Clear Sky Science · de
DMSCA: dynamische mehrskalige Kanal-Raum-Aufmerksamkeit zur verbesserten Merkmalsdarstellung in Faltungsneuronalen Netzen
Computern beibringen, besser aufzupassen
Moderne Bilderkennungssysteme können Katzen, Verkehrszeichen und Tumore in Aufnahmen erkennen – aber sie wissen nicht immer, worauf sie innerhalb eines Bildes achten sollten. Dieses Paper stellt eine neue Methode vor, die diesen Systemen hilft, sich auf die wichtigsten Bildbereiche zu konzentrieren, die Genauigkeit zu verbessern und sie in den unordentlichen Bedingungen der realen Welt zuverlässiger zu machen. Die Methode, Dynamic Multi-Scale Channel-Spatial Attention (DMSCA) genannt, lässt sich in bestehende faltungsbasierte neuronale Netze einfügen und hilft ihnen, sowohl das „Was“ als auch das „Wo“ in einem Bild intelligenter zu erfassen.
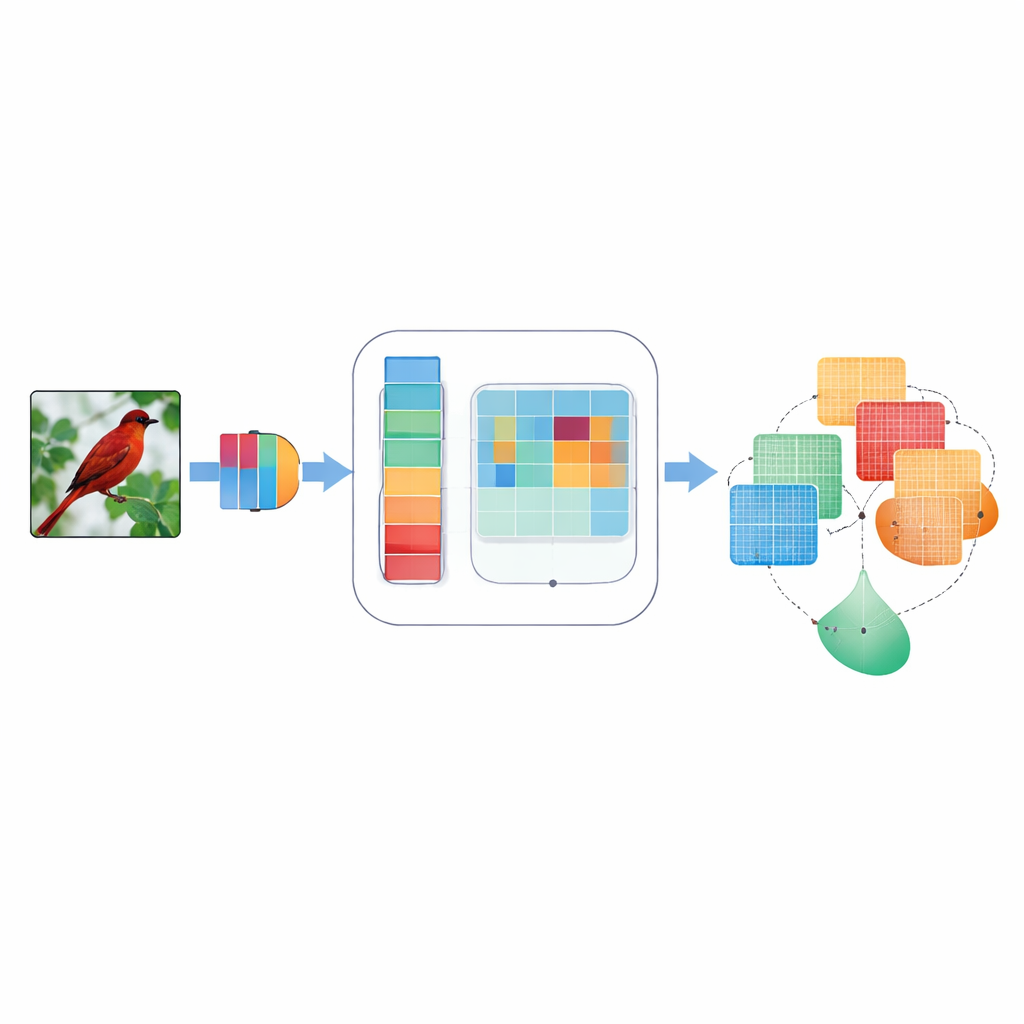
Warum Fokus für maschinelles Sehen wichtig ist
Faltungsneuronale Netze, die Arbeitspferde vieler Vision-Anwendungen, behandeln interne Signale normalerweise als gleich wichtig. Das bedeutet, dass etwa die schwache Kontur eines Vogelflügels und ein Himmelsfleck ähnliche Beachtung finden können, obwohl nur das eine bei der Bestimmung der Art hilft. Frühere "Aufmerksamkeits"-Methoden versuchten, dies zu korrigieren, indem sie einigen internen Signalen mehr Gewicht gaben – entweder über kanallike Merkmale oder über die zweidimensionale Bildanordnung. Diese Methoden verwendeten jedoch oft feste, von Menschen entworfene Regeln, betrachteten nur eine Detailskala zur Zeit oder kombinierten Informationen auf eine starre Weise, die sich nicht an unterschiedliche Bilder anpassen konnte. Dadurch übersahen sie manchmal feine Details, vernachlässigten Richtungen wie "horizontal vs. vertikal" oder hatten Probleme bei verrauschten bzw. verschwommenen Bildern.
