Clear Sky Science · de
Bildverarbeitungs-Pipeline zur KI-gestützten Charakterisierung von Nanopartikel-Megalibraries
Warum winzige Teilchen große Datenhilfe brauchen
Die moderne Materialwissenschaft baut zunehmend darauf, riesige Mengen winziger Partikel herzustellen und zu testen, um bessere Katalysatoren, Batterien und andere fortschrittliche Materialien zu entdecken. Neue Methoden ermöglichen es inzwischen, Millionen unterschiedlicher Nanopartikel auf einem einzigen Chip wachsen zu lassen, doch die Qualität jedes einzelnen per Mikroskop zu prüfen erzeugt weit mehr Bilder, als ein Mensch sinnvoll sichten kann. Dieser Artikel beschreibt, wie Forscher eine automatisierte Bildverarbeitungs- und KI-Pipeline aufgebaut haben, die „gute“ von „schlechten“ Nanopartikelbildern schnell trennt, Rechenkosten senkt und Experimente beschleunigt, während die Entscheidungen hoch zuverlässig bleiben.
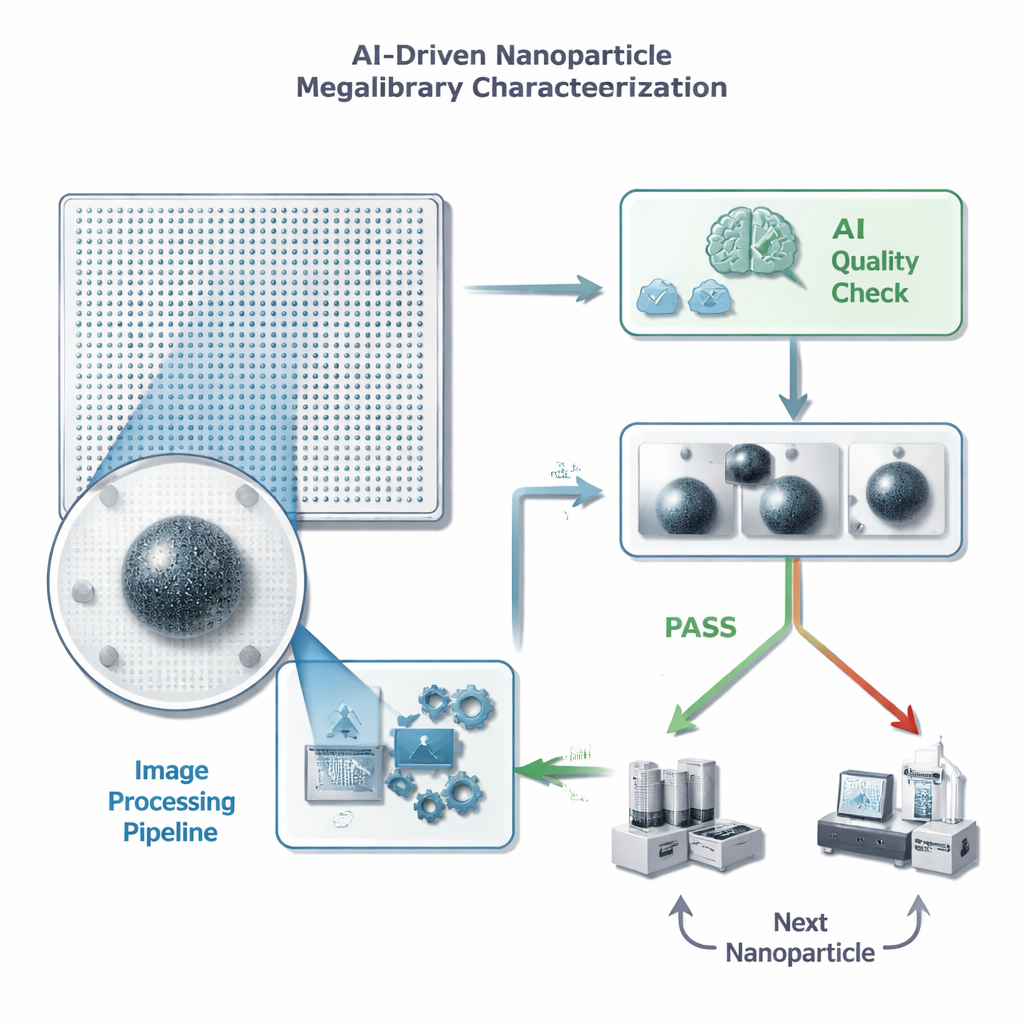
Von endlosen Bildern zu schnellen Entscheidungen
Jeder Nanopartikel auf einem „Megalibrary“-Chip sitzt an einer bekannten Position und kann mit einem Elektronenmikroskop aufgenommen werden. Bevor Wissenschaftler Zeit und teure Folgemessungen in ein einzelnes Teilchen investieren, brauchen sie einen schnellen Qualitätscheck: Ist genau ein scharfes Partikel im Bild, ohne störenden Fremdinhalt oder Artefakte? Die Autorinnen und Autoren formulieren dies als einfache Bestehen/Nichtbestehen-Aufgabe für ein ML-Modell, allerdings mit strikten Beschränkungen für die Verarbeitungszeit pro Bild — weniger als eine halbe Sekunde, weil ein einzelner Chip Millionen Partikel enthalten kann. Sie betonen außerdem, dass falsch-positive Entscheidungen besonders schädlich sind: Wenn die KI ein schlechtes Bild fälschlich durchwinkt, verschwendet das Zeit und Speicher für unnütze Detailmessungen, während ein gelegentliches Übersehen eines guten Partikels dem Gesamtfortschritt weniger stark schadet.
