Clear Sky Science · de
Forschung zu Plug-and-Play-Modulen zur Verbesserung von Label-Korrelationen im tiefen Multi-Label-Lernen
Maschinen beibringen, mit zu vielen Labels umzugehen
Online-Shops, Rechtsarchive und medizinische Datenbanken sind auf Software angewiesen, die neue Dokumente schnell mit den passenden Labels versieht. Moderne Systeme stehen jedoch oft vor Zehntausenden oder gar Millionen möglicher Labels – von Produktkategorien bis zu medizinischen Fachbegriffen – während jeder Text nur eine Handvoll davon braucht. Dieses Paper stellt ein neues Zusatzmodul vor, das Label Correlation Enhancement Network (LCENet), das bestehenden Deep‑Learning‑Modellen hilft, die natürlichen Gemeinsamkeiten im Auftreten von Labels besser zu nutzen und so die Textzuordnung genauer und schneller macht.
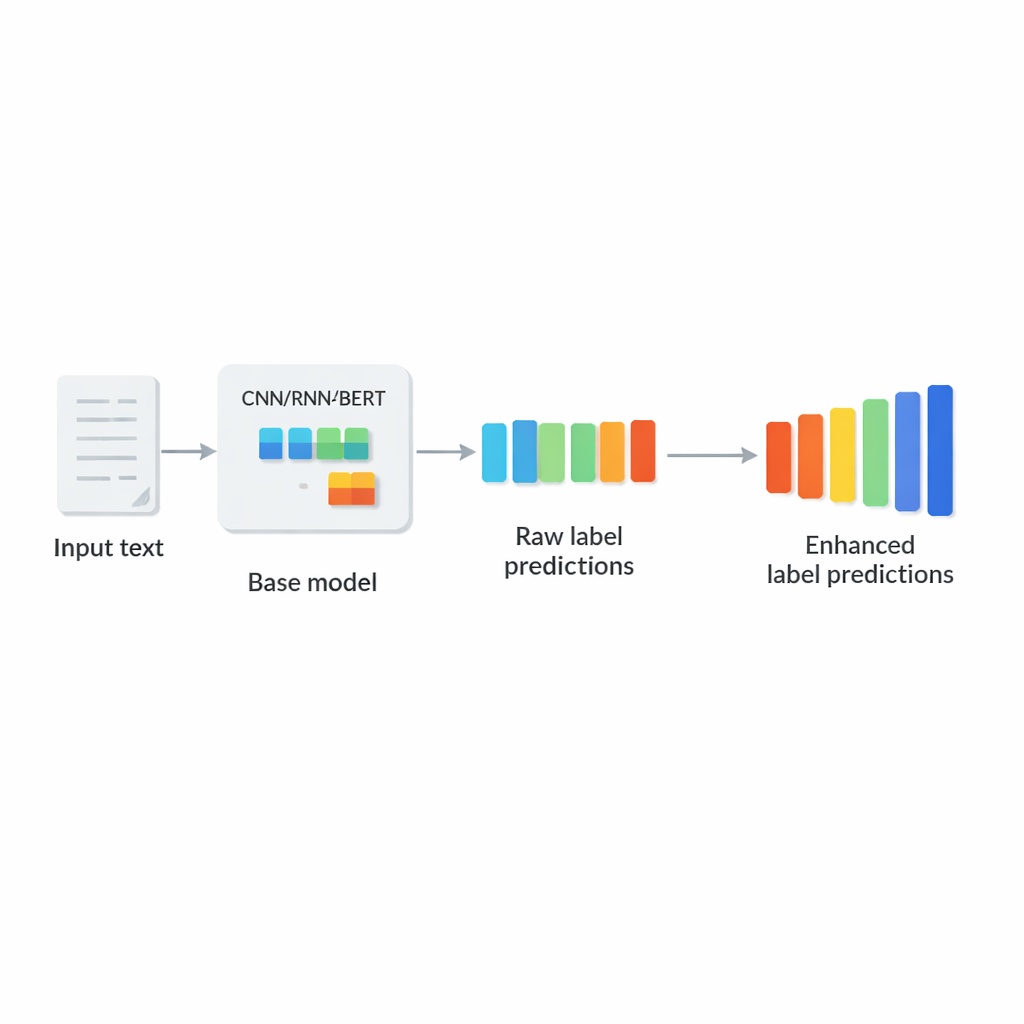
Warum Labeling in großem Maßstab so schwierig ist
Viele reale Anwendungen fallen in das, was Forschende als extreme Multi‑Label‑Textklassifikation bezeichnen: Aus einer kurzen Beschreibung oder langen Dokumenten soll das System eine kleine Teilmenge relevanter Labels aus einem riesigen Katalog auswählen. Beispiele sind die Zuordnung von Kategorien zu Produkten in einem E‑Commerce‑Portal, die Indexierung biomedizinischer Artikel mit MeSH‑Begriffen, das Matching von Anzeigen mit Webseiten oder die Abbildung juristischer Texte auf detaillierte Gesetzescodes. Diese Szenarien teilen drei Herausforderungen: die Label‑Liste ist extrem groß, die meisten Labels sind selten, und in einem Text werden nur wenige Labels verwendet. Traditionelle Verfahren zerlegen das Problem oft in viele kleine Klassifikatoren oder komprimieren Labels in niedrigdimensionale Vektoren, beruhen aber häufig auf einfachen Wortzählungen und können Bedeutung oder Beziehungen zwischen Labels nicht vollständig erfassen.