Eine intelligentere Aufmerksamkeits‑Erweiterung
DMSCA ist als kleines, ansteckbares Modul konzipiert, das in bekannte Netze wie ResNet eingefügt werden kann, ohne deren Gesamtstruktur zu verändern. Im Inneren koordiniert es sechs eng verknüpfte Teile, die zusammenarbeiten statt isoliert zu wirken. Ein Teil fasst das gesamte Bild zusammen, um globale Informationen zu erfassen, während ein anderer lernt, wie stark jeder interne Kanal gewichtet werden sollte, wobei eine steuerbare „Temperatur“ Entscheidungen schärfer oder weicher machen kann. Auf der räumlichen Seite nutzt DMSCA mehrere Fenstergrößen gleichzeitig, um sowohl feine Texturen als auch größere Formen zu erfassen, und berücksichtigt explizit horizontale und vertikale Richtungen, damit lange Kanten oder Streifen nicht verwischt werden. Schließlich lernt das Modul, an jedem Pixel zu entscheiden, wie sehr den Kanal‑basierten "Was"-Informationen gegenüber den räumlichen "Wo"-Informationen zu vertrauen ist, anstatt diese Signale einfach zu addieren.
Bilder in vielen Skalen und Richtungen betrachten
Um zu bestimmen, wo im Bild hingeschaut werden sollte, komprimiert DMSCA zunächst die vielen internen Kanäle zu einer kompakten zweilagigen Karte, die sowohl Hintergrundtrends als auch markante Merkmale hervorhebt. Diese Karte wird dann durch mehrere parallele Filter unterschiedlicher Größe geleitet. Kleine Filter erfassen feine Details wie Fell oder Federn, größere nehmen Formen wie ganze Köpfe oder Körper wahr. Parallel dazu scannt eine Richtungseinheit getrennt entlang von Zeilen und Spalten, wodurch die genaue Position wichtiger Strukturen erhalten bleibt. Diese horizontalen und vertikalen Ansichten dürfen dann miteinander interagieren, sodass ein starkes vertikales Signal beispielsweise die passenden horizontalen Positionen verstärken kann. Das Ergebnis ist eine reichhaltige Aufmerksamkeitskarte, die dem Netzwerk nicht nur sagt, dass etwas wichtig ist, sondern auch wo es liegt und in welcher Skala.
Dem Netzwerk überlassen, was am wichtigsten ist
Da unterschiedliche Bildbereiche unterschiedliche Strategien erfordern können, legt DMSCA kein festes Rezept zur Kombination von Kanal‑ und Rauminformationen fest. Stattdessen baut es ein kleines "Tor" auf, das beides prüft und – unabhängig für jedes Pixel – entscheidet, wie viel Gewicht jeder Informationsart zu gegebenen ist. In einem unruhigen Hintergrund kann das System stärker auf hervorstechende Kanäle setzen, während es an klaren Objektkanten räumliche Hinweise betont. Eine abschließende adaptive Aktivierungsstufe wirkt dann wie ein gelernten Dimmer: Sie verstärkt wirklich informative Regionen und dämpft verbleibendes Rauschen. Dieser mehrstufige Prozess lenkt die Aufmerksamkeit des Netzes auf kohärente, objektbezogene Bereiche, wie visuelle Heatmaps und quantitative Messungen zeigen, die belegen, wie gut die hervorgehobenen Bereiche mit den Ground‑Truth‑Objekten übereinstimmen.
