Clear Sky Science · de
Verbesserung der Darstellung medizinischen Wissens in großen Sprachmodellen durch Optimierung klinischer Token
Warum klügeres medizinisches Lesen wichtig ist
Hinter jedem medizinischen KI-Assistenten steht eine einfache, aber wichtige Fähigkeit: wie er Text in handhabbare Stücke zerlegt. Führt dieses "Zerschneiden" schief — insbesondere bei komplexen chinesischen medizinischen Begriffen —, kann die KI wichtige Hinweise in Arztberichten oder Patientenfragen übersehen. Diese Arbeit zeigt, wie eine kleine, gezielte Veränderung dieses ersten Schritts große Sprachmodelle dabei unterstützen kann, chinesische medizinische Daten besser zu lesen, zu durchdenken und Fragen dazu zu beantworten, ohne ein völlig neues System von Grund auf neu zu entwickeln.
Text auf die richtige Weise in Stücke teilen
Moderne Sprachmodelle lesen Zeichen oder Wörter nicht direkt; sie wandeln Text zuerst in kurze Einheiten um, sogenannte Tokens. Für Englisch funktioniert das recht gut, weil Leerzeichen Wortgrenzen markieren. Chinesisch ist schwieriger: Es gibt keine Leerzeichen, und viele medizinische Ausdrücke sind lange, spezialisierte Wortfolgen. Standard-Tokenizer, die vorwiegend für Englisch entwickelt wurden, neigen dazu, diese Ausdrücke in viele willkürliche Fragmente zu zerlegen. Wenn ein Modell einen Krankheitsnamen oder einen Laborbefund in mehrere getrennte Teile zerschlitzt sieht, fällt es ihm schwerer zu lernen, was dieser Begriff tatsächlich bedeutet, und seine Antworten auf medizinische Fragen können vage oder ungenau werden.
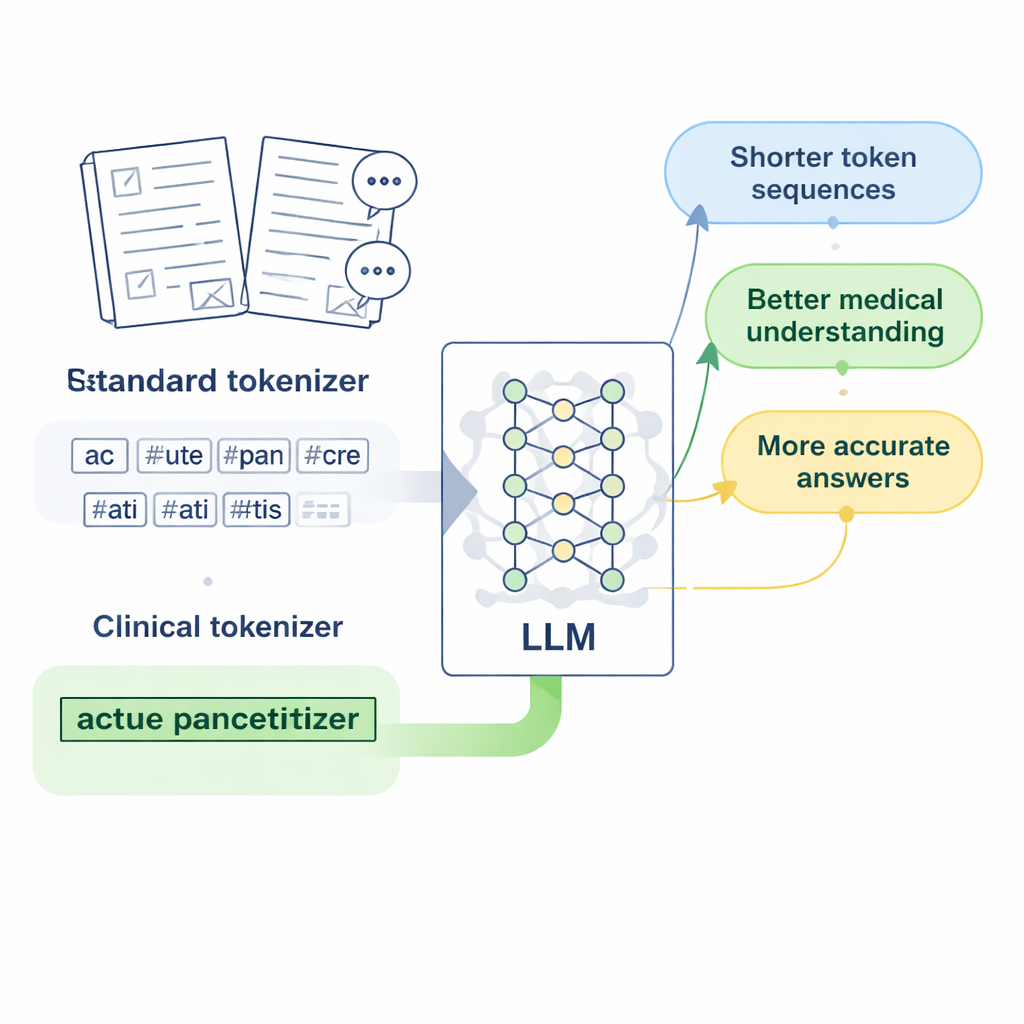
Entwurf von „klinischen Tokens" für die chinesische Medizin
Die Forschenden konzentrieren sich auf LLaMA2, ein populäres Open-Source-Großmodell, und fragen: Was, wenn man seinem Tokenizer einfach einen reicheren medizinischen Wortschatz beibringt? Sie sammeln große Mengen chinesischer medizinischer Texte, darunter sorgfältig bearbeitete Datenbanken der traditionellen chinesischen Medizin, tausende klinische Aufzeichnungen und Arzt–Patient-Frage-Antwort-Paare. Mit einer bytebasierten Version des Byte Pair Encoding-Algorithmus, implementiert über das Tool SentencePiece, trainieren sie einen neuen Tokenizer, der lernt, gängige medizinische Ausdrücke als zusammenhängende Einheiten zu belassen. Diese neuen Einheiten, die die Autorinnen und Autoren „klinische Tokens" nennen, werden dann in das ursprüngliche Vokabular von LLaMA2 integriert und erweitern es, sodass chinesische medizinische Sprache besser abgedeckt ist, ohne das bereits Gelernte zu verwerfen.