Was Standard‑Deep‑Modelle weiterhin übersehen
Moderne Deep‑Learning‑Ansätze wie Convolutional‑Netze, rekurrente Netze und Transformer‑basierte Modelle wie BERT haben das Textverständnis durch reichhaltige semantische Repräsentationen stark verbessert. Dennoch machen fast alle von ihnen eine entscheidende Vereinfachung im letzten Schritt: Sobald der Text als Vektor kodiert ist, sagen sie jedes Label unabhängig voraus. In der Praxis interagieren Labels jedoch stark miteinander. Ein medizinischer Artikel, der mit „Diabetes“ gekennzeichnet ist, betrifft eher auch „Insulinresistenz“, und ein Gerät mit dem Label „Smartphone“ hängt meist mit „Elektronik“ und „Kommunikationsgeräte“ zusammen. Werden diese Muster ignoriert, können Modelle hochsichere Labels nicht nutzen, um schwächere zu stützen, und sie können Kombinationen ausgeben, die inhaltlich keinen Sinn ergeben.
Ein Plug‑In, das Label‑Beziehungen lernt
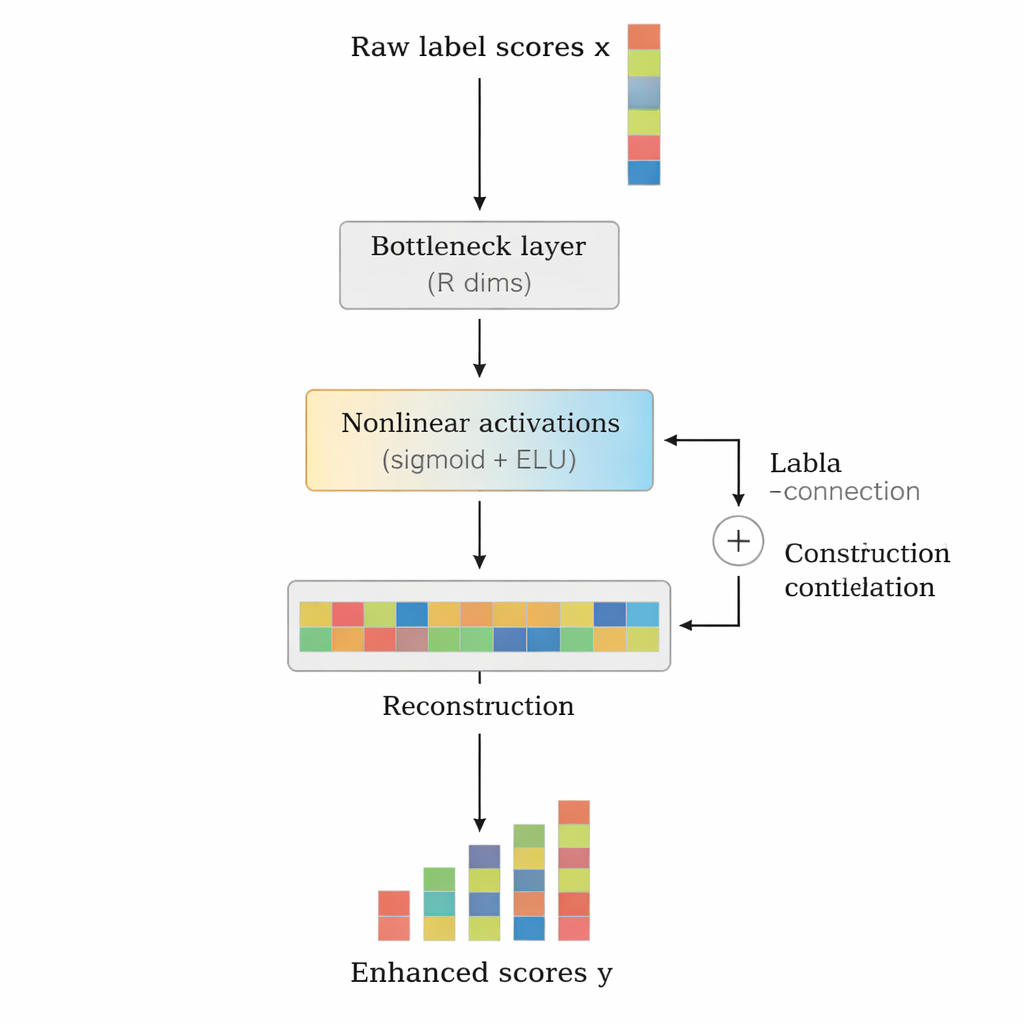
Die Autoren schlagen LCENet als leichtgewichtiges Plug‑and‑Play‑Modul vor, das nach jedem bestehenden tiefen Textklassifikator platziert wird. Anstatt die Art und Weise zu ändern, wie das Basismodell den Text verarbeitet, nimmt LCENet die rohen Label‑Scores, die dieses erzeugt, und leitet sie durch einen kompakten »Bottleneck«, der das System zwingt, eine niedrigdimensionale Darstellung zu entdecken, in der verwandte Labels zusammenclustern. Nichtlineare Aktivierungsfunktionen erlauben dem Modul, komplexe, höherstufige Assoziationen zu erfassen, nicht nur einfache paarweise Verknüpfungen. Eine Residual‑ oder Skip‑Verbindung führt die ursprünglichen Scores parallel zu den korrigierten Scores direkt zum Ausgang, was das Training stabilisiert und sicherstellt, dass das Zusatzmodul die Leistung nicht leicht verschlechtern kann. Entscheidend reduziert LCENet die Anzahl zusätzlicher Parameter von einer Größenordnung, die mit dem Quadrat der Label‑Anzahl wachsen würde, auf ein deutlich handhabbareres lineares Wachstum, sodass es auch bei Hunderttausenden von Labels praktikabel bleibt.
Die Vorteile über Modelle und Datensätze hinweg nachweisen