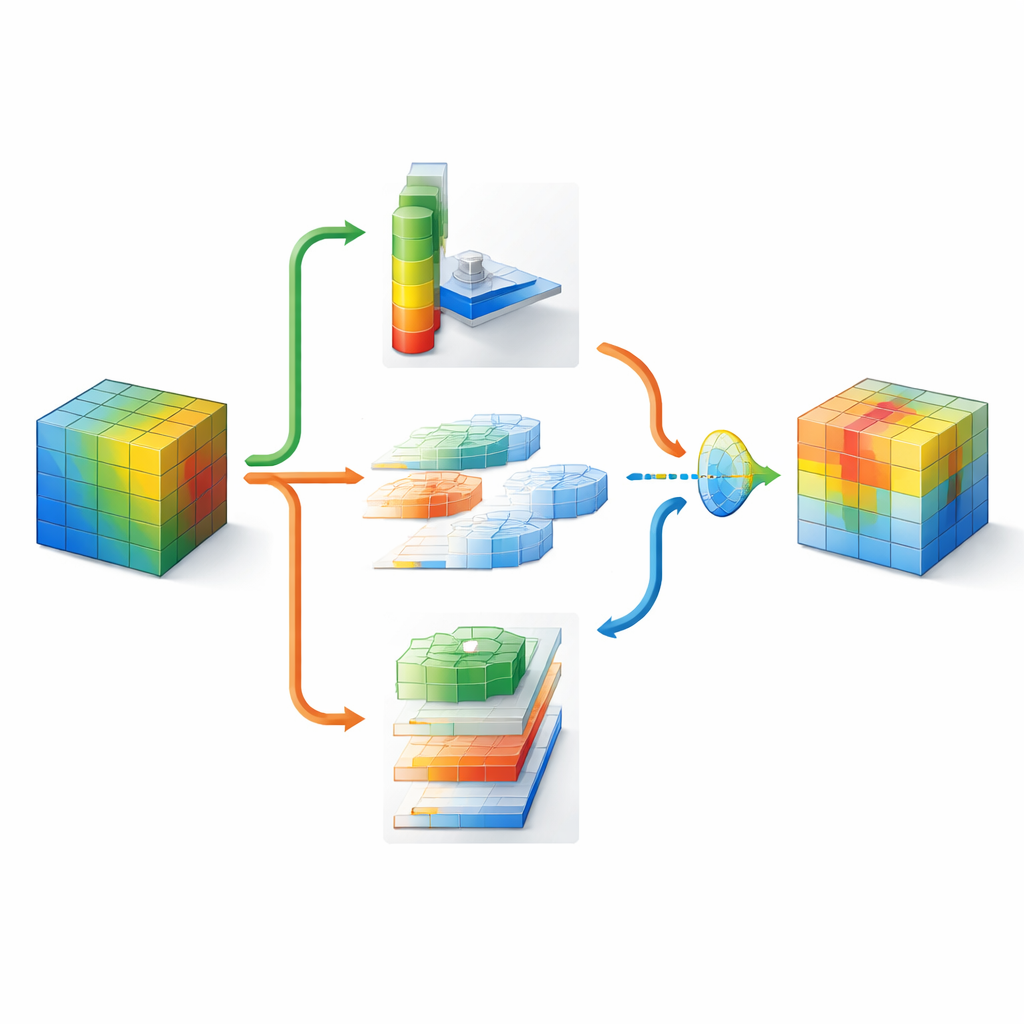
Scharferes Sehen mit überschaubarem Mehraufwand
Die Autoren testeten DMSCA auf mehreren Standardbenchmarks, von kleinen Sammlungen winziger Bilder bis zum großskaligen ImageNet‑Datensatz. Eingefügt in gängige ResNet‑Modelle verbesserte DMSCA durchgängig die Klassifikationsgenauigkeit – um bis zu etwa 2 Prozentpunkte auf kleinen Datensätzen und 1,5 Prozentpunkte auf ImageNet – und übertraf damit eine Reihe bestehender Aufmerksamkeitsmethoden. Es machte die Modelle auch robuster gegenüber typischen Bildverschlechterungen wie Rauschen, Unschärfe und starker Kompression und verbesserte die Leistung bei verwandten Aufgaben wie Objekterkennung und Szenenbeschriftung. Diese Zugewinne gingen nur mit einem moderaten Anstieg von Rechen‑ und Speicheraufwand einher. Einfach ausgedrückt gibt DMSCA Faltungsnetzwerken eine flexiblere und kontextbewusstere Möglichkeit, zu entscheiden, worauf sie achten und was sie ignorieren sollten, und rückt das maschinelle Sehen einen Schritt näher an die selektive Fokussierung des menschlichen Blicks.
Zitation: Zong, L., Nan, S.J., Die, Z.F. et al. DMSCA: dynamic multi-scale channel-spatial attention for enhanced feature representation in convolutional neural networks. Sci Rep 16, 8044 (2026). https://doi.org/10.1038/s41598-026-37546-3
Schlüsselwörter: Aufmerksamkeitsmechanismen, Bilderkennung, Faltungsneuronale Netze, Merkmalsdarstellung, robuste Computervision