Clear Sky Science · de
Verbesserung der cross-modal Retrieval durch Optimierung des Label-Graphen und hybride Verlustfunktionen
Intelligenter suchen zwischen Bildern und Worten
Täglich scrollen wir durch Meere von Fotos, Videos und Texten. Genau das zu finden, was wir wollen – etwa alle Bilder, die zu einer kurzen Beschriftung passen – hängt davon ab, wie gut Computer Bilder mit Sprache verknüpfen können. Dieses Papier untersucht eine neue Methode, diese Verbindung genauer zu machen, insbesondere in unordentlichen, realen Szenen, in denen viele Ideen und Objekte gleichzeitig vorkommen. Das Ergebnis sind intelligentere Suchwerkzeuge, die besser „verstehen“, was wir meinen, und nicht nur, was wir eingeben.
Warum mehrere Bedeutungen in einem Bild zählen
Ein einzelnes Bild zeigt selten nur eine Sache. Ein Foto eines Wals, der aus dem Meer springt, umfasst zugleich Ozean, Himmel, Wellen, Wind und Tierwelt. Beim Taggen eines solchen Bildes hängen wir oft mehrere Labels an, die in subtiler Weise miteinander verbunden sind. Bestehende Suchsysteme behandeln diese Labels meist wie voneinander unabhängige Kontrollkästchen. Diese Vereinfachung wirft nützliche Hinweise weg: Wenn „Wal" häufig mit „Meer" auftritt, sollte das Auftreten des einen die Wahrscheinlichkeit des anderen erhöhen. Diese Arbeit konzentriert sich darauf, jene verborgenen Verbindungen zwischen Labels einzufangen, sodass eine Suche nach einem Begriff auch Bilder und Texte finden kann, die eng verwandte Konzepte ausdrücken.

Ein Netz verbundener Labels aufbauen
Die Autoren stellen eine Technik vor, die Two-Layer Graph Convolutional Network oder L2-GCN genannt wird, um zu modellieren, wie Labels zueinander in Beziehung stehen. Einfach ausgedrückt wird jedes Label (wie „Himmel" oder „Wal") als Punkt in einem Netzwerk behandelt, und Linien zwischen Punkten spiegeln wider, wie häufig diese Labels gemeinsam auftreten. Die Methode lässt jedes Label wiederholt auf seine Nachbarn „hören“ und kombiniert Informationen verwandter Labels, wobei die eigene Identität erhalten bleibt. Nach diesem Prozess entstehen reichere Label-Beschreibungen, die besser erfassen, wie reale Szenen strukturiert sind, von parallelen Ideen („Meer" und „Strand") bis zu hierarchischeren Beziehungen („Tier" und „Wal").
Bilder und Texte lehren, einen gemeinsamen Raum zu teilen
Labels sind natürlich nur die halbe Geschichte; das System muss auch aus den Bildern und Texten selbst lernen. Der Rahmen nutzt etablierte Werkzeuge, um rohe Pixel und Wörter in numerische Merkmale zu überführen, und projiziert dann beide Datentypen in einen gemeinsamen Raum, in dem ihre Bedeutungen direkt vergleichbar sind. Ein adversarielles Modul – lose inspiriert von dem Geben und Nehmen generativer adversarialer Netzwerke – verhindert, dass das Modell an Eigenheiten von Bildern oder Texten allein kleben bleibt. Das hilft dem gemeinsamen Raum, sich auf den Inhalt statt das Format zu konzentrieren, sodass ein Foto einer belebten Straße und eine kurze Bildbeschreibung in dieser gemeinsamen Bedeutungslandkarte nahe beieinander liegen.