Das Bild säubern, bevor die KI hinschaut
Anstatt rohe, verrauschte Mikroskopbilder direkt in ein großes, komplexes neuronales Netz zu werfen, entwarf das Team eine maßgeschneiderte Bildverarbeitungs-Pipeline, die die Aufnahmen zuerst „säubert“. Die Pipeline entfernt Hintergrundrauschen, schärft Kanten, schneidet das Bild eng um das Partikel zu und verkleinert es anschließend. Entscheidend macht diese Vorverarbeitung schwache Details besser sichtbar und simuliert das Aussehen einer höheren Vergrößerung, ohne die Probe neu aufzunehmen. Das Ergebnis ist ein kompaktes, kontrastreiches Bild, das einem vergleichsweise einfachen neuronalen Netz zugeführt werden kann, wodurch sowohl Trainingszeit als auch Speicherbedarf sinken, während die für Qualitätsurteile wichtigen Details erhalten bleiben.
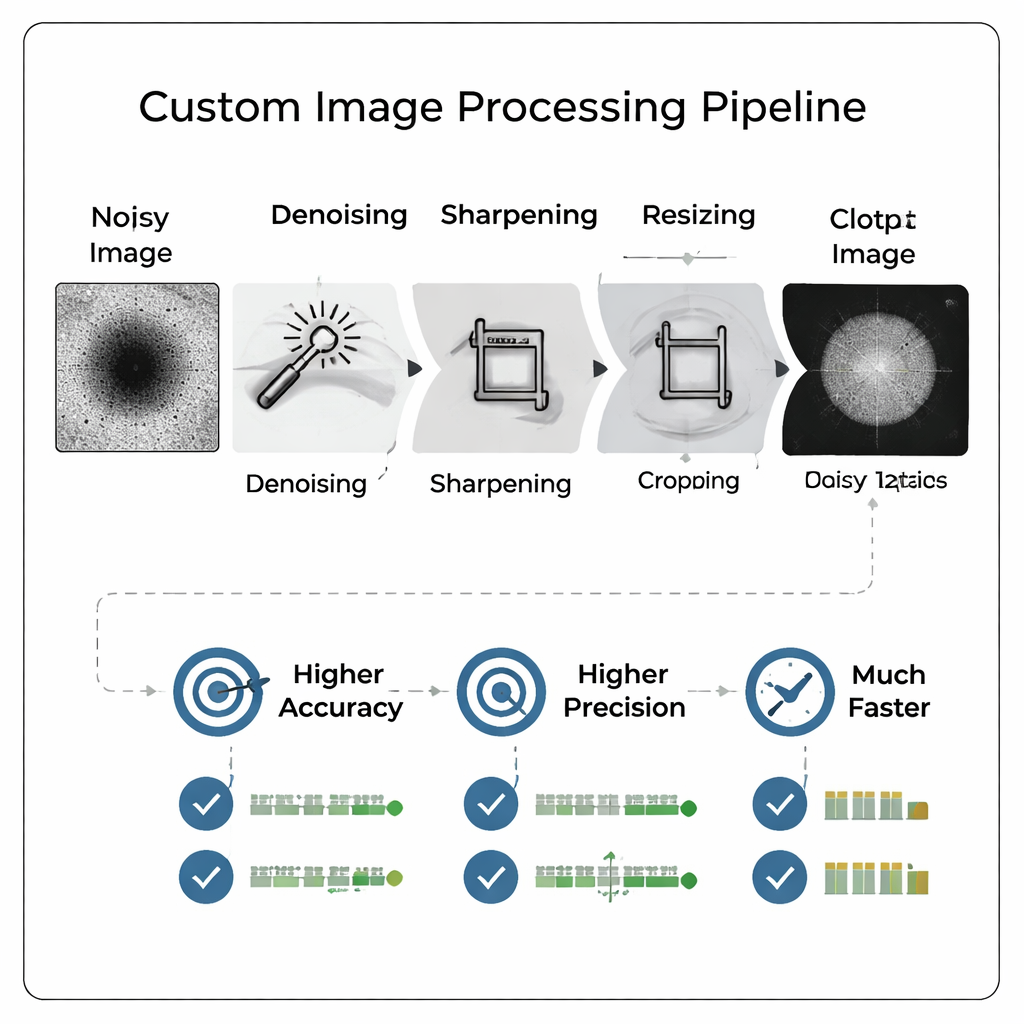
Schlauere Bilder schlagen größere Modelle
Die Forschenden verglichen systematisch viele Pipeline-Varianten und Auflösungen und trainierten schließlich 800 verschiedene Modelle, um zu untersuchen, wie Bildgröße und Verarbeitung die Leistung beeinflussen. Sie fanden heraus, dass sorgfältig verarbeitete Bilder in moderaten Auflösungen (etwa 128×128 Pixel) einem kleinen Faltungsnetzwerk erlauben, ein zuvor gefundenes, deutlich größeres Modell, das mit automatischer Architektur-Suche auf vollen 512×512-Bildern trainiert worden war, zu übertreffen. Die Genauigkeit verbesserte sich um über 13 Prozentpunkte, während der Recall — die Fähigkeit, gute Partikel korrekt zu erkennen — um mehr als 18 Prozentpunkte stieg. Die Präzision, die entscheidende Kennzahl zur Vermeidung verschwendeter Messungen an schlechten Partikeln, erreichte etwa 96 Prozent, und die vom Artikel favorisierte kombinierte Leistungsmetrik verbesserte sich ebenfalls.
Mehr erreichen mit viel weniger Daten