Um zu prüfen, ob LCENet wirklich allgemein einsetzbar ist, setzten die Autoren es an vier sehr unterschiedliche Deep‑Modelle an, darunter CNN‑ und BERT‑basierte Architekturen sowie Systeme, die speziell für biomedizinische und extreme‑Label‑Szenarien entwickelt wurden. Sie bewerteten diese Kombinationen an drei öffentlichen Benchmark‑Datensätzen: einem europäischen Rechtskorpus (EUR‑Lex), einem Amazon‑Produktdatensatz (AmazonCat‑13K) und einer riesigen Wikipedia‑Sammlung mit über einer halben Million Labels (Wiki‑500K). Über alle Modelle, Datensätze und sechs auf Ranking fokussierte Metriken verbesserte LCENet konsistent die Leistung, in manchen Fällen erhöhte sich die Top‑1‑Präzision um mehr als fünf Prozentpunkte auf dem größten Datensatz. Die Trainingskurven zeigten außerdem, dass LCENet oft die Anzahl der Trainingsschritte, die nötig sind, um eine bestimmte Genauigkeit zu erreichen, nahezu halbiert, weil die hinzugefügte Label‑Korrelationsstruktur von Anfang an klarere Lernsignale liefert.
Warum das für Alltagsanwendungen wichtig ist
Für Anwender, die bereits auf tiefe Modelle zur Textkennzeichnung setzen, bietet LCENet eine praktische Möglichkeit, Genauigkeit und Trainingsgeschwindigkeit zu verbessern, ohne ihre Systeme neu zu entwerfen oder neue Arten von Annotationen zu sammeln. Es betrachtet den Labelraum selbst als Wissensquelle, lernt, welche Tags tendenziell zusammen auftreten oder sich gegenseitig ausschließen, und korrigiert Vorhersagen entsprechend. Obwohl es für Text entwickelt wurde, könnte das gleiche Prinzip, Vorhersagen mithilfe gelernter Beziehungen zwischen Ausgaben zu verbessern, auch auf Bilder, multimodale Daten und andere strukturierte Vorhersageaufgaben angewandt werden. Kurz gesagt hilft LCENet Maschinen, sich daran zu »erinnern«, wie Labels zueinander stehen, sodass sie weniger wie isolierte Checkboxen raten und mehr wie ein sachkundiger Mensch, der versteht, wie Konzepte zusammengehören.
Zitation: Zhang, J., Yuan, C. & Li, X. Research on plug-and-play correlation enhancement modules in deep multi-label learning. Sci Rep 16, 6788 (2026). https://doi.org/10.1038/s41598-026-37565-0
Schlüsselwörter: extreme Multi-Label-Textklassifikation, Label-Korrelation, Deep Learning, Textklassifikation, Neuronale Netze