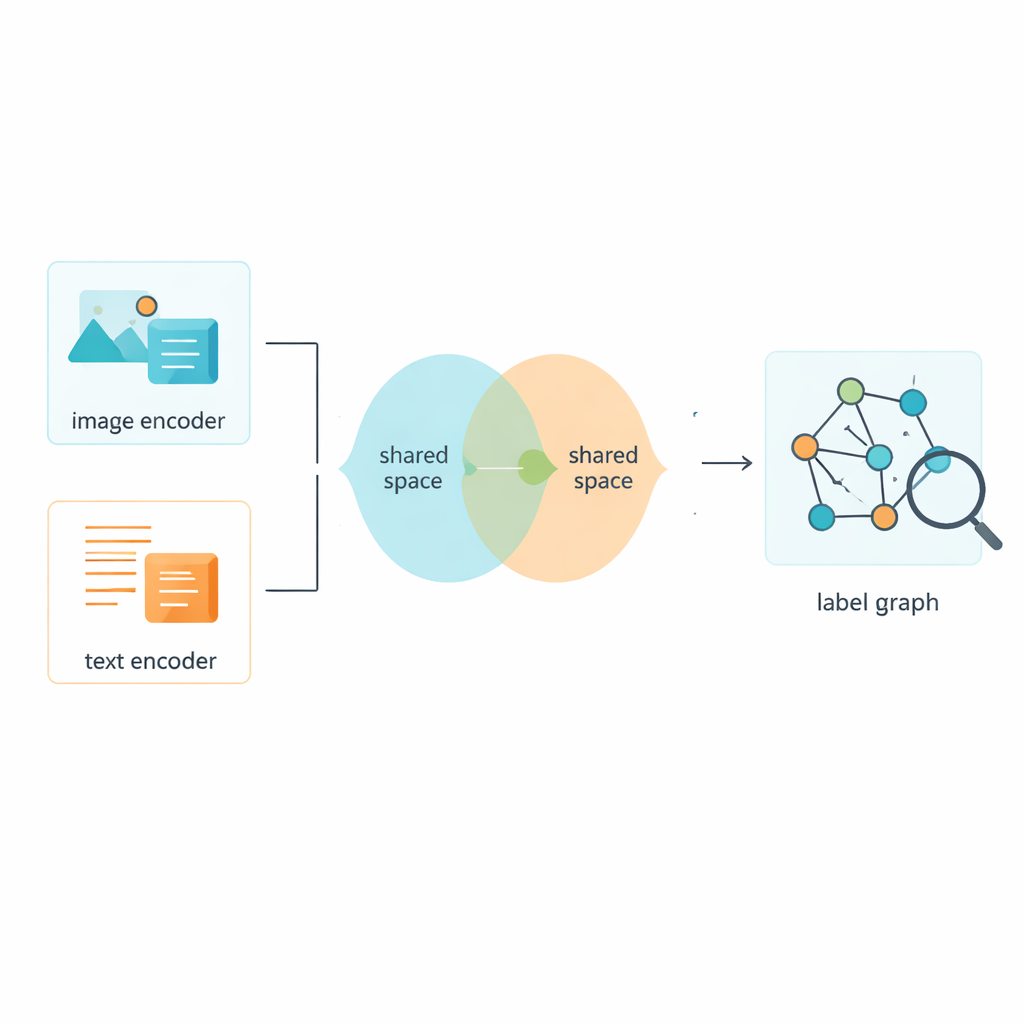
Eine hybride Trainingsstrategie für schärfere Unterscheidungen
Das Training eines solchen Systems erfordert mehr als eine Lernregel. Die Autoren entwerfen eine kombinierte Verlustfunktion, genannt Circle-Soft, die zwei komplementäre Ideen verbindet. Ein Teil sorgt dafür, dass Beispiele derselben Kategorie eng zusammenrücken, während verschiedene Kategorien flexibel auseinander gehalten werden. Der andere Teil konzentriert sich darauf, wie gut Bilder und Texte, die dieselbe Szene beschreiben, über Formate hinweg ausgerichtet sind. Ein einstellbares Gewicht balanciert diese beiden Ziele, damit das Modell nicht entweder zu starren Kategorien oder ausschließlich zur cross-modal Ausrichtung überfitten kann. Zusätzliche Klassifikations- und adversarielle Verluste fördern weiter die Konsistenz zwischen den verfeinerten Labels und den gemeinsamen Bild–Text-Merkmalen.
Wie viel besser wird die Suche dadurch?
Um zu prüfen, ob sich diese Ideen in bessere Suche übersetzen, testeten die Autoren ihre Methode auf drei verbreiteten Sammlungen realer Bild–Text-Paare: MIRFlickr, NUS-WIDE und MS-COCO. Diese Datensätze enthalten von Tausenden bis zu Hunderttausenden Fotos mit zugehörigen Tags oder Beschriftungen und decken Alltagsszenen von Stadtstraßen bis zur Tierwelt ab. In allen drei Benchmarks übertraf der neue Ansatz konsistent eine breite Palette konkurrierender Methoden, einschließlich anderer fortgeschrittener Systeme, die bereits graphbasierte Label-Modellierung verwenden. Die Gewinne – rund ein halbes bis ein volles Prozentpunkt bei einer strengen Retrieval-Metrik – mögen klein klingen, aber in etablierten Benchmarks deuten selbst kleine Verbesserungen auf ein präziseres Inhaltsverständnis hin. Praktisch bedeutet das: Wenn ein Nutzer eine kurze Textanfrage stellt oder ein Bild hochlädt, ist das System eher in der Lage, die relevantesten cross-modalen Treffer oben in den Ergebnissen anzuzeigen.
Was das für alltägliche Nutzer bedeutet
Für Nicht‑Spezialisten ist die Kernbotschaft, dass ein intelligenterer Umgang mit Labels und Trainingsregeln spürbar verbessern kann, wie Maschinen Bilder und Worte verknüpfen. Indem Labels als vernetztes Geflecht statt als isolierte Tags behandelt und sorgfältig gestaltet wird, wie visuelle und textuelle Informationen in einem gemeinsamen Raum aufeinandertreffen, macht dieses Framework die cross-modale Suche in komplexen, thematisch gemischten Szenen zuverlässiger. Mit der Zeit könnten Techniken wie diese intuitivere Fotobibliotheken, Medienplattformen und intelligente Assistenten ermöglichen, die finden, was wir meinen – selbst wenn unsere Worte nicht perfekt zu den Bildern passen, die wir im Kopf haben.
Zitation: Wang, L., Wang, C. & Peng, S. Enhancing cross-modal retrieval via label graph optimization and hybrid loss functions. Sci Rep 16, 6400 (2026). https://doi.org/10.1038/s41598-026-37525-8
Schlüsselwörter: Bild-Text-Retrieval, multimodale Suche, graphneuronale Netze, semantische Labels, maschinelles Lernen