zitation: Fathy, H., Faheem, M.T. & Elbasiony, R. Real-world face super-resolution based on generative adversarial and face alignment networks. Sci Rep 16, 7492 (2026). https://doi.org/10.1038/s41598-026-37573-0
Schlüsselwörter: Gesichts-Superauflösung, generative gegnerische Netzwerke, Gesichts-Ausrichtung, Gesichtserkennung, Bildwiederherstellung