Eines der markantesten Ergebnisse ist, dass die Verarbeitung wichtiger ist als die rohe Bildgröße. Als das Team Modelle verglich, die nur einfach verkleinerte Bilder verwendeten, mit solchen, die die komplette maßgeschneiderte Pipeline nutzten, lagen die verarbeiteten Bilder durchweg vorn — selbst wenn sie auf extrem kleine Größen wie 16×16 Pixel geschrumpft wurden. Tatsächlich übertraf das beste Modell mit verarbeiteten 16×16-Bildern das beste Modell mit unverarbeiteten 128×128-Bildern in fast allen Kennzahlen. Die Pipeline half besonders bei geringerer Mikroskopvergrößerung, wo Bilder normalerweise schwerer zu interpretieren sind. Da Bilder bei niedrigerer Vergrößerung schneller aufgenommen werden, können Labore Chips somit zügiger scannen, ohne die Qualität der Entscheidungen zu opfern.
Schnellere Entscheidungen für selbststeuernde Labore
Durch die Kombination aus intelligenter Bildverarbeitung und einem schlanken KI-Modell reduzierten die Autorinnen und Autoren die Trainingszeiten von vielen Stunden auf einem Supercomputer auf unter eine Minute auf einer einzelnen Grafikeinheit. Nach dem Training kann das System ein neues Bild in etwa 75 Millisekunden verarbeiten und klassifizieren — deutlich unter dem Ziel von 500 Millisekunden und viel schneller als ein menschlicher Prüfer. Praktisch bedeutet das eine schnelle, zuverlässige Durchsicht von Nanopartikel-Megalibraries, die Forschende dabei unterstützt, teure Instrumente auf die vielversprechendsten Kandidaten zu konzentrieren. Während Labore in Richtung automatisierter, „selbstfahrender“ Entdeckungssysteme voranschreiten, bieten solche Ansätze — zuerst die Daten säubern, dann vereinfachte KI anwenden — einen kraftvollen Weg, überwältigende Bildströme in verwertbare wissenschaftliche Erkenntnisse zu verwandeln.
Zitation: Day, A.L., Wahl, C.B., dos Reis, R. et al. Image processing pipeline for AI-driven nanoparticle megalibrary characterization. Sci Rep 16, 7675 (2026). https://doi.org/10.1038/s41598-026-37566-z
Schlüsselwörter: Nanopartikel, Bildverarbeitung, maschinelles Lernen, Materialentdeckung, Elektronenmikroskopie