Von besseren Tokens zu einem besseren medizinischen Modell
Neue Tokens hinzuzufügen ist nur der erste Schritt; das Modell muss gute Repräsentationen für sie lernen. Das Team passt die interne Einbettungsschicht (Embedding-Layer) von LLaMA2 so an, dass sie Vektoren für das erweiterte Vokabular speichern kann, und testet zwei Möglichkeiten, diese neuen Vektoren zu initialisieren. Eine Methode bildet den Durchschnitt der Vektoren älterer Unterteile jedes Wortes, die andere verwendet sorgfältig skalierte Zufallswerte. Entgegen der Intuition schneidet die Zufallsmethode besser ab, vermutlich weil sie vermeidet, das Modell auf eine schlechte Anfangsschätzung für die Bedeutung jedes Begriffs festzulegen. Die Autorinnen und Autoren trainieren das Modell anschließend weiter an medizinischen Texten und feinabstimmen es auf instruktionale medizinische Q&A mittels einer ressourceneffizienten Methode namens LoRA, wodurch eine spezialisierte Version entsteht, die sie Medical-LLaMA nennen.
Messung von Verbesserungen in Geschwindigkeit, Kontext und Genauigkeit
Mit dem erweiterten Vokabular benötigt jedes chinesische Zeichen nun etwa halb so viele Tokens wie zuvor, was bedeutet, dass das Modell längere Textpassagen im gleichen festen Tokenfenster verarbeiten kann. Praktisch verdoppelt sich die effektiv nutzbare chinesische Kontextlänge grob, und die Feinabstimmungszeit an einer großen medizinischen Q&A-Sammlung verringert sich nahezu um die Hälfte. Zur Beurteilung der Antwortqualität kombinieren die Autorinnen und Autoren zwei Evaluationsstrategien: BERTScore, das misst, wie semantisch nah eine erzeugte Antwort an einer Referenz liegt, und ein anspruchsvolles Bewertungsmodell (DeepSeek-R1), das Relevanz, Genauigkeit, Vollständigkeit und Sprachfluss bewertet. Über diese Maße hinweg übertrifft Medical-LLaMA durchgehend sowohl das ursprüngliche LLaMA2 als auch eine chinesisch-optimierte Variante, die keine medizinisch spezifischen Tokens enthielt. Es zeigt außerdem leichte, aber beständige Verbesserungen bei verwandten Aufgaben wie der Erkennung medizinischer Entitäten und der Klassifikation klinischer Texte, und das alles, ohne die Leistung bei allgemeinen, nicht-medizinischen Fragen zu beeinträchtigen.
Was das für die zukünftige medizinische KI bedeutet
Für Nicht-Spezialisten ist die Kernbotschaft: Klügere "Lesebrillen" für KI — hier eine bessere Art, medizinische Sprache zu zerteilen — können deutlich verbessern, wie gut sie Gesundheitsfragen versteht und beantwortet. Durch das Einfügen wohlgewählter klinischer Tokens in das Vokabular eines bestehenden Modells steigern die Autorinnen und Autoren sowohl Effizienz als auch Genauigkeit, ohne riesige neue Trainingsläufe oder völlig neue Architekturen zu benötigen. Obwohl die Arbeit auf ein 7‑Milliarden‑Parameter‑Modell und chinesische medizinische Texte beschränkt ist, liefert sie ein praktisches Rezept: das früheste Verarbeitungsniveau der Sprache an die Domäne anpassen und anschließend leicht nachtrainieren. Diese Strategie könnte zukünftigen medizinischen KI‑Werkzeugen helfen, verlässlichere Partner für Kliniker und Patienten zu werden, besonders in Sprachen und Fachgebieten, in denen Standardmodelle beim Lesen Schwierigkeiten haben.
Zitation: Li, Q., Tong, J., Liu, S. et al. Medical knowledge representation enhancement in large language models through clinical tokens optimization. Sci Rep 16, 6563 (2026). https://doi.org/10.1038/s41598-026-37438-6
Schlüsselwörter: medizinische Sprachmodelle, chinesischer klinischer Text, Tokenisierung, klinischer Wortschatz, medizinische Fragebeantwortung